Transformer模型---encoder
一、简介
论文链接:《Attention is all you need》
由google团队在2017年发表于NIPS,Transformer 是一种新的、基于 attention 机制来实现的特征提取器,可用于代替 CNN 和 RNN 来提取序列的特征。 在该论文中 Transformer 用于 encoder - decoder 架构。事实上 Transformer 可以单独应用于 encoder 或者单独应用于 decoder 。
Transformer = 编码器 + 解码器
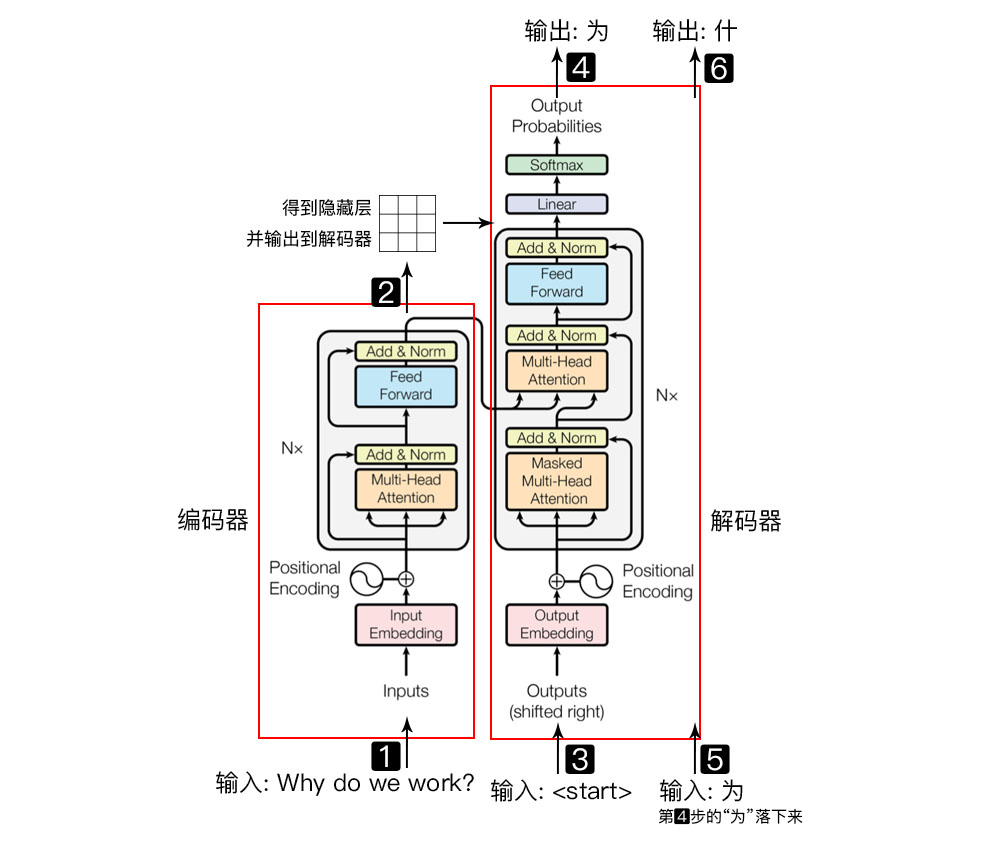
- 输入自然语言序列到编码器: Why do we work?(为什么要工作);
- 编码器输出的隐藏层, 再输入到解码器;
- 输入$<start>$(起始)符号到解码器;
- 得到第一个字"为";
- 将得到的第一个字"为"落下来再输入到解码器;
- 得到第二个字"什";
- 将得到的第二字再落下来, 直到解码器输出$<end>$(终止符), 即序列生成完成.
