pytorch学习-AUTOGRAD: AUTOMATIC DIFFERENTIATION自动微分
参考:https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#sphx-glr-beginner-blitz-autograd-tutorial-py
AUTOGRAD: AUTOMATIC DIFFERENTIATION
PyTorch中所有神经网络的核心是autograd包。让我们先简单地看一下这个,然后我们来训练我们的第一个神经网络。
autograd包为张量上的所有操作提供自动微分。它是一个按运行定义的框架,这意味着的、该支持是由代码的运行方式定义的,并且每个迭代都可以是不同的。
让我们用更简单的术语和一些例子来看看。
Tensor
torch.Tensor是包的中心类。如果将其属性.requires_grad设置为True,它将开始跟踪其上的所有操作。当你完成计算时,你可以调用 .backward()函数并自动计算所有的梯度。这个张量的梯度将累积为.grad属性。
要阻止张量跟踪历史,可以调用.detach()将其从计算历史中分离出来,并防止跟踪未来的计算。
为了防止跟踪历史(和使用内存),还可以使用torch.no_grad():将代码块封装起来。这在评估模型时特别有用,因为模型可能有requires_grad=True的可训练参数,但我们不需要梯度。
还有一个类对autograd实现非常重要—— 即函数。
张量和函数是相互联系的,并建立一个无环图,它编码了一个完整的计算历史。每个张量都有一个.grad_fn属性,该属性引用一个创建了张量的函数(用户创建的张量除外 —— 它们的grad_fn为None)。
如果你想计算导数,你可以在一个张量上调用 .backward() 。如果张量是一个标量(即它包含一个元素数据),你不需要指定任何参数给 .backward() ,但是如果它有更多的元素,你需要指定一个梯度参数,这是一个匹配形状的张量。
import torch
创建一个tensor x并设置requires_grad=True去追踪其计算;然后进行加法操作得到y, 这时候就能够查看y的.grad_fn属性去得到其计算的说明:
#-*- coding: utf- -*-
from __future__ import print_function
import torch x = torch.ones(, , requires_grad=True)
print(x) y = x +
print(y) print(y.grad_fn)
返回:
(deeplearning) userdeMBP:pytorch user$ python test.py
tensor([[., .],
[., .]], requires_grad=True)
tensor([[., .],
[., .]], grad_fn=<AddBackward0>)
<AddBackward0 object at 0x101816358>
上面的最后的返回结果AddBackward0说明了该y是经过加法操作获得的
还可以进行更多的操作:
#-*- coding: utf- -*-
from __future__ import print_function
import torch x = torch.ones(, , requires_grad=True) y = x + z = y * y *
out = z.mean() print(z)
print(out)
返回:
(deeplearning) userdeMBP:pytorch user$ python test.py
tensor([[., .],
[., .]], grad_fn=<MulBackward0>)
tensor(., grad_fn=<MeanBackward1>)
可以看出来z是乘法操作得出的,out是求平均值操作得出的
.requires_grad_( ... )函数会改变现存的Tensor的内置requires_grad标签。如果没设置,这个标签默认为False,即不计算梯度
#-*- coding: utf- -*-
from __future__ import print_function
import torch a = torch.randn(, )
a = ((a * ) / (a - ))
print(a)
print(a.requires_grad) a.requires_grad_(True)
print(a)
print(a.requires_grad) b = (a * a).sum()
print(b)
print(b.grad_fn)
返回:
(deeplearning) userdeMBP:pytorch user$ python test.py
tensor([[20.8490, -1.7316],
[ 1.4831, -2.8223]])
False
tensor([[20.8490, -1.7316],
[ 1.4831, -2.8223]], requires_grad=True)
True
tensor(447.8450, grad_fn=<SumBackward0>)
<SumBackward0 object at 0x10c381400>
Gradients梯度
因为out中只包含了一个标量,out.backward()和out.backward(torch.tensor(1.))的值是相同的
#-*- coding: utf- -*-
from __future__ import print_function
import torch x = torch.ones(, , requires_grad=True) y = x + z = y * y *
out = z.mean() print(out)
out.backward()
print(x.grad) # 得到out相对于x的梯度d(out)/dx
返回:
(deeplearning) userdeMBP:pytorch user$ python test.py
tensor(., grad_fn=<MeanBackward1>)
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
省略计算步骤
你应该得到值为4.5的矩阵。让我们将out称为Tensor "o"。o的计算公式为o=1/4 ∑izi,zi=3(xi+2)2且 zi∣xi=1=27。因此o对xi求导为 ∂o/∂xi=3/2(xi+2), 带入xi=1,则得到值4.5.
