webpack学习笔记--提取公共代码
为什么需要提取公共代码
大型网站通常会由多个页面组成,每个页面都是一个独立的单页应用。 但由于所有页面都采用同样的技术栈,以及使用同一套样式代码,这导致这些页面之间有很多相同的代码。
如果每个页面的代码都把这些公共的部分包含进去,会造成以下问题:
- 相同的资源被重复的加载,浪费用户的流量和服务器的成本;
- 每个页面需要加载的资源太大,导致网页首屏加载缓慢,影响用户体验。
如果把多个页面公共的代码抽离成单独的文件,就能优化以上问题。 原因是假如用户访问了网站的其中一个网页,那么访问这个网站下的其它网页的概率将非常大。 在用户第一次访问后,这些页面公共代码的文件已经被浏览器缓存起来,在用户切换到其它页面时,存放公共代码的文件就不会再重新加载,而是直接从缓存中获取。 这样做后有如下好处:
- 减少网络传输流量,降低服务器成本;
- 虽然用户第一次打开网站的速度得不到优化,但之后访问其它页面的速度将大大提升。
如何提取公共代码
你已经知道了提取公共代码会有什么好处,但是在实战中具体要怎么做,以达到效果最优呢? 通常你可以采用以下原则去为你的网站提取公共代码:
- 根据你网站所使用的技术栈,找出网站所有页面都需要用到的基础库,以采用 React 技术栈的网站为例,所有页面都会依赖 react、react-dom 等库,把它们提取到一个单独的文件。 一般把这个文件叫做
base.js,因为它包含所有网页的基础运行环境; - 在剔除了各个页面中被
base.js包含的部分代码外,再找出所有页面都依赖的公共部分的代码提取出来放到common.js中去。 - 再为每个网页都生成一个单独的文件,这个文件中不再包含 base.js 和 common.js 中包含的部分,而只包含各个页面单独需要的部分代码。
文件之间的结构图如下:
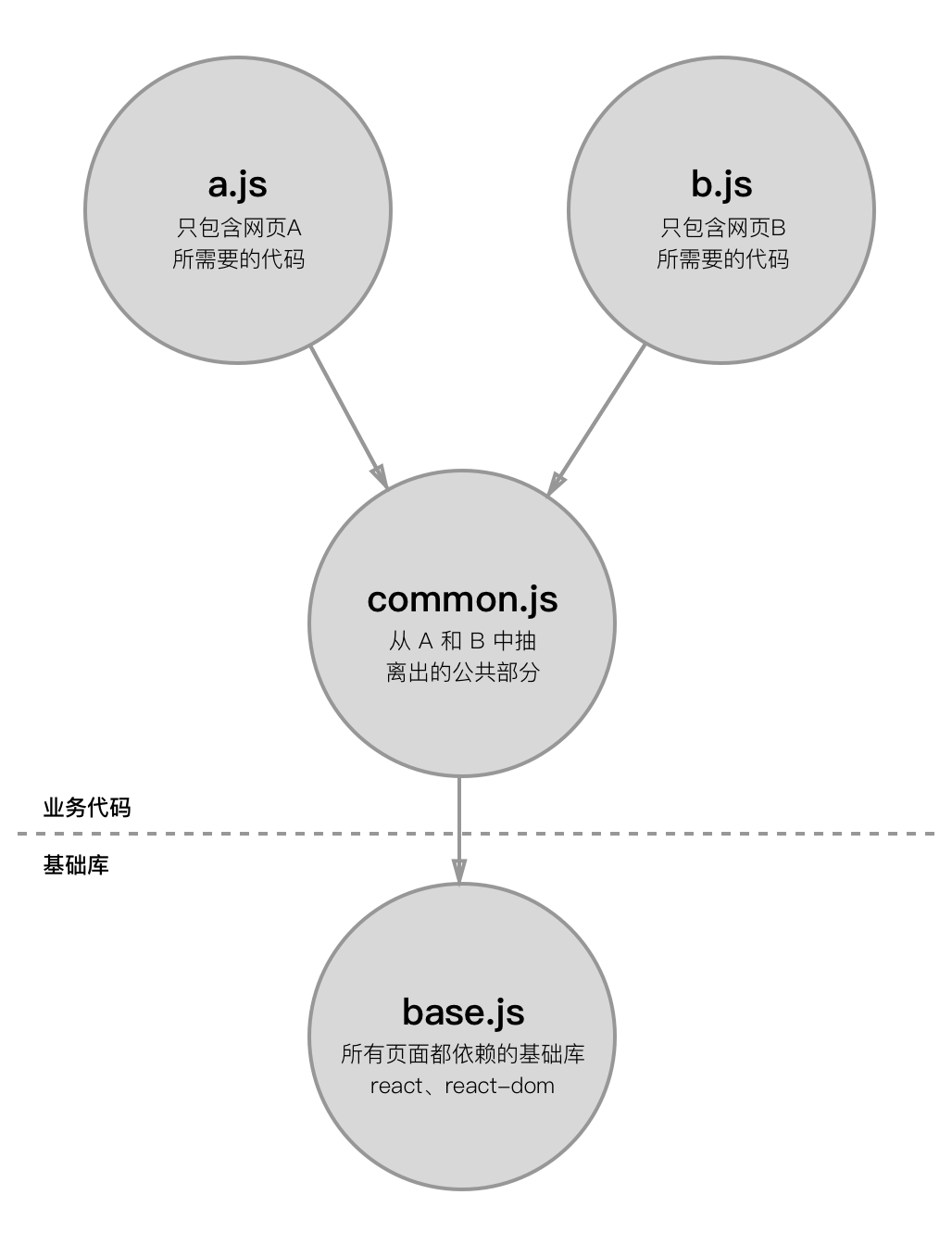
读到这里你可以会有疑问:既然能找出所有页面都依赖的公共代码,并提取出来放到 common.js 中去,为什么还需要再把网站所有页面都需要用到的基础库提取到 base.js 去呢? 原因是为了长期的缓存 base.js 这个文件。
发布到线上的文件都会采用在4-9CDN加速中介绍过的方法,对静态文件的文件名都附加根据文件内容计算出 Hash 值,也就是最终 base.js 的文件名会变成 base_3b1682ac.js ,以长期缓存文件。 网站通常会不断的更新发布,每次发布都会导致 common.js 和各个网页的 JavaScript 文件都会因为文件内容发生变化而导致其 Hash 值被更新,也就是缓存被更新。
把所有页面都需要用到的基础库提取到 base.js 的好处在于只要不升级基础库的版本,base.js 的文件内容就不会变化,Hash 值不会被更新,缓存就不会被更新。 每次发布浏览器都会使用被缓存的 base.js 文件,而不用去重新下载 base.js 文件。 由于 base.js 通常会很大,这对提升网页加速速度能起到很大的效果。
如何通过 Webpack 提取公共代码
你已经知道如何提取公共代码,接下来教你如何用 Webpack 实现。
Webpack 内置了专门用于提取多个 Chunk 中公共部分的插件 CommonsChunkPlugin , CommonsChunkPlugin 大致使用方法如下:
const CommonsChunkPlugin = require('webpack/lib/optimize/CommonsChunkPlugin');