Transformer相比较LSTM等循环神经网络模型的优点:
- 可以直接捕获序列中的长距离依赖关系;
- 模型并行度高,使得训练时间大幅度降低。
二、编码器
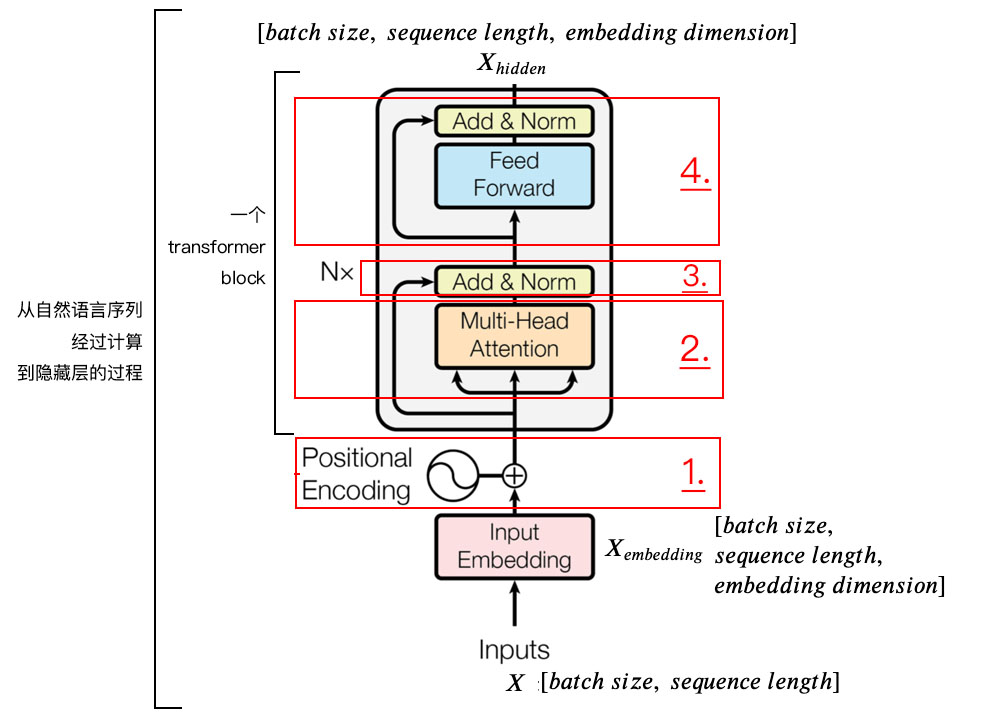
整体结构:
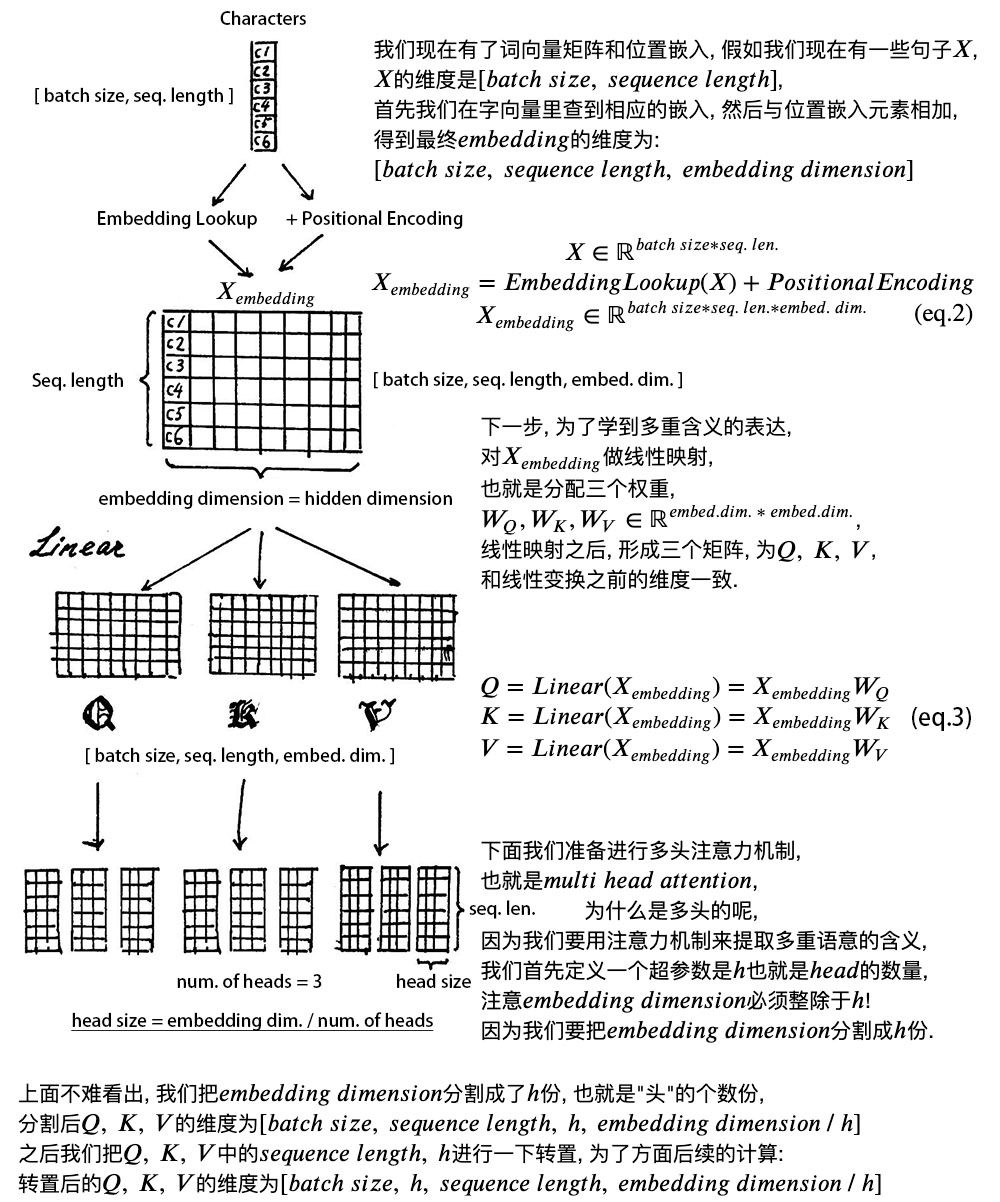
1) 字向量与位置编码:
$X = EmbeddingLookup(X) + PositionalEncoding$
$X \in \mathbb{R}^{batch \ size \ * \ seq. \ len. \ * \ embed. \ dim.} $
2) 自注意力机制:
$Q = Linear(X) = XW_{Q}$
$K = Linear(X) = XW_{K}$
$V = Linear(X) = XW_{V}$
$X_{attention} = SelfAttention(Q, \ K, \ V)$
3) 残差连接与Layer Normalization
$X_{attention} = X + X_{attention}$
$X_{attention} = LayerNorm(X_{attention})$
4) $FeedForward$, 其实就是两层线性映射并用激活函数激活, 比如说$ReLU$:
$X_{hidden} = Activate(Linear(Linear(X_{attention})))$
5) 重复3):
$X_{hidden} = X_{attention} + X_{hidden}$
$X_{hidden} = LayerNorm(X_{hidden})$
$X_{hidden} \in \mathbb{R}^{batch \ size \ * \ seq. \ len. \ * \ embed. \ dim.} $
1.positional encoding位置嵌入(或位置编码)
由于transformer模型没有循环神经网络的迭代操作, 所以我们必须提供每个字的位置信息给transformer, 才能识别出语言中的顺序关系.
现在定义一个位置嵌入的概念, 也就是positional encoding, 位置嵌入的维度为[max sequence length, embedding dimension], 嵌入的维度同词向量的维度, max sequence length属于超参数, 指的是限定的最大单个句长.
注意, 我们一般以字为单位训练transformer模型, 也就是说我们不用分词了, 首先我们要初始化字向量为[vocab size, embedding dimension], vocab size为总共的字库数量, embedding dimension为字向量的维度, 也是每个字的数学表达.
