Hive sampling 语法之TABLESAMPLE用法理解
官网关于LanguageManual Sampling的教程,部分截图如下,这里主要分享对TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)子句的理解
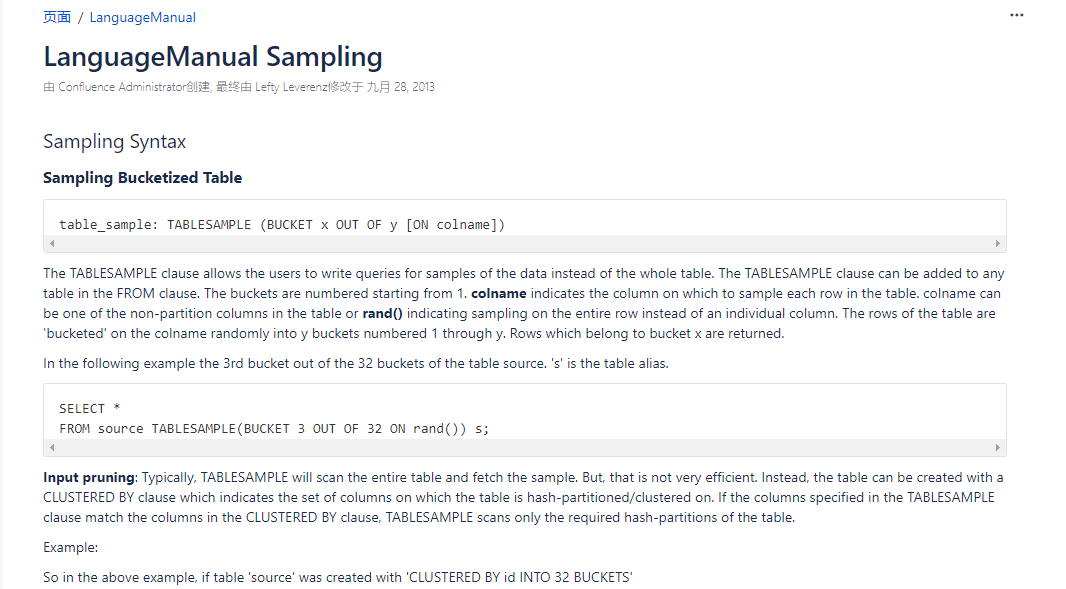
官网中假设创建表时设置了 CLUSTERED BY(id) INTO 32 BUCKETS 即分成了32个文件(虽然这里用的是bucket,为了避免混淆和方便理解下面的解释,个人倾向于用cluster或者叫簇来代替),那么下面这个子句
TABLESAMPLE(BUCKET 3 OUT OF 16 ON id)
在查询中的意思是将cluster分成16个桶,然后取出第三个桶中的数据。32个文件分进16个桶,那就是每个桶有(32/16=)2 个cluster,怎么分呢?第1个cluster分进第1个桶,第2个cluster分进第2个桶......第16个cluster分进第16个桶,第17个cluster分进第1个桶,以此类推。所以当取出第三个桶中的数据时,就会取出第3个簇(cluster)和第19簇(cluster)的数据。官网原话:
would pick out the 3rd and 19th clusters as each bucket would be composed of (32/16)=2 clusters.
那下面这个怎么理解呢?
TABLESAMPLE(BUCKET 3 OUT OF 64 ON id)
32个cluster分进64个桶,然后再抽出第三个桶中的数据。32/64=1/2,每个桶由1/2个cluster组成,同样地,第1个cluster的前一半数据分进第1个桶,后一半数据分进第33个桶,第2个cluster的前一半数据分进第2个桶,后一半数据分进第34个桶,.....第32个cluster的前一半数据分进第32个桶,后一半数据分进第64个桶。所以这个子句会取出第3个桶中的数据,也就是第3个cluster中的前一半数据。官网原话:
would pick out half of the 3rd cluster as each bucket would be composed of (32/64)=1/2 of a cluster.
