zz扔掉anchor!真正的CenterNet——Objects as Points论文解读


扔掉anchor!真正的CenterNet——Objects as Points论文解读

关注他
等 188 人赞同了该文章
前言
anchor-free目标检测属于anchor-free系列的目标检测,相比于CornerNet做出了改进,使得检测速度和精度相比于one-stage和two-stage的框架都有不小的提高,尤其是与YOLOv3作比较,在相同速度的条件下,CenterNet的精度比YOLOv3提高了4个左右的点。
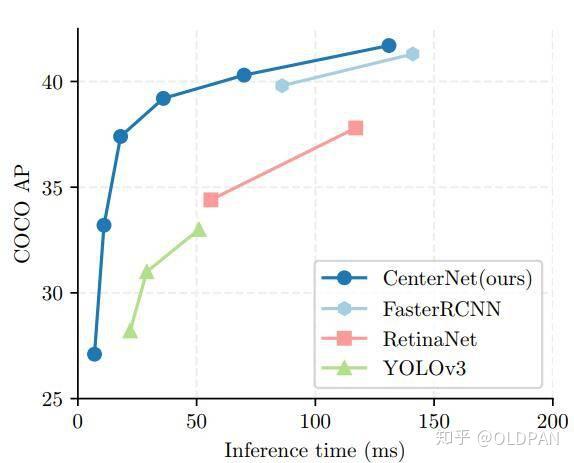
CenterNet不仅可以用于目标检测,还可以用于其他的一些任务,如肢体识别或者3D目标检测等等,但是这篇文章我们就重点说的是其对目标检测的部分。

那CenterNet相比于之前的one-stage和two-stage的目标检测有什么特点?
- CenterNet的“anchor”仅仅会出现在当前目标的位置处而不是整张图上撒,所以也没有所谓的box overlap大于多少多少的算positive anchor这一说,也不需要区分这个anchor是物体还是背景 - 因为每个目标只对应一个“anchor”,这个anchor是从heatmap中提取出来的,所以不需要NMS再进行来筛选
- CenterNet的输出分辨率的下采样因子是4,比起其他的目标检测框架算是比较小的(Mask-Rcnn最小为16、SSD为最小为16)。
总体来说,CenterNet结构优雅简单,直接检测目标的中心点和大小,是真anchor-free。
PS:其实本篇所说的CenterNet的真实论文名称叫做objects as points,因为也有一篇叫做CenterNet: Keypoint Triplets for Object Detection的论文与这篇文章的网络名称冲突了,所以以下所说的CenterNet是指objects as points。
总之这是一篇值得一读的好文!
网络结构与前提条件
接下来说一下正式进入篇章之前的一些前提知识。
使用的网络
论文中CenterNet提到了三种用于目标检测的网络,这三种网络都是编码解码(encoder-decoder)的结构:
- Resnet-18 with up-convolutional layers : 28.1% coco and 142 FPS
- DLA-34 : 37.4% COCOAP and 52 FPS
- Hourglass-104 : 45.1% COCOAP and 1.4 FPS
每个网络内部的结构不同,但是在模型的最后都是加了三个网络构造来输出预测值,默认是80个类、2个预测的中心点坐标、2个中心点的偏置。
用官方的源码(使用Pytorch)来表示一下最后三层,其中hm为heatmap、wh为对应中心点的width和height、reg为偏置量,这些值在后文中会有讲述。
(hm): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1))
)
(wh): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
(reg): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)前提条件
附一张检测的效果图:
我们该如何检测呢?
首先假设输入图像为 ,其中
和
分别为图像的宽和高,然后在预测的时候,我们要产生出关键点的热点图(keypoint heatmap):
,其中
为输出对应原图的步长,而
是在目标检测中对应着检测点的数量,如在COCO目标检测任务中,这个
的值为80,代表当前有80个类别。
插一段官方代码,其中 就是self.opt.down_ratio也就是4,代表下采样的因子。
# 其中input_h和input_w为512,而self.opt.down_ratio为4,最终的output_h为128
# self.opt.down_ratio就是上述的R即输出对应原图的步长
output_h = input_h // self.opt.down_ratio
output_w = input_w // self.opt.down_ratio这样, 就是一个检测到物体的预测值,对于
,表示对于类别
,在当前
坐标中检测到了这种类别的物体,而
则表示当前当前这个坐标点不存在类别为
的物体。
在整个训练的流程中,CenterNet学习了CornerNet的方法。对于每个标签图(ground truth)中的某一 类,我们要将真实关键点(true keypoint)
计算出来用于训练,中心点的计算方式为
,对于下采样后的坐标,我们设为
,其中
是上文中提到的下采样因子4。所以我们最终计算出来的中心点是对应低分辨率的中心点。
然后我们利用 来对图像进行标记,在下采样的[128,128]图像中将ground truth point以
的形式,用一个高斯核
来将关键点分布到特征图上,其中
是一个与目标大小(也就是w和h)相关的标准差。如果某一个类的两个高斯分布发生了重叠,直接去元素间最大的就可以。
这么说可能不是很好理解,那么直接看一个官方源码中生成的一个高斯分布[9,9]:

每个点 的范围是0-1,而1则代表这个目标的中心点,也就是我们要预测要学习的点。
损失函数
重点看一下中心点预测的损失函数,原始论文中因为篇幅关系将第二个otherwise的公式挤一块了,这里我们展平看一下就比较清爽:
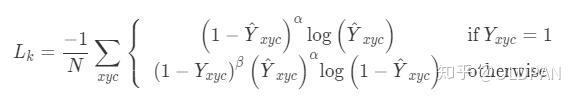
其中 和
是Focal Loss的超参数,
是图像
的的关键点数量,用于将所有的positive focal loss标准化为1。在这篇论文中
和
分别是2和4。这个损失函数是Focal Loss的修改版,适用于CenterNet。
这个损失也比较关键,需要重点说一下。和Focal Loss类似,对于easy example的中心点,适当减少其训练比重也就是loss值,当 的时候,
就充当了矫正的作用,假如
接近1的话,说明这个是一个比较容易检测出来的点,那么
就相应比较低了。而当
接近0的时候,说明这个中心点还没有学习到,所以要加大其训练的比重,因此
就会很大,
是超参数,这里取2。
 高斯生成的中心点
高斯生成的中心点
再说下另一种情况,当 的时候,这里对实际中心点的其他近邻点的训练比重(loss)也进行了调整,首先可以看到
,因为当
的时候
的预测值理应是0,如果不为0的且越来越接近1的话,
的值就会变大从而使这个损失的训练比重也加大;而
则对中心点周围的,和中心点靠得越近的点也做出了调整(因为与实际中心点靠的越近的点可能会影响干扰到实际中心点,造成误检测),因为
在上文中已经提到,是一个高斯核生成的中心点,在中心点
,但是在中心点周围扩散
会由1慢慢变小但是并不是直接为0,类似于上图,因此
,与中心点距离越近,
越接近1,这个值越小,相反则越大。那么
和
是怎么协同工作的呢?
简单分为几种情况:
- 对于距离实际中心点近的点,
值接近1,例如
,但是预测出来这个点的值
比较接近1,这个显然是不对的,它应该检测到为0,因此用
惩罚一下,使其LOSS比重加大些;但是因为这个检测到的点距离实际的中心点很近了,检测到的
接近1也情有可原,那么我们就同情一下,用
来安慰下,使其LOSS比重减少些。
- 对于距离实际中心点远的点,
,如果预测出来这个点的值
- 如果结合上面两种情况,那就是:
和
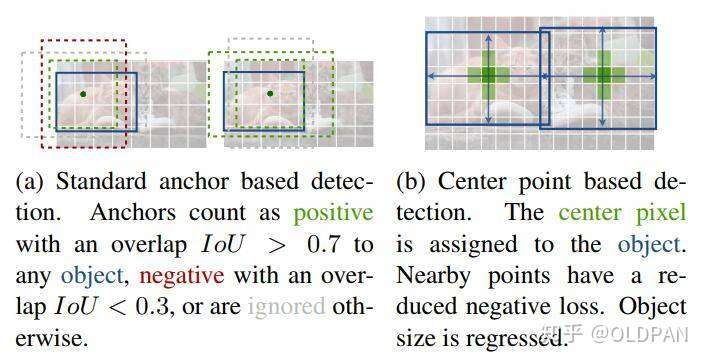
另外看一下官方的这张图可能有助于理解:传统的基于anchor的检测方法,通常选择与标记框IoU大于0.7的作为positive,相反,IoU小于0.3的则标记为negative,如下图a。这样设定好box之后,在训练过程中使positive和negative的box比例为1:3来减少negative box的比例(例如SSD没有使用focal loss)。
而在CenterNet中,每个中心点对应一个目标的位置,不需要进行overlap的判断。那么怎么去减少negative center pointer的比例呢?CenterNet是采用Focal Loss的思想,在实际训练中,中心点的周围其他点(negative center pointer)的损失则是经过衰减后的损失(上文提到的),而目标的长和宽是经过对应当前中心点的w和h回归得到的:
目标中心的偏置损失
因为上文中对图像进行了 的下采样,这样的特征图重新映射到原始图像上的时候会带来精度误差,因此对于每一个中心点,额外采用了一个
local offset: 去补偿它。所有类
的中心点共享同一个
