(基因功能 & 基因表达调控)研究方案
做了好久的RNA-seq分析,基因表达也在口头溜了几年了,但似乎老是浮在表面。
对一件事的了解程度决定了你的思维深度,只想做技工就不用想太多,想做大师就一定要刨根问底。
老是说基因表达,那么什么是基因表达?我们测序得到的基因表达其实只是一种表型,是样本的一个快照,和普通的身高体重之类的连续型表型类似。
常规的转录组分析本质上都是表型分析,clustering、pseudotime、DEG、marker,在这些分析中,每个基因都是独立的维度,属于静态的分析,此时我们关注的是某个基因的功能分析,比如RET,功能已经明确,那就可以用基因表达这个表型来解释另一个表型。
高通量测序还会有后续的分析,几万个基因不可能一个一个的研究,GO和KEGG分析就来了,基因不是互相独立的,GO term和pathway的概念就来了。GO和KEGG的本质是规范了基因之间的关系。GO整合了所有物种,是从生命系统的角度来统一基因的关系,这种关系只是一个集合;KEGG是针对一个物种来界定基因之间的关系,这种关系是有向图结构。必须再深入了解GO和KEGG的制作原理,暂时不深入。此时我们开始区分基因类型,蛋白编码、非编码、转录因子。在这个阶段我们更关注的是基因之间的调控关系。
中心法则揭示了生命系统的层级和管道结构,和计算机的通信系统很类似,就算上游的基础调控再复杂,下游的蛋白都是决定性因素,所以令人惊叹的是上游调控如此复杂多变,可下游的蛋白确是非常稳定,这说明复杂多变的调控是非常稳定的。
基因研究的第一步必然是基因的功能,其次才是基因的调控。
基因功能
那么如何研究一个基因的功能呢?参考:#基因组观#基因功能研究的“七大绝招”与“三板斧” - BioinforCN
简单总结一下这篇文章:
1. 天地人和,研究基因表达的时空规律来推测功能,这和侦探调查是一样的,属于间接推理;
2. 患得患失,就是直接操作基因,knock out或down或overexpress,来直接探索基因的功能,属于直接观察;
3. 上下求索,因为中心法则是个层级和管道系统,上下游十分明确,从基因的DNA、RNA到蛋白质,一起研究;
4. 十面埋伏,立体论证,做生物的很容易观察到假阳性,必须多角度论证;
5. 其他的,misexpression、in vitro/vivo。
不说人类hs了,假设你负责一个全新的物种的基因组和基因功能研究,你如何找到该物种的所有基因呢?
看任何一篇基因组组装文章都能找到解决方案。那我们就看看严建兵的最新的玉米的NG吧,Genome assembly of a tropical maize inbred line provides insights into structural variation and crop improvement。
微信文章:《Nature Genetics》| 玉米产量相关基因找到了 | 热带玉米基因组及高精度结构变异图谱成功构建,助力玉米遗传改良
首先是基因组DNA的组装,Genome sequencing, assembly and scaffolding,这部分纯技术,以后估计都不要组装了,直接把基因组测出来;
其次就是基因组注释了,Genome annotation,这部分是我们现在最感兴趣的部分,如何找到一个新物种内的所有基因?
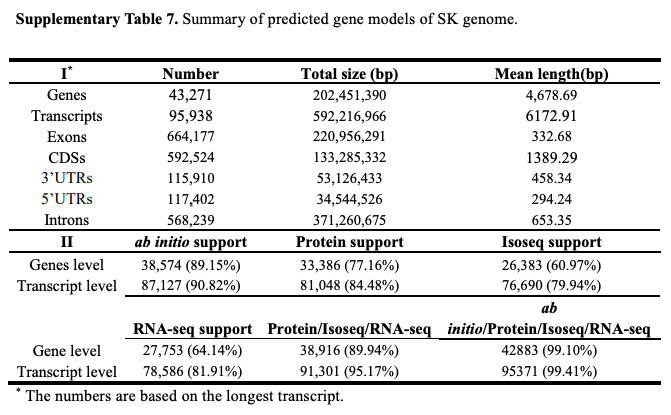
A comprehensive strategy combining de novo gene prediction, protein-based homology searches, RNA sequencing (RNA-Seq) and isoform sequencing (Iso-Seq) of nine tissues (Supplementary Table 6) was used to annotate the genes (Supplementary Fig. 7).
