Python Pandas库的学习(二)
今天我们继续讲下Python中一款数据分析很好的库。Pandas的学习
接着上回讲到的,如果有人听不懂,麻烦去翻阅一下我前面讲到的Pandas学习(一)
如果我们在数据中,想去3,4,5这几行数据,那么我们怎么取呢?
food.loc[3:6]
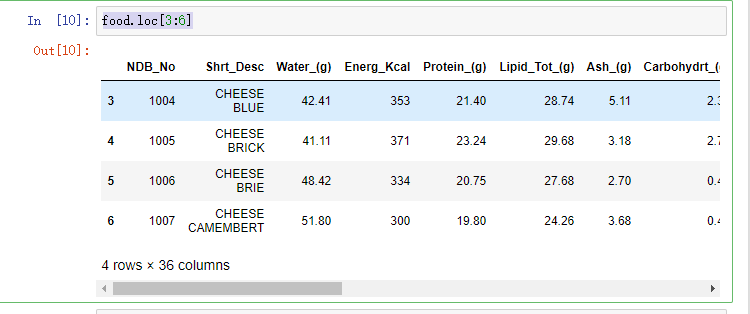
可以看到,这种取法跟Python中,切片操作一样。
如果我想去单独某几条数据,只需要传入index值即可
food.loc[[2,5,10]]
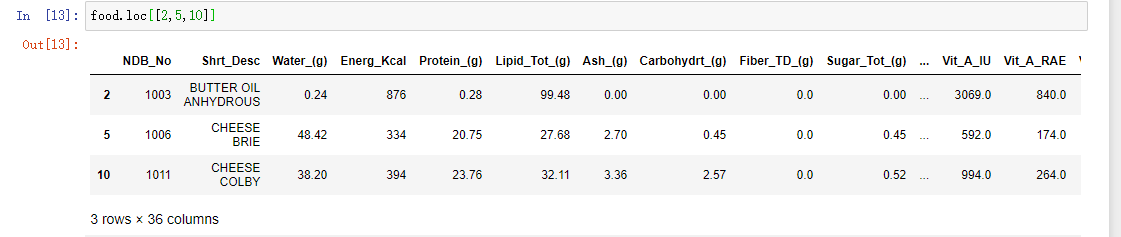
如果我先想不通过行去取数据,想通过列去取数据的话,我们该怎么做呢??
我们可以通过列名去拿取数据
col_NB = food["NDB_No"]
print(col_NB)

可以看到,我们取到了第一列的数据出来。
那么我们想取两列数据出来,我们应该怎么操作呢?
方法跟上面一样,将列名加到里面,组成一个list列表。
col_2 = ["Zinc_(mg)","Copper_(mg)"]
col_2_all = food[col_2]
print(col_2_all)

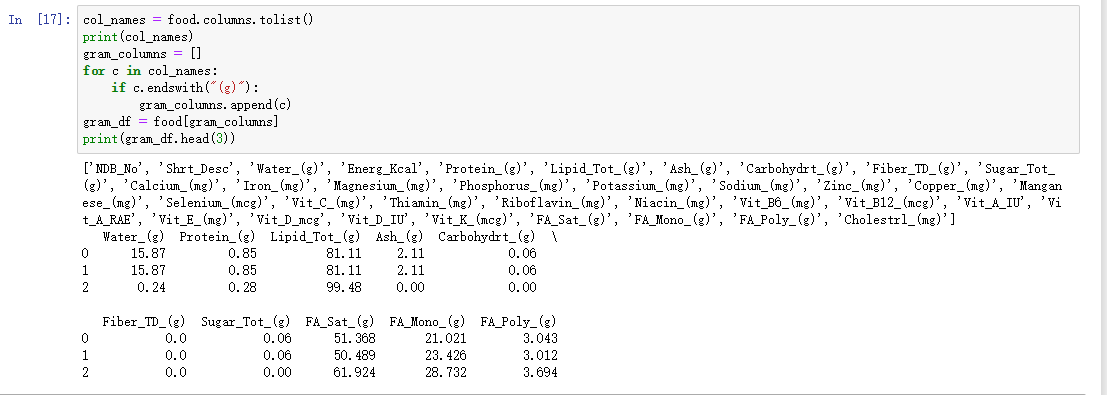
来我们看下数据上面,有些列名是带了单位的,那么我们怎么选择其中某几个一样单位的列呢?