offset prediction,这个偏置值(offset)用L1 loss来训练:
上述公式直接看可能不是特别容易懂,其实 是原始图像经过下采样得到的,对于[512,512]的图像如果
的话那么下采样后就是[128,128]的图像,下采样之后对标签图像用高斯分布来在图像上撒热点,怎么撒呢?首先将box坐标也转化为与[128,128]大小图像匹配的形式,但是因为我们原始的
annotation是浮点数的形式(COCO数据集),使用转化后的box计算出来的中心点也是浮点型的,假设计算出来的中心点是[98.97667,2.3566666]。
但是在推断过程中,我们首先读入图像[640,320],然后变形成[512,512],然后下采样4倍成[128,128]。最终预测使用的图像大小是[128,128],而每个预测出来的热点中心(headmap center),假设我们预测出与实际标记的中心点[98.97667,2.3566666]对应的点是[98,2],坐标是 ,对应的类别是
,等同于这个点上
,有物体存在,但是我们标记出的点是[98,2],直接映射为[512,512]的形式肯定会有精度损失,为了解决这个就引入了
偏置损失。
这个式子中 是我们预测出来的偏置,而
则是在训练过程中提前计算出来的数值,在官方代码中为:
# ct 即 center point reg是偏置回归数组,存放每个中心店的偏置值 k是当前图中第k个目标
reg[k] = ct - ct_int
# 实际例子为
# [98.97667 2.3566666] - [98 2] = [0.97667, 0.3566666]reg[k]之后与预测出来的reg一并放入损失函数中进行计算。注意上述仅仅是对某一个关键点位置 来计算的,计算当前这个点的损失值的时候其余点都是被忽略掉的。
到了这里我们可以发现,这个偏置损失是可选的,我们不使用它也可以,只不过精度会下降一些。
目标大小的损失
我们假设 为目标
,所属类别为
,它的中心点为
。我们使用关键点预测
去预测所有的中心点。然后对每个目标
的size进行回归,最终回归到
,这个值是在训练前提前计算出来的,是进行了下采样之后的长宽值。
为了减少回归的难度,这里使用 作为预测值,使用L1损失函数,与之前的
损失一样:
整体的损失函数为物体损失、大小损失与偏置损失的和,每个损失都有相应的权重。
在论文中 ,然后
,论文中所使用的backbone都有三个head layer,分别产生[1,80,128,128]、[1,2,128,128]、[1,2,128,128],也就是每个坐标点产生
个数据,分别是类别以及、长宽、以及偏置。
推断阶段
在预测阶段,首先针对一张图像进行下采样,随后对下采样后的图像进行预测,对于每个类在下采样的特征图中预测中心点,然后将输出图中的每个类的热点单独地提取出来。具体怎么提取呢?就是检测当前热点的值是否比周围的八个近邻点(八方位)都大(或者等于),然后取100个这样的点,采用的方式是一个3x3的MaxPool,类似于anchor-based检测中nms的效果。
这里假设 为检测到的点,
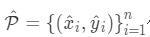
代表 类中检测到的一个点。每个关键点的位置用整型坐标表示
,然后使用
表示当前点的confidence,随后使用坐标来产生标定框:
其中
是当前点对应原始图像的偏置点,
代表预测出来当前点对应目标的长宽。
下图展示网络模型预测出来的中心点、中心点偏置以及该点对应目标的长宽:

