CUDA学习笔记(一)【转】
CUDA编程中,习惯称CPU为Host,GPU为Device。编程中最开始接触的东西恐怕是并行架构,诸如Grid、Block的区别会让人一头雾水,我所看的书上所讲述的内容比较抽象,对这些概念的内容没有细讲,于是在这里作一个整理。
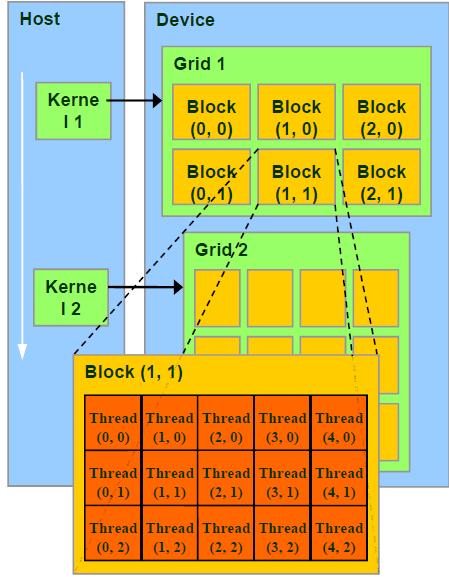
Grid、Block和Thread的关系
Thread :并行运算的基本单位(轻量级的线程)
Block :由相互合作的一组线程组成。一个block中的thread可以彼此同步,快速交换数据,最多可以同时512个线程。
Grid :一组Block,有共享全局内存
Kernel :在GPU上执行的程序,一个Kernel对应一个Grid。
其结构如下图所示:
|
1
2
3
4
5
6
7
8
9
10
|
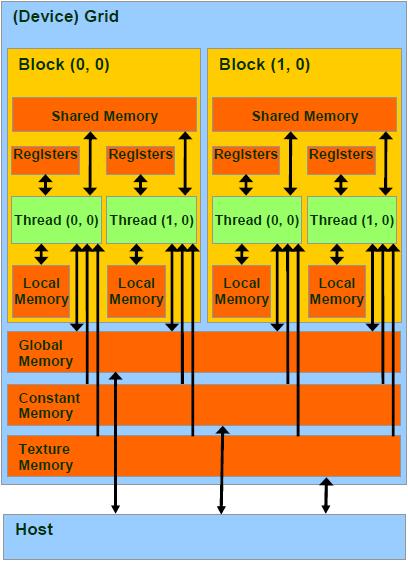
/*另外:Block和Thread都有各自的ID,记作blockIdx(1D,2D),threadIdx(1D,2D,3D)Block和Thread还有Dim,即blockDim与threadDim. 他们都有三个分量x,y,z线程同步:void __syncthreads(); 可以同步一个Block内的所有线程总结来说,每个 thread 都有自己的一份 register 和 local memory 的空间。一组thread构成一个 block,这些 thread 则共享有一份shared memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。*/ |
|
1
2
3
4
5
6
7
|
per-thread register 1 cycleper-thread local memory slowper-block shared memory 1 cycleper-grid global memory 500 cycle,not cached!!constant and texture memories 500 cycle, but cached and read-only分配内存:cudaMalloc,cudaFree,它们分配的是global memoryHose-Device数据交换:cudaMemcpy |
|
1
2
3
4
5
|
__device__ // GPU的global memory空间,grid中所有线程可访问__constant__ // GPU的constant memory空间,grid中所有线程可访问__shared__ // GPU上的thread block空间,block中所有线程可访问local // 位于SM内,仅本thread可访问// 在编程中,可以在变量名前面加上这些前缀以区分。 |
|
1
2
3
4
5
6
7
8
9
|
// 内建矢量类型:int1,int2,int3,int4,float1,float2, float3,float4 ...// 纹理类型:texture<Type, Dim, ReadMode>texRef;// 内建dim3类型:定义grid和block的组织方法。例如:dim3 dimGrid(2, 2);dim3 dimBlock(4, 2, 2);// CUDA函数CPU端调用方法kernelFoo<<<dimGrid, dimBlock>>>(argument); |
|
1
2
3
4
5
6
7
8
9
10
|
__device__ // 执行于Device,仅能从Device调用。限制,不能用&取地址;不支持递归;不支持static variable;不支持可变长度参数__global__ // void: 执行于Device,仅能从Host调用。此类函数必须返回void__host__ // 执行于Host,仅能从Host调用,是函数的默认类型// 在执行kernel函数时,必须提供execution configuration,即<<<....>>>的部分。// 例如:__global__ void KernelFunc(...);dim3 DimGrid(100, 50); // 5000 thread blocksdim3 DimBlock(4, 8, 8); // 256 threads per blocksize_t SharedMemBytes = 64; // 64 bytes of shared memoryKernelFunc<<< DimGrid, DimBlock, SharedMemBytes >>>(...); |
|
1
2
|
CUDA包含一些数学函数,如sin,pow等。每一个函数包含有两个版本,例如正弦函数sin,一个普通版本sin,另一个不精确但速度极快的__sin版本。 |
|
1
2
3
4
5
|
/*gridDim, blockIdx, blockDim, threadIdx, wrapsize. 这些内置变量不允许赋值的*/ |
|
1
2
3
4
5
6
7
|
/*目前CUDA仅能良好的支持C,在编写含有CUDA代码的程序时,首先要导入头文件cuda_runtime_api.h。文件名后缀为.cu,使用nvcc编译器编译。目前最新的CUDA版本为5.0,可以在官方网站下载最新的工具包,网址为:该工具包内包含了ToolKit、样例等,安装起来比原先的版本也方便了很多。*/ |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