我们先要取到全部的列名,然后将列名中带有单位(g)的列名取出,并单独放到一个列表中,最后在取这个列表中的列的数据即可
col_names = food.columns.tolist()
print(col_names)
gram_columns = []
for c in col_names:
if c.endswith("(g)"):
gram_columns.append(c)
gram_df = food[gram_columns]
print(gram_df.head(3))
这些都是些简单的操作,
再比如说,我们想进行一些加减乘除的操作。
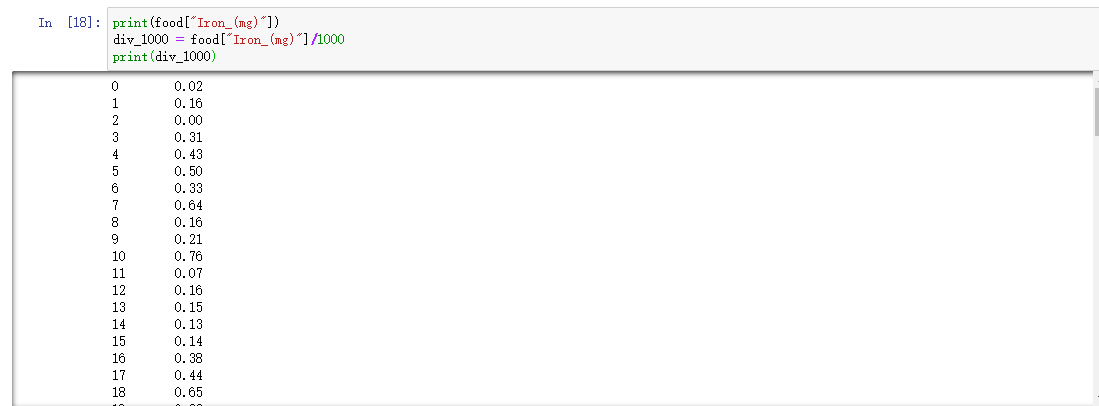
我想把单位为mg的数据,转换成g的数据,这里的做法,就跟Numpy是类似的。
print(food["Iron_(mg)"])
div_1000 = food["Iron_(mg)"]/1000
print(div_1000)
我们在对某个数据上进行操作,即可得到我们想要的结果。
water_energy = food["Water_(g)"]*food["Energ_Kcal"]
对应位置的乘法操作,需要保证的是,维度要相同才可以!
water_energy = food["Water_(g)"]*food["Energ_Kcal"]
water_energy = food["Water_(g)"]*food["Energ_Kcal"]
iron_grams = food["Iron_(mg)"]/1000
print(food.shape)
food["Iron_(g)"]=iron_grams
print(food.shape)

上一段代码可以看到,我们把一列名称的值,进行单位转换,把mg转换为g,然后新建了一列数据
将这列数据放到数据集中,之前打印出来的数据维度,8618个样本,和36个属性值。后面打印的
是37个属性值,也就是我们将新的属性值,放入到原来的数据值中了!前提是,其中的维度要对应上才可以。
weighted_protein = food["Protein_(g)"]*2
weighted_fat =-0.75* food["Lipid_Tot_(g)"]
initial_rating = weighted_protein + weighted_fat
比如说这些运算操作, 维度一样,相当于对应位置进行运算。
跟Numpy一样,我们也有一些别方法,求最大值,最小值,平均值等等