那最终是怎么选择的,最终是根据模型预测出来的 值,也就是当前中心点存在物体的概率值,代码中设置的阈值为0.3,也就是从上面选出的100个结果中调出大于该阈值的中心点作为最终的结果。
例子
运行官方源码的demo,随便挑了一张图,跑出来的结果分别对应最终图,取top=100的检测图以及预测出来的heatmap。
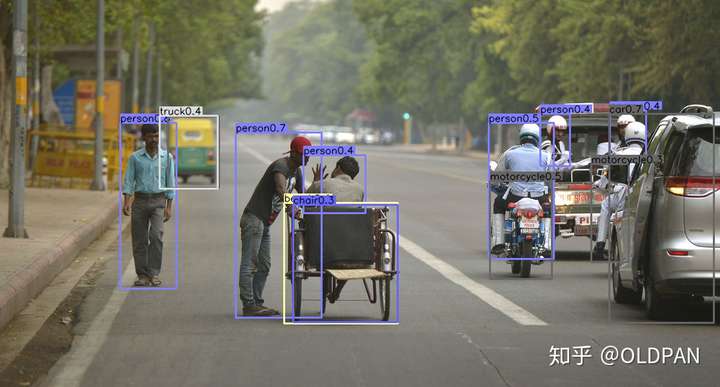 最终效果图
最终效果图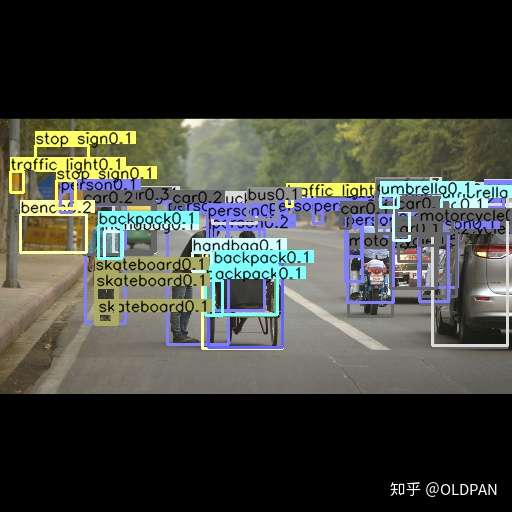 top=100的检测图
top=100的检测图 预测出来的heatmap
预测出来的heatmap
后记
总之这是一篇笔记,好久没有认真阅读一篇论文了。搞工程搞多了看见论文就头大,但是好的论文还是值得一读了,特别是这一篇。这篇论文厉害的地方在于:
- 设计模型的结构比较简单,像我这么头脑愚笨的人也可以轻松看明白,不仅对于two-stage,对于one-stage的目标检测算法来说该网络的模型设计也是优雅简单的。
- 该模型的思想不仅可以用于目标检测,还可以用于3D检测和人体姿态识别,虽然论文中没有是深入探讨这个,但是可以说明这个网络的设计还是很好的,我们可以借助这个框架去做一些其他的任务。
- 虽然目前尚未尝试轻量级的模型(这是我接下来要做的!),但是可以猜到这个模型对于嵌入式端这种算力比较小的平台还是很有优势的,希望大家多多尝试一些新的backbone(不知道mobilenetv3+CenterNet会是什么样的效果),测试一下,欢迎和我交流呀~
当然说了一堆优点,CenterNet的缺点也是有的,那就是:
- 在实际训练中,如果在图像中,同一个类别中的某些物体的GT中心点,在下采样时会挤到一块,也就是两个物体在GT中的中心点重叠了,CenterNet对于这种情况也是无能为力的,也就是将这两个物体的当成一个物体来训练(因为只有一个中心点)。同理,在预测过程中,如果两个同类的物体在下采样后的中心点也重叠了,那么CenterNet也是只能检测出一个中心点,不过CenterNet对于这种情况的处理要比faster-rcnn强一些的,具体指标可以查看论文相关部分。
- 有一个需要注意的点,CenterNet在训练过程中,如果同一个类的不同物体的高斯分布点互相有重叠,那么则在重叠的范围内选取较大的高斯点。
好了,说了这么多,最后以这篇论文的Conclusion来结尾吧:

如果文章有错误,欢迎指正,也欢迎小伙伴们与我交流~
收藏
文章被以下专栏收录

推荐阅读
目标检测论文阅读:CornerNet
CornerNet: Detecting Objects as Paired Keypoints 论文链接:https://arxiv.org/abs/1808.01244 代码链接: https://github.com/umich-vl/CornerNet ECCV 2018的paper list已经更新,…

文本检测之PixelLink
RefineDet 论文解读
CVPR2019目标检测方法进展综述
PDF全文链接:CVPR2019目标检测方法进展综述目标检测是很多计算机视觉应用的基础,比如实例分割、人体关键点提取、人脸识别等,它结合了目标分类和定位两个任务。现代大多数目标检测器的框…
37 条评论
发布

王小二3 个月前
作者你好,想和你讨论一个问题,我也是在做端侧的网络训练,所以比较关注一些高效的方案,你文章的末尾也提到了想尝试一些轻量化网络结合centernet的想法。但是从你文章开始的性能对比图来看,在推理时间降低的时候(模型更简单),centernet的性能下降要超过yoloV3的性能下降,从我个人的实验来看似乎也是这样,不知道是因为这种无先验(无Anchor)的方案比较吃网络性能,还是我的训练有误。
赞回复踩举报



eggTargaryen2 个月前
这个lk就是cornernet里的ldet,你这解释有点迷呀
赞回复踩举报
OLDPAN (作者) 回复eggTargaryen2 个月前
嗯?能说具体点吗赞回复踩举报

gakki老公2 个月前
预测是gt box的中心点,不是物体中心点,所以不存在两个物体中心点重叠
赞回复踩举报
刘圳2 个月前
效果这么惊艳吗,那个效果图中被挡的摩托车,人眼都只能通过上面的人来判断有一个摩托车,这也能被检测出来赞回复踩举报

王二的石锅拌饭2 个月前
概率的预测和中心点的预测是一起做的?赞回复踩举报
红色石头2 个月前
你好,请问文章中对目标进行长宽回归的时候为什么不进行归一化处理?normalize the scale,以前的论文都会加log或者其他归一化方式,难道本文方法对目标尺度已经做到很鲁棒了?
赞回复踩举报
红色石头2 个月前
你好,你知道代码中gaussian radius是怎么计算的吗?背后的公式怎么理解?谢谢
赞回复踩举报

许出山2 个月前
我觉得这种算single anchor赞回复踩举报

稳稳2 个月前
作者你好,我想问一下 Y 的范围为什么属于0到1呢
赞回复踩举报
稳稳2 个月前
作者你好,请问这个关键热力图怎么生成的呢,.这个yhat表示什么呢
赞回复踩举报
徐天2 个月前
作者读的不错,赞一个[赞同]赞回复踩举报

饭希Peach2 个月前
亲,训练时计算的中心点p属于R方,每太明白可以解释一下吗?R不是等于4吗?
赞回复踩举报

kkner2 个月前
请问您有预训练模型的百度云链接吗?google下不了
赞回复踩举报

caikw621 个月前
写的好清楚啊,太感谢了。期待你的代码详解呀
 2回复踩举报
2回复踩举报
王康康1 个月前
我想用这个网络检测一下甜甜圈 〇
赞回复踩举报