在这里论文中使用了$sine$和$cosine$函数的线性变换来提供给模型位置信息:
$$PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{/text{model}}})$$
$$PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{\text{model}}})$$
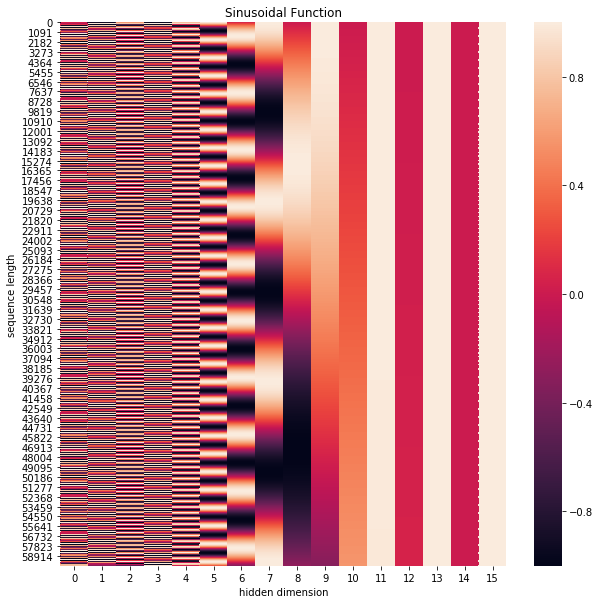
上式中$pos$指的是句中字的位置, 取值范围是[0, max sequence length), i指的是词向量的维度, 取值范围是[0, embedding dimension), 上面有$sin$和$cos$一组公式, 也就是对应着embedding dimension维度的一组奇数和偶数的序号的维度, 例如0, 1一组, 2, 3一组, 分别用上面的$sin$和$cos$函数做处理, 从而产生不同的周期性变化, 而位置嵌入在embedding dimension维度上随着维度序号增大, 周期变化会越来越慢, 而产生一种包含位置信息的纹理, 就像论文原文中第六页讲的, 位置嵌入函数的周期从$2 \pi$到$10000 * 2 \pi$变化, 而每一个位置在embedding dimension维度上都会得到不同周期的$sin$和$cos$函数的取值组合, 从而产生独一的纹理位置信息, 模型从而学到位置之间的依赖关系和自然语言的时序特性.
下面画一下位置嵌入, 可见纵向观察, 随着embedding dimension增大, 位置嵌入函数呈现不同的周期变化.
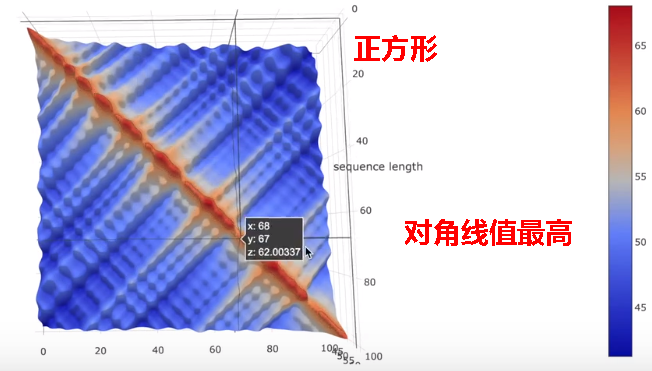
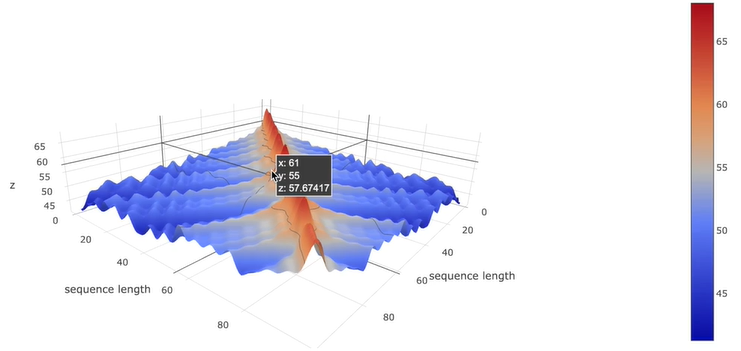
注意力矩阵的三维图如下:
字自己本身乘以自己值最高,自己周围的值也很高,随着与当前字的距离越远,相关程度逐渐降低。
2. self attention mechanism自注意力机制
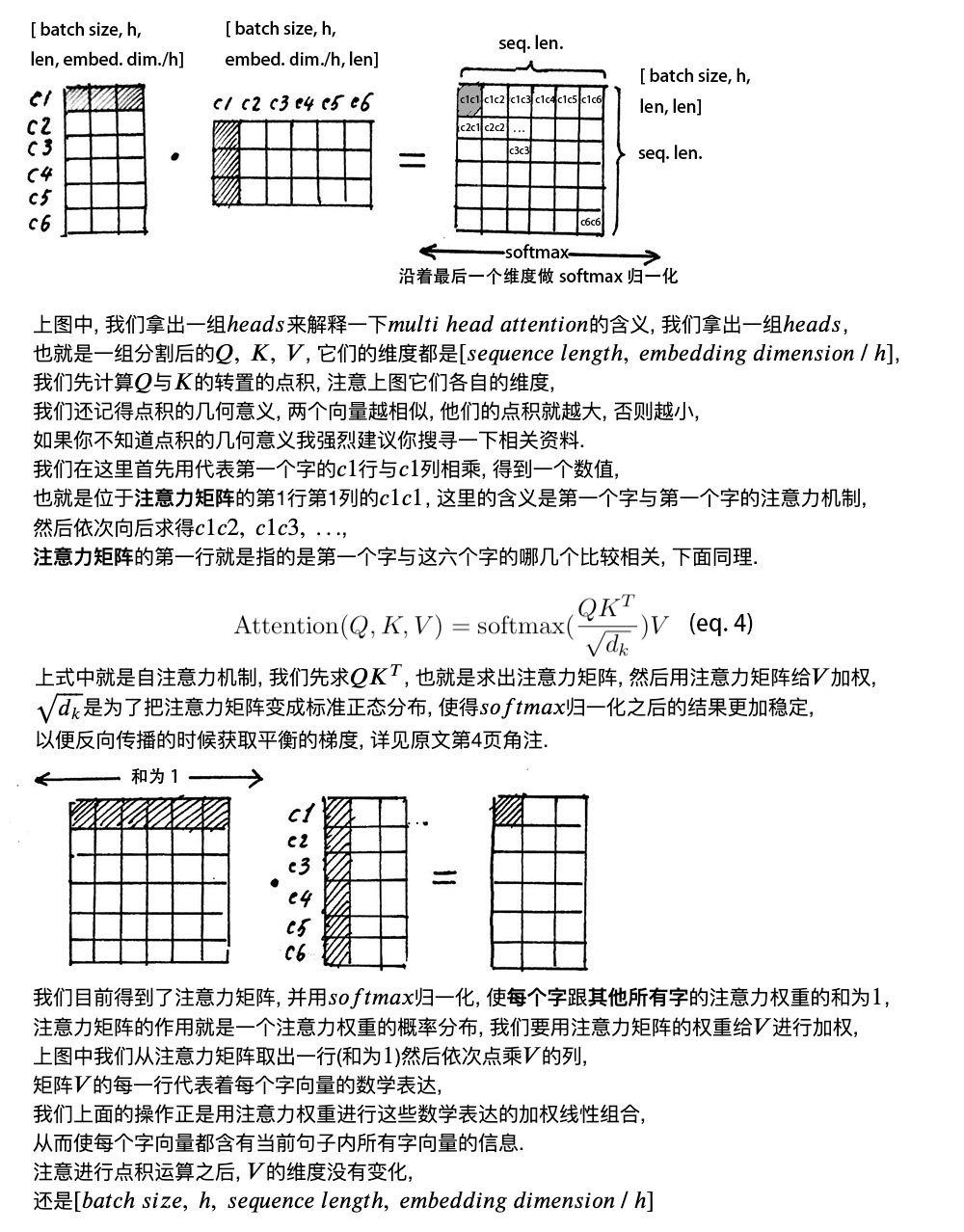
Attention Mask
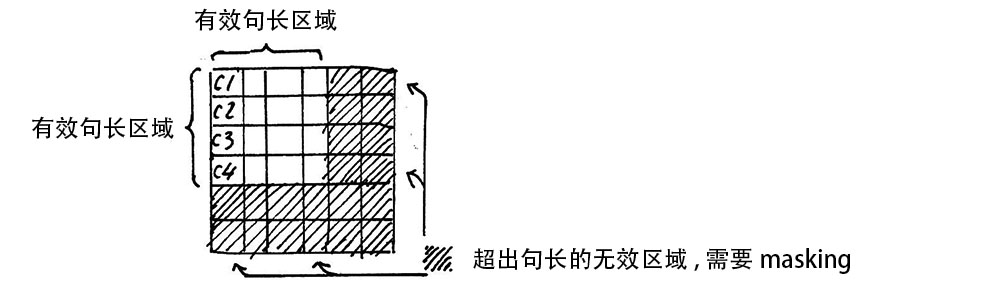