方案来了:
1. 基因是有特殊结构的,所以只要有DNA序列,就可以做denovo预测;
2. 中心法则告诉我们DNA、RNA和蛋白质是环环相扣的,所有测RNA-seq和iso-seq可以间接推出基因;
3. 蛋白测序还没有普及,所以目前都用的同源蛋白序列来反推;
这样注释出来的只是很general的基因注释,能cover绝大多数基因,但某些特殊结构的肯定无法注释出来。
有了草图,后面再做实验的功能研究就会方便很多。
基于高通量测序的前两步只能告诉你基因组的这个地方是个基因,但是不可能告诉你它的功能;第三步就是基于已有的知识了,做同源推理。所以目前来看所有的生物知识都是来源于实验的,测序只是一个加速的辅助手段而已。
可以没有测序,但是不能没有实验,测序是科研加速的催化剂。
文章结果:
GENE FINDING METHODS - broad institute - 很全面
基因表达调控/转录调控
教科书解释:
- 染色体和染色质水平的结构变化,导致基因活性变化;Hi-C,bulk平均好些,sc的量太少不靠谱
- 转录水平调控;转录因子,enhancer,promoter,ncRNA
- RNA加工水平调控,剪切修饰编辑降解;甲基化,lncRNA抑制降解
- 转录后,细胞核向细胞质转运;HDAC4
- 翻译水平;
- 蛋白合成水平;蛋白修饰定量,不是AA测序
目前最火的两个可以用高通量测序研究的调控方法:
- 转录因子,enhancer,promoter
- 非编码RNA,lncRNA、miRNA、ceRNA
参考:
Modes of transcriptional regulation
Transcriptional Regulation and Its Misregulation in Disease
项目问题:
现在in vivo和in vitro模型都已成熟,RNA-seq成本大家都可以接受了,CRISPR技术也成熟了,KO一个基因已经变得非常容易,现在发育生物学、生物医学等都在这么做:KO一个基因,来探索自己感兴趣的生物过程发生了哪些变化。
现在问题来了,KO后表型肯定发生了变化,那么如何把这个表型和基因表达和调控联系到一起呢?
这是一个general的问题,解答好了可以用于任意一个基因的深入研究。
大体解决方案:
假设检验是科研获取真知的唯一手段,首先我们必须要一个合理的假设,然后去寻找各种证据来test这个假设。
没有假设和验证就不是做科研,那就是一个技工得出一份没有意义的结题报告。
问题:
1. RNA-seq的建库方案有哪些?ployA、随机等。只抓有polyA的MRNA会有哪些优势和缺点?ployA只有mRNA有,所以polyA建库只能抓到蛋白编码基因,很少部分地ncRNA。参见链接
2. 细胞核和全部测序的区别?
3. 基因的长度差别到底有多大?
4. 可变剪切和isoform是如何影响蛋白的?
5. KEGG里面已经有基因的关系了,为什么我们还要研究基因调控?
6. 蛋白互作网络的用途和局限性是什么?
7. 蛋白是唯一的决定性因素吗?是的,绝大多数DNA和RNA层面的变化都会最终改变蛋白的功能。比如HSCR的无法形成ENS就是一个复杂的表型,可以肯定的是某些蛋白的功能执行紊乱了。
8. 基因表达的高低重要,还是基因表达的on/off重要?
9. 基因是如何找到和定位的?基因的编码的蛋白是如何确定的?
10. 如何理解基因之间的关系,是什么性质的关系?
11. 如何立即基因的拷贝数对基因表达的影响?
12. transposable-element对基因表达的影响?
13. 基因的经典结构是什么样的?什么是CDS和UTR?可以结合目前主流的基因预测工具来看。
14. 转录调控和蛋白互作有什么联系和区别?
Typical structure of a mature eukaryotic mRNA (AUG, UAA/UAG/UGA)

待续~
(基因功能 & 基因表达调控)研究方案的更多相关文章
- Mf175-用户注册功能-埋点敏捷方案
在不了解埋点系统的情况下,花了五六个小时 帮一位PM朋友做的方案.记录下来.以备后续参考 Mf178-用户注册功能-埋点敏捷方案 版本号 时间 撰写人 描述 V1.0 20190515-10:50:0 ...
