C#正则表达式编程(三):Match类和Group类用法
前面两篇讲述了正则表达式的基础和一些简单的例子,这篇将稍微深入一点探讨一下正则表达式分组,在.NET中正则表达式分组是用Match类来代表的。
首先先看一段代码:
/// <summary>
/// 显示Match内多个Group的例子
/// </summary>
public void ShowStructure()
{
//要匹配的字符串
string text = "1A 2B 3C 4D 5E 6F 7G 8H 9I 10J 11Q 12J 13K 14L 15M 16N ffee80 #800080";
//正则表达式
string pattern = @"((/d+)([a-z]))/s+";
//使用RegexOptions.IgnoreCase枚举值表示不区分大小写
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//使用正则表达式匹配字符串,仅返回一次匹配结果
Match m = r.Match(text);
while (m.Success)
{
//显示匹配开始处的索引值和匹配到的值
System.Console.WriteLine("Match=[" + m + "]");
CaptureCollection cc = m.Captures;
foreach (Capture c in cc)
{
Console.WriteLine("/tCapture=[" + c + "]");
}
for (int i = ; i < m.Groups.Count; i++)
{
Group group = m.Groups[i];
System.Console.WriteLine("/t/tGroups[{0}]=[{1}]", i, group);
for (int j = ; j < group.Captures.Count; j++)
{
Capture capture = group.Captures[j];
Console.WriteLine("/t/t/tCaptures[{0}]=[{1}]", j, capture);
}
}
//进行下一次匹配.
m = m.NextMatch();
}
}
这段代码的执行效果如下:
Match=[1A ]
Capture=[1A ]
Groups[0]=[1A ]
Captures[0]=[1A ]
Groups[1]=[1A]
Captures[0]=[1A]
Groups[2]=[1]
Captures[0]=[1]
Groups[3]=[A]
Captures[0]=[A]
Match=[2B ]
Capture=[2B ]
Groups[0]=[2B ]
Captures[0]=[2B ]
Groups[1]=[2B]
Captures[0]=[2B]
Groups[2]=[2]
Captures[0]=[2]
Groups[3]=[B]
Captures[0]=[B]
..................此去省略一些结果
Match=[16N ]
Capture=[16N ]
Groups[0]=[16N ]
Captures[0]=[16N ]
Groups[1]=[16N]
Captures[0]=[16N]
Groups[2]=[16]
Captures[0]=[16]
Groups[3]=[N]
Captures[0]=[N]
通过对上面的代码结合代码的分析,我们得出下面的结论,在((/d+)([a-z]))/s+这个正则表达式里总共包含了四个Group,即分组,按照默认的从左到右的匹配方式,其中Groups[0]代表了整个分组,其它的则是子分组,用示意图表示如下: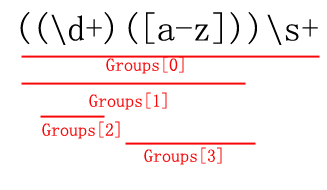
在上面的代码中是采用了Regex类的Match()方法,调用这种方法返回的是一个Match,要处理分析全部的字符串,还需要在while循环的中通过Match类的NextMatch()方法返回下一个可能成功的匹配(可通过Match类的Success属性来判断是否成功匹配)。上面的代码还可以写成如下形式:
/// <summary>
/// 使用Regex类的Matches方法所有所有的匹配
/// </summary>
public void Matches()
{
//要匹配的字符串
string text = "1A 2B 3C 4D 5E 6F 7G 8H 9I 10J 11Q 12J 13K 14L 15M 16N ffee80 #800080";
//正则表达式
string pattern = @"((/d+)([a-z]))/s+";
//使用RegexOptions.IgnoreCase枚举值表示不区分大小写