1 GPU硬件// i GPU一个最小单元称为Streaming Processor(SP),全流水线单事件无序微处理器,包含两个ALU和一个FPU,多组寄存器文件(register file,很多寄存器的组合),这个SP没有cache。事实上,现代GPU就是一组SP的array,即SPA。每一个SP执行一个thread// ii 多个SP组成Streaming Multiprocessor(SM)。每一个SM执行一个block。每个SM包含8个SP;2个special function unit(SFU):这里面有4个FPU可以进行超越函数和插值计算MultiThreading Issue Unit:分发线程指令具有指令和常量缓存。包含shared memory // iii Texture Processor Cluster(TPC) :包含某些其他单元的一组SM 2 Single-Program Multiple-Data (SPMD)模型 // i CPU以顺序结构执行代码,GPU以threads blocks组织并发执行的代码,即无数个threads同时执行// ii 回顾一下CUDA的概念:一个kernel程序执行在一个grid of threads blocks之中一个threads block是一批相互合作的threads:可以用过__syncthreads同步;通过shared memory共享变量,不同block的不能同步。// iii Threads block声明:可以包含有1到512个并发线程,具有唯一的blockID,可以是1,2,3D同一个block中的线程执行同一个程序,不同的操作数,可以同步,每个线程具有唯一的ID 3 线程硬件原理// i GPU通过Global block scheduler来调度block,根据硬件架构分配block到某一个SM。每个SM最多分配8个block,每个SM最多可接受768个thread(可以是一个block包含512个thread,也可以是3个block每个包含256个thread(3*256=768!))。同一个SM上面的block的尺寸必须相同。每个线程的调度与ID由该SM管理。// ii SM满负载工作效率最高!考虑某个Block,其尺寸可以为8*8,16*16,32*328*8:每个block有64个线程,由于每个SM最多处理768个线程,因此需要768/64=12个block。但是由于SM最多8个block,因此一个SM实际执行的线程为8*64=512个线程。16*16:每个block有256个线程,SM可以同时接受三个block,3*256=768,满负载32*32:每个block有1024个线程,SM无法处理! // iii Block是独立执行的,每个Block内的threads是可协同的。// iv 每个线程由SM中的一个SP执行。当然,由于SM中仅有8个SP,768个线程是以warp为单位执行的,每个warp包含32个线程,这是基于线程指令的流水线特性完成的。Warp是SM基本调度单位,实际上,一个Warp是一个32路SIMD指令。基本单位是half-warp。如,SM满负载工作有768个线程,则共有768/32=24个warp,每一瞬时,只有一组warp在SM中执行。Warp全部线程是执行同一个指令,每个指令需要4个clock cycle,通过复杂的机制执行。// v 一个thread的一生:Grid在GPU上启动;block被分配到SM上;SM把线程组织为warp;SM调度执行warp;执行结束后释放资源;block继续被分配....4 线程存储模型// i Register and local memory:线程私有,对程序员透明。每个SM中有8192个register,分配给某些block,block内部的thread只能使用分配的寄存器。线程数多,每个线程使用的寄存器就少了。// ii shared memory:block内共享,动态分配。如__shared__ float region[N]。shared memory 存储器是被划分为16个小单元,与half-warp长度相同,称为bank,每个bank可以提供自己的地址服务。连续的32位word映射到连续的bank。对同一bank的同时访问称为bank conflict。尽量减少这种情形。 // iii Global memory:没有缓存!容易称为性能瓶颈,是优化的关键!一个half-warp里面的16个线程对global memory的访问可以被coalesce成整块内存的访问,如果:数据长度为4,8或16bytes;地址连续;起始地址对齐;第N个线程访问第N个数据。Coalesce可以大大提升性能。// uncoalesced Coalesced方法:如果所有线程读取同一地址,不妨使用constant memory;如果为不规则读取可以使用texture内存如果使用了某种结构体,其大小不是4 8 16的倍数,可以通过__align(X)强制对齐,X=4 8 16 |
CUDA学习笔记(一)【转】的更多相关文章
- CUDA学习笔记(三)——CUDA内存
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm5f.html 结合lec07_intro_cuda.pptx学习 内存类型 CGMA: Compute ...