蜂子18 天前
请问楼主能否转载你的这篇文章呢?谢谢
赞回复踩举报

金峰18 天前
对于像anchor-free这样的检测方法 可不可以尝试着多尺度的去检测
赞回复踩举报

nbb15 天前
我就想知道那个所谓的“与w、h有关的标准差”是怎么计算来的。其实我感觉任意取,只要大于0理论上也可以,但为什么非要这么取。
赞回复踩举报
zz扔掉anchor!真正的CenterNet——Objects as Points论文解读的更多相关文章
- Objects as Points:预测目标中心,无需NMS等后处理操作 | CVPR 2019
论文基于关键点预测网络提出CenterNet算法,将检测目标视为关键点,先找到目标的中心点,然后回归其尺寸.对比上一篇同名的CenterNet算法,本文的算法更简洁且性能足够强大,不需要NMS等后处理 ...
- 【论文阅读】Objects as Points 又名 CenterNet | 目标检测
目录 Abstract Instruction 分析 CenterNet 的Loss公式 第一部分:\(L_k\) 第二部分:\(L_{size}\) 第三部分:\(L_{off}\) Abstrac ...
- CenterNet和CenterNet2笔记
CenterNet和CenterNet2笔记 CenterNet是基于anchor-free的一阶段检测算法 CenterNet2是CenterNet作者基于两阶段的改进 CenterNet(Obje ...
- 目标检测中的anchor-based 和anchor free
目标检测中的anchor-based 和anchor free 1. anchor-free 和 anchor-based 区别 深度学习目标检测通常都被建模成对一些候选区域进行分类和回归的问题.在 ...
- 《anchor-based v.s. anchor-free》
作者:青青子衿链接:https://www.zhihu.com/question/356551927/answer/926659692来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载 ...
- 目标检测复习之Anchor Free系列
目标检测之Anchor Free系列 CenterNet(Object as point) 见之前的过的博客 CenterNet笔记 YOLOX 见之前目标检测复习之YOLO系列总结 YOLOX笔记 ...
- CenterNet
Objects as Points anchor-free系列的目标检测算法,只检测目标中心位置,无需采用NMS 1.主干网络 采用Hourglass Networks [1](还有resnet18 ...
- 经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
前言: 目标检测的预测框经过了滑动窗口.selective search.RPN.anchor based等一系列生成方法的发展,到18年开始,开始流行anchor free系列,CornerNe ...
- anchor_based-anchor_free object detectors
同步到知乎anchor_based-anchor_free object detectors 前言:最近关注了大量目标检测的论文,比较火的就是anchor based和anchor free两类问题: ...
随机推荐
- [LOJ 2083][UOJ 219][BZOJ 4650][NOI 2016]优秀的拆分
[LOJ 2083][UOJ 219][BZOJ 4650][NOI 2016]优秀的拆分 题意 给定一个字符串 \(S\), 求有多少种将 \(S\) 的子串拆分为形如 AABB 的拆分方案 \(| ...
- vue 使用localstorage实现面包屑
mutation.js代码: changeRoute(state, val) { let routeList = state.routeList; let isFind = false; let fi ...
- Ubuntu 安装git及git命令
1.检查git是否已经安装,输入git version命令即可,如果没有显示版本号表示没有安装git 2.安装git sudo apt-get install git 3.配置git全局环境git c ...
- 【08月14日】A股ROE最高排名
个股滚动ROE = 最近4个季度的归母净利润 / ((期初归母净资产 + 期末归母净资产) / 2). 查看更多个股ROE最高排名 兰州民百(SH600738) - ROE_TTM:86.45% - ...
- 关于全局异常(@ControllerAdvice)的学习与思考
一声梧叶一声秋,一点芭蕉一点愁,三更归梦三更后.____徐再思<水仙子·夜雨> 今天的主题是全局异常的构建,处理,以及一些小细节: 至于全局异常的代码构建以及一些常用的异常处理类可以看这篇 ...
- LeetCode 21:合并两个有序链表 Merge Two Sorted Lists
将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. Merge two sorted linked lists and return it as a new ...
- Oracle数据库rownum用法集锦
Oracle中rownum可以用来限制查询 具体用法: 1.返回查询集合中的第1行 select * from tableName where rownum = 1 2.返回查询集合中的第2行 错误示 ...
- linq 大数据 sql 查询及分页优化
前提: 需要nuget PredicateLib 0.0.5: SqlServer 2008R2 (建议安装 64 位): .net 4.5 或以上: 当前电脑配置: I7 4核 3.6G ...
- 一个动态构建 LambdaExpression Tree 的示例
直接贴代码了: public class ExpressionTreeBuildingSampleTwo : Sample { public override string Name { get; } ...
- 【Easyexcel】java导入导出超大数据量的xlsx文件 解决方法
解决方法: 使用easyexcel解决超大数据量的导入导出xlsx文件 easyexcel最大支持行数 1048576. 官网地址: https://alibaba-easyexcel.github. ...