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//使用正则表达式匹配字符串,返回所有的匹配结果
MatchCollection matchCollection = r.Matches(text);
foreach (Match m in matchCollection)
{
//显示匹配开始处的索引值和匹配到的值
System.Console.WriteLine("Match=[" + m + "]");
CaptureCollection cc = m.Captures;
foreach (Capture c in cc)
{
Console.WriteLine("/tCapture=[" + c + "]");
}
for (int i = ; i < m.Groups.Count; i++)
{
Group group = m.Groups[i];
System.Console.WriteLine("/t/tGroups[{0}]=[{1}]", i, group);
for (int j = ; j < group.Captures.Count; j++)
{
Capture capture = group.Captures[j];
Console.WriteLine("/t/t/tCaptures[{0}]=[{1}]", j, capture);
}
}
}
}
上面的这段代码和采用While循环遍历所有匹配的结果是一样的,在实际情况中有可能出现不需要全部匹配而是从某一个位置开始匹配的情况,比如从第32个字符处开始匹配,这种要求可以通过Match()或者Matches()方法的重载方法来实现,仅需要将刚才的实例代码中的MatchCollection matchCollection = r.Matches(text);改为MatchCollection matchCollection = r.Matches(text,48);就可以了。
输出结果如下:
Match=[5M ]
Capture=[5M ]
Groups[0]=[5M ]
Captures[0]=[5M ]
Groups[1]=[5M]
Captures[0]=[5M]
Groups[2]=[5]
Captures[0]=[5]
Groups[3]=[M]
Captures[0]=[M]
Match=[16N ]
Capture=[16N ]
Groups[0]=[16N ]
Captures[0]=[16N ]
Groups[1]=[16N]
Captures[0]=[16N]
Groups[2]=[16]
Captures[0]=[16]
Groups[3]=[N]
Captures[0]=[N]
注意上面的MatchCollection matchCollection = r.Matches(text,48)表示从text字符串的位置48处开始匹配,要注意位置0位于整个字符串的之前,位置1位于字符串中第一个字符之后第二个字符之前,示意图如下(注意是字符串“1A”与“2B”之间有空格):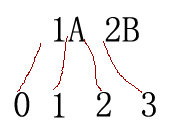
在text的位置48处正好是15M中的5处,因此返回的第一个Match是5M而不是15M。这里还继续拿出第一篇中的图来,如下: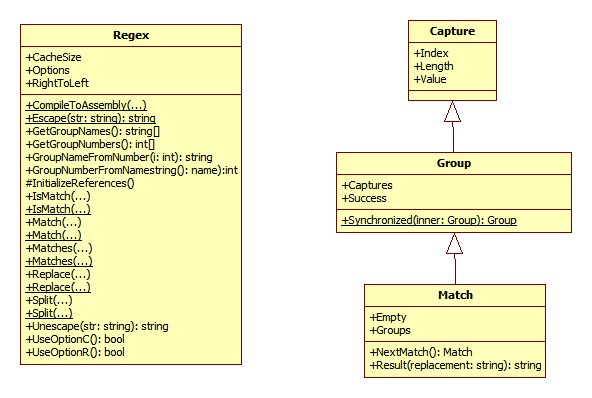
从上图可以看出Capture、Group及Match类之间存在继承关系,处在继承关系顶端的Capture类中就定义了Index、Length和Value属性,其中Index表示原始字符串中发现捕获子字符串的第一个字符的出现位置,Length属性表示子字符串的长度,而Value属性表示从原始字符串中捕获的子字符串,利用这些属性可以实现一些比较复杂的应用。例如在现在还有很多论坛仍没有使用所见即所得的在线编辑器,而是使用了一种UBB编码的编辑器,使用所见即所得的编辑器存在着一定的安全风险,比如可以在源代码中嵌入js代码或者其它恶意代码,这样浏览者访问时就会带来安全问题,而使用UBB代码就不会代码这个问题,因为UBB代码包含了有限的、但不影响常规使用的标记并且支持UBB代码的编辑器不允许直接在字符串中出现HTML代码,也而就避免恶意脚本攻击的问题。在支持UBB代码的编辑器中输入的文本在存入数据库中保存的形式是UBB编码,显示的时候需要将UBB编码转换成HTML代码,例如下面的一段代码就是UBB编码:
[url]http://zhoufoxcn.blog.51cto.com[/url][url=http://blog.csdn.net/zhoufoxcn]周公的专栏[/url]