new CommonsChunkPlugin({
// 从哪些 Chunk 中提取
chunks: ['a', 'b'],
// 提取出的公共部分形成一个新的 Chunk,这个新 Chunk 的名称
name: 'common'
})
以上配置就能从网页 A 和网页 B 中抽离出公共部分,放到 common 中。
每个 CommonsChunkPlugin 实例都会生成一个新的 Chunk,这个新 Chunk 中包含了被提取出的代码,在使用过程中必须指定 name 属性,以告诉插件新生成的 Chunk 的名称。 其中 chunks 属性指明从哪些已有的 Chunk 中提取,如果不填该属性,则默认会从所有已知的 Chunk 中提取。Chunk 是一系列文件的集合,一个 Chunk 中会包含这个 Chunk 的入口文件和入口文件依赖的文件。
通过以上配置输出的 common Chunk 中会包含所有页面都依赖的基础运行库 react、react-dom,为了把基础运行库从 common 中抽离到 base 中去,还需要做一些处理。
首先需要先配置一个 Chunk,这个 Chunk 中只依赖所有页面都依赖的基础库以及所有页面都使用的样式,为此需要在项目中写一个文件 base.js 来描述 base Chunk 所依赖的模块,文件内容如下:
// 所有页面都依赖的基础库
import 'react';
import 'react-dom';
// 所有页面都使用的样式
import './base.css';
接着再修改 Webpack 配置,在 entry 中加入 base,相关修改如下:
module.exports = {
entry: {
base: './base.js'
},
};
以上就完成了对新 Chunk base 的配置。
为了从 common 中提取出 base 也包含的部分,还需要配置一个 CommonsChunkPlugin,相关代码如下:
new CommonsChunkPlugin({
// 从 common 和 base 两个现成的 Chunk 中提取公共的部分
chunks: ['common', 'base'],
// 把公共的部分放到 base 中
name: 'base'
})
由于 common 和 base 公共的部分就是 base 目前已经包含的部分,所以这样配置后 common 将会变小,而 base 将保持不变。
以上都配置好后重新执行构建,你将会得到四个文件,它们分别是:
base.js:所有网页都依赖的基础库组成的代码;
common.js:网页A、B都需要的,但又不在 base.js 文件中出现过的代码;
a.js:网页 A 单独需要的代码;
b.js:网页 B 单独需要的代码。
为了让网页正常运行,以网页 A 为例,你需要在其 HTML 中按照以下顺序引入以下文件才能让网页正常运行:
<script src="base.js"></script>
<script src="common.js"></script>
<script src="a.js"></script>
以上就完成了提取公共代码需要的所有步骤。
针对 CSS 资源,以上理论和方法同样有效,也就是说你也可以对 CSS 文件做同样的优化。
以上方法可能会出现 common.js 中没有代码的情况,原因是去掉基础运行库外很难再找到所有页面都会用上的模块。 在出现这种情况时,你可以采取以下做法之一:
- CommonsChunkPlugin 提供一个选项