方式基本上跟Numpy类似。
今天就先讲到这里。感谢大家的阅读!感谢~~
Python Pandas库的学习(二)的更多相关文章
- Python Pandas库的学习(三)
今天我们来继续讲解Python中的Pandas库的基本用法 那么我们如何使用pandas对数据进行排序操作呢? food.sort_values("Sodium_(mg)",inp ...
- Python Pandas库的学习(一)
今天我们来学习一下Pandas库,前面我们讲了Numpy库的学习 接下来我们学习一下比较重要的库Pandas库,这个库比Numpy库还重要 Pandas库是在Numpy库上进行了封装,相当于高级Num ...
- python pandas库——pivot使用心得
python pandas库——pivot使用心得 2017年12月14日 17:07:06 阅读数:364 最近在做基于python的数据分析工作,引用第三方数据分析库——pandas(versio ...
- Python pandas库159个常用方法使用说明
Pandas库专为数据分析而设计,它是使Python成为强大而高效的数据分析环境的重要因素. 一.Pandas数据结构 1.import pandas as pd import numpy as np ...
- Python——Pandas库入门
一.Pandas库介绍 Pandas是Python第三方库,提供高性能易用数据类型和分析工具 import pandas as pd Pandas基于NumPy实现,常与NumPy和Matplotli ...
- Python Pandas库 初步使用
用pandas+numpy读取UCI iris数据集中鸢尾花的萼片.花瓣长度数据,进行数据清理,去重,排序,并求出和.累积和.均值.标准差.方差.最大值.最小值
- Python asyncio库的学习和使用
因为要找工作,把之前自己搞的爬虫整理一下,没有项目经验真蛋疼,只能做这种水的不行的东西...T T,希望找工作能有好结果. 之前爬虫使用的是requests+多线程/多进程,后来随着前几天的深入了解 ...
- python 标准库基础学习之开发工具部分1学习
#2个标准库模块放一起学习,这样减少占用地方和空间#标准库之compileall字节编译源文件import compileall,re,sys#作用是查找到python文件,并把它们编译成字节码表示, ...
- 使用Python的库qrcode生成二维码
现在有很多二维码的生成工具,在线的,或者安装的软件,都可以进行生成二维码.今天我用Python的qrcode库生成二维码.需要预先安装 Image 库 安装 用pip安装 # pip install ...
随机推荐
- 如何管理第三方接口token过期时间
背景: 随着微服务的盛行,做开发时不可避免的要涉及第三方接口,安全起见,这些接口都会需要一个token参数.而token一般都会有一个过期时间,比如2小时或者30分钟.那么如何在自己的应用中存储并管理 ...
- [BZOJ1381]Knights
Description 在一个N*N的棋盘上,有些小方格不能放骑士,棋盘上有若干骑士,任一个骑士不在其它骑士的攻击范围内,请输出最多可以放多少个骑士. 骑士攻击的点如中国象棋中的马,可以攻击8个点. ...
- [ZPG TEST 110] 多边形个数【DP】
1. 多边形个数 (polygons.pas/c/cpp) [问题描述] 给定N线段,编号1到n.并给出这些线段的长度,用这些线段组成一个K边形,并且每个线段做多使用一次.若使用了一条不同编号的线段, ...
- AngularJs调用NET MVC 控制器中的函数进行后台操作
题目中提到的控制器指的是.NET MVC的控制器,不是angularjs的控制器. 首先看主页面的代码: <!DOCTYPE html> <html> <head> ...
- JUnit单元测试&注解
①测试方法上必须使用@Test进行修饰 ②测试方法必须使用public void 进行修饰,不能带任何的参数 ③新建一个源代码目录来存放我们的测试代码,即将测试代码和项目业务代码分开 ④测试类所在的包 ...
- 移动端rem单位用法
1.rem(font size of the root element)是指相对于根元素的字体大小的单位,em(font size of the element)是指相对于父元素的字体大小的单位.它们 ...
- java之数据处理,小数点保留位数
1.返回字符串类型,保留后两位: public static String getRate(Object d) { return String.format("%.2f", d); ...
- 百度地图对https的支持
在使用百度地图时,如果直接使用其提供的js地址,在通过https的方式请求时,是不支持的 <script type="text/javascript" src="h ...
- Android Studio 导入新工程项目
1 导入之前先修改工程下相关文件 1.1 只需修改如下三个地方1.2 修改build.gradle文件 1.3 修改gradle/wrapper/gradle-wrapper.properties 1 ...
- php判断是否引入某文件
Code: /* 判断是否引入了公共文件demo.php */ $include_files = get_included_files(); $include_files_exist = 0 ; fo ...