- CUDA学习笔记(二)【转】
来源:http://luofl1992.is-programmer.com/posts/38847.html 编程语言的特点是要实践,实践多了才有经验.很多东西书本上讲得不慎清楚,不妨自己用代码实现一 ...
- CUDA学习笔记1
最近要做三维重建就学习一下cuda的一些使用. CUDA并行变成的基本四路是把一个很大的任务划分成N个简单重复的操作,创建N个线程分别执行. CPU和GPU,有各自的存储空间: Host, CPU a ...
- CUDA学习笔记-1: CUDA编程概览
1.GPU编程模型及基本步骤 cuda程序的基本步骤如下: 在cpu中初始化数据 将输入transfer到GPU中 利用分配好的grid和block启动kernel函数 将计算结果transfer到C ...
- CUDA学习笔记(四)——CUDA性能
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm5h.html 四.CUDA性能 CUDA中的block被划分成一个个的warp,在GeForce880 ...
- CUDA学习笔记(一)——CUDA编程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm56.html CUDA的代码分成两部分,一部分在host(CPU)上运行,是普通的C代码:另一部分在d ...
- CUDA学习笔记(二)——CUDA线程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm5b.html 一个grid中的所有线程执行相同的内核函数,通过坐标进行区分.这些线程有两级的坐标,bl ...
- cuda学习笔记——deviceQuery
main(int argc, char **argv):argc是参数个数,**argv具体的参数,第0个是程序全名 cudaError_t类型:记录cuda错误,值为cudaSuccess则正确执行 ...
- CUDA学习笔记4:CUDA(英伟达显卡统一计算架构)代码运行时间测试
CUDA内核运行时间的测量函数 cudaEvent_t start1; cudaEventCreate(&start1); cudaEvent_t stop1; cudaEventCreate ...
随机推荐
- (转)MyEclipse设置注释格式
原文:http://xinghaifeng2006.iteye.com/blog/1243565 MyEclipse设置注释格式(转载) 博客分类: Java基础知识 Windo ...
- 【LeetCode OJ】Longest Consecutive Sequence
Problem Link: http://oj.leetcode.com/problems/longest-consecutive-sequence/ This problem is a classi ...
- 《软件工程》individual project开发小记(一)
今天周四没有想去上的课,早八点到中午11点半,下午吃完饭后稍微完善了一下,目前代码可以在dev c++和vs2012上正常运行,性能分析我看资料上一大坨,考虑到目前状态不太好,脑袋转不动了,决定先放一 ...
- ModelFirst的CRUD
创建实体:
- 如何从oc中去获取一个私有的变量.....
运行时 的用法 1.定义的一个类,里面有一个私有变量mt_,并且在初始化值为"HaHa Ha ".@interface Mobj : NSObject {@privateNSStr ...
- HDU 4704
http://acm.hdu.edu.cn/showproblem.php?pid=4704 求(2^n)%mod的方法 #include <iostream> #include < ...
- WCF之多个终结点
1.服务端配置如下(一个Service节点下可有多个endpoint,): <system.serviceModel> <services> <service name= ...
- 第一个demo
1.首先这是最初的概念模型. 2.最后设计成这样. 3.运行
- 常用http请求状态码含义
1** ----临时响应 2** ----成功响应 3** ----重定向 4** ----请求错误 5** ----服务器错误 常用的几个如下: 200---服务器成功返回网页 301-- ...
- windows 任务栏图标宽度固定
这个需要修改注册表. win+r regedit ->enter 找到以下项 HKEY_CURRENT_USER-Control Panel-Desktop-WindowsMetrics 新建字 ...