数学上,如果你有一个向量值函数 y⃗ =f(x⃗),那么 y⃗相对于 x⃗的梯度就是一个Jacobian矩阵:
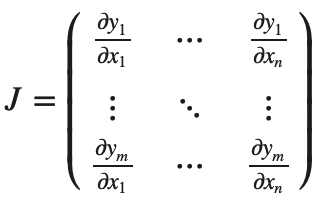
一般来说,torch.autograd是一个计算vector-Jacobian矩阵乘积的引擎。也就是说,给定任意向量v=(v1v2⋯vm)T,计算vT⋅J。
如果v是一个标量函数 l=g(y⃗)的梯度,那么v为 v=(∂l/∂y1⋯∂l/∂ym)T,根据链式法则,vector-Jacobian矩阵乘积就是l相对与x的梯度: 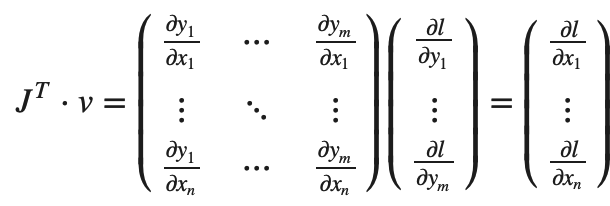
⚠️vT⋅J给出一个行向量,通过 JT⋅v该行向量可以被视为列向量
vector-Jacobian矩阵乘积的这种特性使得将外部梯度输入具有非标量输出的模型变得非常方便。
现在让我们看一个vector-Jacobian矩阵乘积的例子:
#-*- coding: utf- -*-
from __future__ import print_function
import torch x = torch.randn(, requires_grad=True)
print(x)
y = x *
print(y)
while y.data.norm() < : #归一化
y = y * print(y)
返回:
(deeplearning) userdeMBP:pytorch user$ python test.py
tensor([0.6542, 0.1118, 0.1979], requires_grad=True)
tensor([1.3084, 0.2236, 0.3958], grad_fn=<MulBackward0>)
tensor([1339.8406, 229.0077, 405.2867], grad_fn=<MulBackward0>)
在这种情况下,y不再是标量。 torch.autograd不能直接计算出整个Jacobian矩阵,但是如果我们只想要vector-Jacobian矩阵乘积,只需将向量作为参数向后传递:
#-*- coding: utf- -*-
from __future__ import print_function
import torch x = torch.randn(, requires_grad=True)
print(x)
y = x *
print(y)
while y.data.norm() < : #归一化
y = y * v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v) print(x.grad)
返回:
(deeplearning) userdeMBP:pytorch user$ python test.py
tensor([-0.7163, 1.6850, -0.0286], requires_grad=True)
tensor([-1.4325, 3.3700, -0.0572], grad_fn=<MulBackward0>)
tensor([1.0240e+02, 1.0240e+03, 1.0240e-01])
你可以通过使用with torch.no_grad():来封装代码块去阻止带有.requires_grad=True配置的Tensors的autograd去追踪历史:
#-*- coding: utf- -*-
from __future__ import print_function
import torch x = torch.randn(, requires_grad=True) print(x.requires_grad)
print((x ** ).requires_grad) with torch.no_grad():
print((x ** ).requires_grad)
返回:
(deeplearning) userdeMBP:pytorch user$ python test.py
True
True
False
有关autograd和Function的文档可见https://pytorch.org/docs/autograd
pytorch学习-AUTOGRAD: AUTOMATIC DIFFERENTIATION自动微分的更多相关文章
- Pytorch学习(一)—— 自动求导机制
现在对 CNN 有了一定的了解,同时在 GitHub 上找了几个 examples 来学习,对网络的搭建有了笼统地认识,但是发现有好多基础 pytorch 的知识需要补习,所以慢慢从官网 API进行学 ...