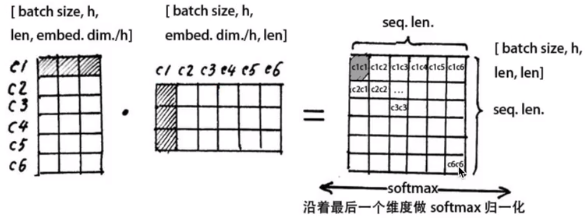
注意, 在上面self attention的计算过程中, 我们通常使用mini batch来计算, 也就是一次计算多句话, 也就是X的维度是[batch size, sequence length], sequence length是句长, 而一个mini batch是由多个不等长的句子组成的, 我们就需要按照这个mini batch中最大的句长对剩余的句子进行补齐长度, 我们一般用0来进行填充, 这个过程叫做padding.
但这时在进行softmax的时候就会产生问题, 回顾softmax函数$\sigma (\mathbf {z} )_{i}={\frac {e^{z_{i}}}{\sum _{j=1}^{K}e^{z_{j}}}}$, $e^0$是1, 是有值的, 这样的话softmax中被padding的部分就参与了运算, 就等于是让无效的部分参与了运算, 会产生很大隐患, 这时就需要做一个mask让这些无效区域不参与运算, 我们一般给无效区域加一个很大的负数的偏置, 也就是:
$z_{illegal} = z_{illegal} + bias_{illegal}$
$bias_{illegal} \to -\infty$
$e^{z_{illegal}} \to 0 $
经过上式的masking我们使无效区域经过softmax计算之后还几乎为0, 这样就避免了无效区域参与计算.
3. 残差连接和Layer Normalization
(1)残差连接
我们在上一步得到了经过注意力矩阵加权之后的$V$, 也就是$Attention(Q, K, V)$, 我们对它进行一下转置, 使其和$X_{embedding}$的维度一致, 也就是[batch size, sequence length, embedding dimension], 然后把他们加起来做残差连接, 直接进行元素相加, 因为他们的维度一致:
$X_{embedding} + Attention(Q, \ K, \ V)$
在之后的运算里, 每经过一个模块的运算, 都要把运算之前的值和运算之后的值相加, 从而得到残差连接, 训练的时候可以使梯度直接走捷径反传到最初始层:
$X + SubLayer(X)$
(2)layer normalization