下面通过例子演示如何将上面的UBB编码转换成HTML代码:
下面通过例子演示如何将上面的UBB编码转换成HTML代码:
/// <summary>
/// 下面的代码实现将文本中的UBB超级链接代码替换为HTML超级链接代码
/// </summary>
public void UBBDemo()
{
string text = "[url=http://zhoufoxcn.blog.51cto.com][/url][url=http://blog.csdn.net/zhoufoxcn]周公的专栏[/url]";
Console.WriteLine("原始UBB代码:" + text);
Regex regex = new Regex(@"(/[url=([ /S/t]*?)/])([^[]*)(/[//url/])", RegexOptions.IgnoreCase);
MatchCollection matchCollection = regex.Matches(text);
foreach (Match match in matchCollection)
{
string linkText = string.Empty;
//如果包含了链接文字,如第二个UBB代码中存在链接名称,则直接使用链接名称
if (!string.IsNullOrEmpty(match.Groups[].Value))
{
linkText = match.Groups[].Value;
}
else//否则使用链接作为链接名称
{
linkText = match.Groups[].Value;
}
text = text.Replace(match.Groups[].Value, "<a href="/" mce_href="/""" + match.Groups[2].Value + "/" target=/"_blank/">" + linkText + "</a>");
}
Console.WriteLine("替换后的代码:"+text);
}
程序执行结果如下:
原始UBB代码:[url=http://zhoufoxcn.blog.51cto.com][/url][url=http://blog.csdn.net/zhoufoxcn]周公的专栏[/url]
替换后的代码:<a href="http://zhoufoxcn.blog.51cto.com" target="_blank">http://zhoufoxcn.blog.51cto.com</a><a href="http://blog.csdn.net/zhoufoxcn"target="_blank">周公的专栏</a>
上面的这个例子就稍微复杂点,对于初学正则表达式的朋友来说,可能有点难于理解,不过没有关系,后面我会讲讲正则表达式。在实际情况下,可能通过match.Groups[0].Value这种方式不太方便,就想在访问DataTable时写string name=dataTable.Rows[i][j]这种方式一样,一旦再次调整,这种通过索引的方式极容易出错,实际上我们也可以采用名称而不是索引的放来来访问Group分组,这个也会在以后的篇幅中去讲。
C#正则表达式编程(三):Match类和Group类用法的更多相关文章
- C#正则表达式编程(二):Regex类用法
上一篇讲述了在C#中有关正则表达式的类之间的关系,以及它们的方法,这一篇主要是将Regex这个类的用法的,关于Match及MatchCollection类会在下一篇讲到.对于正则表达式的应用,基本上可 ...
- 关于SWT的容器类之----面板Composite类和Group类
1.Comosite类谱系图. Composite的用法: 格式:Composite(Composite parent,int style) 用法:Composite composite = new ...
- C# 正则表达式类 Match类和Group类
@"\b(\S+)://(\S+)\b"; //匹配URL的模式foreach (Match match in mc){ Console.WriteLine(match.Value ...
- Python:正则表达式(三)*、+、?的用法
一.功能*——表示匹配前面的字符0个或多个:+——表示前面的字符1个或多个:?——(1)放在其他字符后面:表示匹配0次或1次: (2)放在*.+后面:表示匹配尽可能少的字符 二.例 字符串fooooo ...
- C#正则表达式类Match和Group类的理解
正则表达式可以看做一种有特定功能的小型编程语言,在一段文本中定位子字符串.利用正则表达式可以快速地分析大量的文本以找到特定的字符模式:提取.编辑.替换或删除文本子字符串:或将提取的字符串添加到集合.正 ...