- PyTorch Tutorials 2 AUTOGRAD: AUTOMATIC DIFFERENTIATION
%matplotlib inline Autograd: 自动求导机制 PyTorch 中所有神经网络的核心是 autograd 包. 我们先简单介绍一下这个包,然后训练第一个简单的神经网络. aut ...
- 【pytorch】pytorch学习笔记(一)
原文地址:https://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html 什么是pytorch? pytorch是一个基于p ...
- (转)自动微分(Automatic Differentiation)简介——tensorflow核心原理
现代深度学习系统中(比如MXNet, TensorFlow等)都用到了一种技术——自动微分.在此之前,机器学习社区中很少发挥这个利器,一般都是用Backpropagation进行梯度求解,然后进行SG ...
- Autograd:自动微分
Autograd 1.深度学习的算法本质上是通过反向传播求导数,Pytorch的Autograd模块实现了此功能:在Tensor上的所有操作,Autograd都能为他们自动提供微分,避免手动计算导数的 ...
- PyTorch自动微分基本原理
序言:在训练一个神经网络时,梯度的计算是一个关键的步骤,它为神经网络的优化提供了关键数据.但是在面临复杂神经网络的时候导数的计算就成为一个难题,要求人们解出复杂.高维的方程是不现实的.这就是自动微分出 ...
- 自动微分(AD)学习笔记
1.自动微分(AD) 作者:李济深链接:https://www.zhihu.com/question/48356514/answer/125175491来源:知乎著作权归作者所有.商业转载请联系作者获 ...
- 理解PyTorch的自动微分机制
参考Getting Started with PyTorch Part 1: Understanding how Automatic Differentiation works 非常好的文章,讲解的非 ...
- PyTorch 自动微分示例
PyTorch 自动微分示例 autograd 包是 PyTorch 中所有神经网络的核心.首先简要地介绍,然后训练第一个神经网络.autograd 软件包为 Tensors 上的所有算子提供自动微分 ...
随机推荐
- ChartControl ViewType.Pie3D 用法测试
效果图一. public partial class Form3 : Form { public Form3() { InitializeComponent(); } private void For ...
- elementUI vue v-model的修饰符
v-model的修饰符 v-model.lazy 只有在input输入框发生一个blur时才触发 v-model.trim 将用户输入的前后的空格去掉 v-model.number 将用户输入的字符串 ...
- ssh多台主机实现互相认证
一.主机情况 如下图所示,集群一共11台机器.编辑每台主机的hosts文件,添加如下内容,方便统一管理. 10.202.62.60 hadoop60 10.202.62.61 hadoop61 10. ...
- Python 一键上传下载&一键提交文件到SVN入基线工具
一键上传下载&一键提交文件到SVN入基线工具 by:授客 QQ:1033553122 实现功能 1 测试环境 1 使用说明 1 注: 根据我司项目规则订制的一套工具,集成以下功能,源码 ...
- Android沉浸式状态栏的简单实现
随着卡片式设计在Android系统的上越来越流行,比如现在早已经烂大街的沉浸式状态栏,几乎所有的主流的APP都支持沉浸式状态栏,如QQ.UC浏览器等等.所以觉得有必要学习一下,找了点资料,总结了一下, ...
- [随时更新][Android]小问题记录
此文随时更新,旨在记录平时遇到的不值得单独写博客记录的细节问题,当然如果问题有拓展将会另外写博客. 原文地址请保留http://www.cnblogs.com/rossoneri/p/4040314. ...
- python爬虫学习记录——各种软件/库的安装
Ubuntu18.04安装python3-pip 1.apt-get update更新源 2,ubuntu18.04默认安装了python3,但是pip没有安装,安装命令:apt install py ...
- mysql学习之完整的select语句
本文内容: 完整语法 去重选项 字段别名 数据源 where group by having order by limit 首发日期:2018-04-11 完整语法: 先给一下完整的语法,后面将逐一来 ...
- matlab练习程序(求向量间的旋转矩阵与四元数)
问题是这样,如果我们知道两个向量v1和v2,计算从v1转到v2的旋转矩阵和四元数,由于旋转矩阵和四元数可以互转,所以我们先计算四元数. 我们可以认为v1绕着向量u旋转θ角度到v2,u垂直于v1-v2 ...
- centos开发环境安装的备忘
#Centos visudo运行普通用户$(whomai)执行sudo操作 http://www.cnblogs.com/xianyunhe/archive ...