$Layer Normalization$的作用是把神经网络中隐藏层归一为标准正态分布, 也就是$i.i.d$独立同分布, 以起到加快训练速度, 加速收敛的作用:
$\mu_{i}=\frac{1}{m} \sum^{m}_{i=1}x_{ij}$
上式中以矩阵的行$(row)$为单位求均值;
$\sigma^{2}_{j}=\frac{1}{m} \sum^{m}_{i=1}(x_{ij}-\mu_{j})^{2}$
上式中以矩阵的行$(row)$为单位求方差;
$LayerNorm(x)=\alpha \odot \frac{x_{ij}-\mu_{i}}{\sqrt{\sigma^{2}_{i}+\epsilon}} + \beta$
然后用每一行的每一个元素减去这行的均值, 再除以这行的标准差, 从而得到归一化后的数值, $\epsilon$是为了防止除0;
之后引入两个可训练参数$\alpha, \beta$来弥补归一化的过程中损失掉的信息, 注意$\odot$表示元素相乘而不是点积, 我们一般初始化$\alpha$为全1, 而$\beta$为全0
参考文献:
【1】大师级的a_journey_into_math_of_ml / 04_transformer_tutorial_2nd_part·浓缩咖啡/浓咖啡/ a_journey_into_math_of_ml
【2】The Illustrated Transformer(可视化讲解)
【3】The Annotated Transformer(代码讲解)
Transformer模型---encoder的更多相关文章
- Transformer模型---decoder
一.结构 1.编码器 Transformer模型---encoder - nxf_rabbit75 - 博客园 2.解码器 (1)第一个子层也是一个多头自注意力multi-head self-atte ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 详解Transformer模型(Atention is all you need)
1 概述 在介绍Transformer模型之前,先来回顾Encoder-Decoder中的Attention.其实质上就是Encoder中隐层输出的加权和,公式如下: 将Attention机制从Enc ...