补充官网关于分桶表的DDL操作
LanguageManual DDL BucketedTables
Hive sampling 语法之TABLESAMPLE用法理解的更多相关文章
- Hive基本语法操练
建表规则如下: CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment ...
- Hive 基本语法操练(三):分区操作和桶操作
(一)分区操作 Hive 的分区通过在创建表时启动 PARTITION BY 实现,用来分区的维度并不是实际数据的某一列,具体分区的标志是由插入内容时给定的.当要查询某一分区的内容时可以采用 WHER ...
- C语言语法笔记 – 高级用法 指针数组 指针的指针 二维数组指针 结构体指针 链表 | IT宅.com
原文:C语言语法笔记 – 高级用法 指针数组 指针的指针 二维数组指针 结构体指针 链表 | IT宅.com C语言语法笔记 – 高级用法 指针数组 指针的指针 二维数组指针 结构体指针 链表 | I ...
- oracle中start with和connect by的用法理解
转自:https://blog.csdn.net/qq_29274091/article/details/72627350 Oracle中start with和connect by 用法理解转自:ht ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- CSS3用法理解
这里只概括了我对CSS3各属性的用法理解.具体每个属性的值,以及例子,看这里 (竟然每篇文章不能低于200字,不能低于200字不能低于200字不能低于200字不能低于200字....请无视)
- HIVE基本语法以及HIVE分区
HIVE小结 HIVE基本语法 HIVE和Mysql十分类似 建表规则 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name da ...
- Hive SQL 语法学习与实践
Hive 介绍 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供 ...
- Hive 基本语法操练(五):Hive 的 JOIN 用法
Hive 的 JOIN 用法 hive只支持等连接,外连接,左半连接.hive不支持非相等的join条件(通过其他方式实现,如left outer join),因为它很难在map/reduce中实现这 ...
随机推荐
- [转] QML PinchArea
本文转自安老师的博文:Qt Quick 事件处理之捏拉缩放与旋转 绪论 本文介绍在Android 等智能手机上的一个非常重要的手势:捏拉手势. 捏拉手势最早在苹果手机上得到应用,苹果还曾经尝试为此操作 ...
- APS系统如何落地?用户实际痛点解析!
APS软件在中国的发展,在很长的时间内处于非常尴尬的状态:大企业都了解APS很重要,但只有非常少的企业肯真正实施APS软件,处于叫好不叫座的状态.直到工业4.0概念流行后,APS才逐渐被国内企业所认可 ...
- 一个标准sql语句模板
select distinct top n * from t1 inner join t2 on ... join t3 on ... where ... group by ... having .. ...
- windows,linux里的hosts文件
在解析主机名的IP地址时,会先访问本机的上hosts文件,这样先配置好就可以不通过DNS服务器就获得IP地址. linux vi /etc/hosts IP 空格 主机名 windows C:\Wi ...
- Odoo报表的report标签和报表格式定义
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/10826329.html 一:Report标签 report标签可用于定义一条报表记录.属性有: 1) ...
- HDU 1240 Asteroids! 题解
Asteroids! Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total ...
- Jupyter notebook 添加或删除内核
1.切换到要添加的虚拟环境,确认是否安装 ipykernel python -m ipykernel --version 如果没有安装,则安装: python -m pip install ipyke ...
- jupyter配置成coding神器
参考链接: [1]http://resuly.me/2017/11/03/jupyter-config-for-windows/ [2]主题更换 切换主题:jt 主题名 -T 主题种类:chester ...
- django模板中的extends和include使用方法
一.extends使用方法 首先extends也就是继承,子类继承父类的一些特性.在django模板中通过继承可以减少重复代码. 首先我们建立一个app,名字叫做hello.别忘了在settings. ...
- 使用ftp搭建yum仓库
此次操作在VMware Workstation虚拟机的CentOS7.5下进行 这里使用两台Linux主机,下表是它们所使用的操作系统以及IP地址. 两台Linux主机所使用的操作系统以及IP地址 操 ...