- C#正则表达式编程(一):C#中有关正则的类
正则表达式是一门灵活性非常强的语言,匹配同样的字符串可能在不同的开发人员那里会得到不同的结果,在平常的时候也是用的时候看看相关资料,不用的时候就丢在脑后了,尽管在处理大部分情况下都能迅速处理,但是处理 ...
- 正则表达式之Matcher类中group方法
前言 同事把一个excel表给我,里面的数据大概有几千的样子吧.自己需要把里面的数据一个一个拿出来做一个http请求,对得到的结果进行过滤,然后再写到上面去.这是就涉及到用脚本来进行操作了,于是自己搞 ...
- 转载 三、并行编程 - Task同步机制。TreadLocal类、Lock、Interlocked、Synchronization、ConcurrentQueue以及Barrier等
随笔 - 353, 文章 - 1, 评论 - 5, 引用 - 0 三.并行编程 - Task同步机制.TreadLocal类.Lock.Interlocked.Synchronization.Conc ...
- 三、并行编程 - Task同步机制。TreadLocal类、Lock、Interlocked、Synchronization、ConcurrentQueue以及Barrier等
在并行计算中,不可避免的会碰到多个任务共享变量,实例,集合.虽然task自带了两个方法:task.ContinueWith()和Task.Factory.ContinueWhenAll()来实现任务串 ...
随机推荐
- iOS 学习笔记 九 (2015.04.02)IOS8中使用UIAlertController创建警告窗口
1.IOS8中使用UIAlertController创建警告窗口 #pragma mark - 只能在IOS8中使用的,警告窗口- (void)showOkayCancelAlert{ NSSt ...
- 人工智能深度学习Caffe框架介绍,优秀的深度学习架构
人工智能深度学习Caffe框架介绍,优秀的深度学习架构 在深度学习领域,Caffe框架是人们无法绕过的一座山.这不仅是因为它无论在结构.性能上,还是在代码质量上,都称得上一款十分出色的开源框架.更重要 ...
- Mysql String Functions
SUBSTRING_INDEX(str,delim,count) 按标识符截取指定长度的字符串 mysql); -> 'www.mysql' mysql); -> 'mysql.com' ...
- 求两个数的最大公约数(Java)
获得两个随机数(100以内),并放入数组中 public int[] getTwoRandom(){ int[] t = new int[2]; Random rand = new Random(); ...
- 一个通用的DAO模型实现增删改查
首先三个架包: mysql-connector-java-jar commons-dbcp-1.4jar commons-pool-1.5.5jar 导进去: (从上往下一次调用,实现功能) ---- ...
- 实现multbandblend
一.首先实现 laplacian金字塔的分割和重构 #include "stdafx.h" #include <iostream> #include <vecto ...
- 使用Texture2D创建Cubemap
网上有很多,但大多使用Camera.RenderToCubemap接口,不能满足需求. 写了段代码可以载入Texture2D生成Cubemap(在Editor下运行): /// <summary ...
- Uva 11584,划分成回文串
题目链接:https://uva.onlinejudge.org/external/115/11584.pdf 题意: 一个字符串,将它划分一下,使得每个串都是回文串,求最少的回文串个数. 分析: d ...
- Apache common pool2 对象池
对象池的容器:包含一个指定数量的对象.从池中取出一个对象时,它就不存在池中,直到它被放回.在池中的对象有生命周期:创建,验证,销毁,对象池有助于更好地管理可用资源,防止JVM内部大量临时小对象,频繁触 ...
- Jquery 内容简介
内容简介 内容简介 • 什么是Jquery • 万能的选择器 • 管理jQuery包装集 • 使用jQuery操作元素的属性与样式 • 事件与事件对象 • jQuery中的Ajax • jQuery ...