- JMessage是让App 同时集成 Push 功能与 IM 功能最完美的方案
历经几个月的沉寂,以及兄弟们的奋战,极光推送的兄弟产品诞生了:极光IM,英文名 JMessage. 极光IM 是我们团队基于大量客户的需求反馈,在很多客户的殷切期盼下所开发的.团队成员一方面要支撑极光 ...
- HTML5的本地存储功能,值得研究
https://developer.chrome.com/apps/offline_storage 搜索“chrome html5 本地缓存”,一大堆文章,比如: http://www.cnblogs ...
- gene network analysis
基因表达分析包括3个层次[68], 首先是单基因水平, 即比较对照组与实验组的每个基因是否存在表达差异, 这主要指差异基因表达分析; 其次是多基因水平, 如按照基因的共同功能.相互作用.共同表达等 ...
- lncRNA研究
------------------------------- Long noncoding RNAs are rarely translated in two human cell lines. ( ...
- (转)基因芯片数据GO和KEGG功能分析
随着人类基因组计划(Human Genome Project)即全部核苷酸测序的即将完成,人类基因组研究的重心逐渐进入后基因组时代(Postgenome Era),向基因的功能及基因的多样性倾斜.通过 ...
- 转录调控 | Transcriptional Regulation | Regulon
scRNA-seq做完该做的QC.normalization.imputation.clustering.trajectory和integration,就会开始做转录调控的分析了. 核心就是围绕着TF ...
- Cell Reports | 上海瑞金医院糜坚青等揭示组蛋白酰化/乙酰化修饰比率调控BRD4基因组分布
景杰生物 | 报道 组蛋白翻译后修饰,被认为构成一类超越基因序列的"组蛋白密码",控制着遗传信息的组织层次及其在染色质层面的解读.组蛋白赖氨酸乙酰化是研究最早的一类组蛋白修饰, ...
- 差异基因分析:fold change(差异倍数), P-value(差异的显著性)
在做基因表达分析时必然会要做差异分析(DE) DE的方法主要有两种: Fold change t-test fold change的意思是样本质检表达量的差异倍数,log2 fold change的意 ...
随机推荐
- mysql 开启日志与性能调优
#查看日期情况 #show variables like '%general%'; #开启日志 #SET GLOBAL general_log = 'On'; #指定日志文件 #SET GLOBAL ...
- 尚硅谷MySQL基础学习笔记
目录 写在前面 MySQL引入 数据库的好处 数据库的相关概念 数据库存储数据的特点 MySQL服务的启动和停止 MySQL服务端的登录和退出 MySQL的常用命令 MySQL语法规范 DQL(Dat ...
- 【转】关于TCP/IP,必须知道的十个知识点
本文整理了一些TCP/IP协议簇中需要必知必会的十大问题,既是面试高频问题,又是程序员必备基础素养. 一.TCP/IP模型 TCP/IP协议模型(Transmission Control Protoc ...
- 优化API接口响应速度
前言 API接口响应慢? SLA一直提不上去? 其实这是后端程序员想进阶必须要跨过去的坎:就是把它优化掉. 那么这其中到底有没有套路呢?答案是:有的. 本文将介绍目前正在用并且十分“无脑”有效的这个套 ...
- swagger是什么OpenAPI是什么
wiki: https://en.wikipedia.org/wiki/OpenAPI_Specification 官网: https://swagger.io/specification/
- LAMP环境搭建基本步骤
LAMP环境搭建基本步骤 参考链接https://yq.aliyun.com/articles/106387 apache性能优化.配置https://my.oschina.net/lockupme/ ...
- Scrum会议博客以及测试报告
3组Alpha冲刺阶段博客目录 一.Scrum Meeting1. 第六周会议记录(链接地址:https://www.cnblogs.com/Cherrison-Time/articles/11788 ...
- LOJ#2764. 「JOI 2013 Final」JOIOI 塔
题目地址 https://loj.ac/problem/2764 题解 真的想不到二分...不看tag的话... 考虑二分答案转化为判定问题,那么问题就变成了能不能组合出x个JOI/IOI,考虑贪心判 ...
- 《Exceptioning团队》第四次作业:项目需求调研与分析
一.项目基本介绍 项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 Exception 作业学习目标 1.探索团队软件项目需求获取技巧与方法2.学会 ...
- 二次封装Response类 | 视图类传递参数给序列化类context
二次封装Response类 源码: class Response(SimpleTemplateResponse): """ An HttpResponse that al ...