- transformer模型解读
最近在关注谷歌发布关于BERT模型,它是以Transformer的双向编码器表示.顺便回顾了<Attention is all you need>这篇文章主要讲解Transformer编码 ...
- transformer模型简介
Transformer模型由<Attention is All You Need>提出,有一个完整的Encoder-Decoder框架,其主要由attention(注意力)机制构成.论文地 ...
- Transformer模型总结
Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行. 它是由编码组件.解码组件和它们之间的连接组成. 编码组件部分由一堆编码器(6个 enco ...
- NLP与深度学习(四)Transformer模型
1. Transformer模型 在Attention机制被提出后的第3年,2017年又有一篇影响力巨大的论文由Google提出,它就是著名的Attention Is All You Need[1]. ...
- Transformer模型详解
2013年----word Embedding 2017年----Transformer 2018年----ELMo.Transformer-decoder.GPT-1.BERT 2019年----T ...
- RealFormer: 残差式 Attention 层的Transformer 模型
原创作者 | 疯狂的Max 01 背景及动机 Transformer是目前NLP预训练模型的基础模型框架,对Transformer模型结构的改进是当前NLP领域主流的研究方向. Transformer ...
随机推荐
- 【cf1046】A. AI robots(动态开点线段树)
传送门 题意: 坐标轴上有\(n\)个机器人,每个机器人带有属性\(x,r,q\),分别表示位置.可视半径以及智商. 现在定义智商相近为两个机器人的智商差的绝对值不超过$K. 现在问有多少对机器人,他 ...
- Tensorflow加载预训练模型和保存模型(ckpt文件)以及迁移学习finetuning
转载自:https://blog.csdn.net/huachao1001/article/details/78501928 使用tensorflow过程中,训练结束后我们需要用到模型文件.有时候,我 ...
- 数组去重--ES6方法
数组去重方法1:用es6的set和...扩展运算符 let arr = [1,2,3,4,4,5,2]; console.log([...new Set(arr)]) // [1, 2, 3, 4, ...
- 从应用到内核,分析top命令显示的进程名包含中括号"[]"的含义
背景 在执行top/ps命令的时候,在COMMAND一列,我们会发现,有些进程名被[]括起来了,例如 PID PPID USER STAT VSZ %VSZ %CPU COMMAND 1542 928 ...
- Kafka界面管理工具-kafkamanager
在上一篇文章<Linux安装Kafka>中,已经介绍了如何在Linux安装Kafka,以及Kafka的启动/关闭和创建发话题并产生消息和消费消息.这篇文章就介绍介绍Kafka管理界面(ka ...
- Python中的passed by assignment与.NET中的passing by reference、passing by value
Python文档中有一段话: Remember that arguments are passed by assignment in Python. Since assignment just cre ...
- JVM内存溢出分析java.lang.OutOfMemoryError: Java heap space
JVM内存溢出查询java.lang.OutOfMemoryError: Java heap space查出具体原因分为几个预备步骤 1.在运行java程序是必须设置jvm -XX:+HeapDump ...
- Jar 打包与执行
Java学习笔记之一,用于个人记录.整理自<Head First Java>. 假设有如下目录结构: 程序入口在 Jukebox8.java.这个代码文件开头是有如下这样的包声明语句的: ...
- Jenkins配置LDAP认证
managerdn即为连接到AD的账号
- .Net网站防盗链
一.简单写法,在Global.asax下的这个方法中添加如下信息 /// <summary> /// 管道当中的第一个事件 /// </summary> /// <par ...