minChunks,表示文件要被提取出来时需要在指定的 Chunks 中最小出现最小次数。 假如 minChunks=2、chunks=['a','b','c','d'] ,任何一个文件只要在 ['a','b','c','d'] 中任意两个以上的 Chunk 中都出现过,这个文件就会被提取出来。 你可以根据自己的需求去调整 minChunks 的值,minChunks 越小越多的文件会被提取到common.js中去,但这也会导致部分页面加载的不相关的资源越多; minChunks 越大越少的文件会被提取到common.js中去,但这会导致common.js变小、效果变弱。 - 根据各个页面之间的相关性选取其中的部分页面用 CommonsChunkPlugin 去提取这部分被选出的页面的公共部分,而不是提取所有页面的公共部分,而且这样的操作可以叠加多次。 这样做的效果会很好,但缺点是配置复杂,你需要根据页面之间的关系去思考如何配置,该方法不通用。本实例提供项目完整代码
webpack学习笔记--提取公共代码的更多相关文章
- [转] 用webpack的CommonsChunkPlugin提取公共代码的3种方式
方式一,传入字符串参数 new webpack.optimize.CommonsChunkPlugin(‘common.js’), // 默认会把所有入口节点的公共代码提取出来,生成一个common. ...
- 详解用webpack的CommonsChunkPlugin提取公共代码的3种方式(注意webpack4.0版本已不存在)
Webpack 的 CommonsChunkPlugin 插件,负责将多次被使用的 JS 模块打包在一起. CommonsChunkPlugin 能解决的问题 在使用插件前,考虑几个问题: 对哪些 c ...
- 基于webpack实现多html页面开发框架六 提取公共代码
一.解决什么问题 1.如果a.js和b.js都引用了common.js,那在打包的时候common.js会被重复打入到a.js和b.js,造成重复打包 2.单独打包common.js对性能有帮助,浏览 ...
- webpack散记---提取公共代码
(1)作用: 减少代码冗余 提高加载速度 (2)来源 commonsChunkPlugin webpack.optimize.CommonsChunkPlugin (3)配置 { plugins:[ ...
- webpack学习笔记一(入门)
webpack集成了模块加载和打包等功能 ,这两年在前端领域越来越受欢迎.平时一般是用requirejs.seajs作为模块加载用,用grunt/gulp作为前端构建.webpack作为模块化加载兼容 ...
- webpack4 系列教程(三): 多页面解决方案--提取公共代码
这节课讲解webpack4打包多页面应用过程中的提取公共代码部分.相比于webpack3,4.0版本用optimization.splitChunks配置替换了3.0版本的CommonsChunkPl ...
- webpack学习笔记—优化缓存、合并、懒加载等
除了前面的webpack基本配置,还可以进一步添加配置,优化合并文件,加快编译速度.下面是生产环境配置文件webpack.production.js,与wenbpack.config.js相比其不需要 ...
- jQuery 学习笔记:jQuery 代码结构
jQuery 学习笔记:jQuery 代码结构 这是我学习 jQuery 过程中整理的笔记,这一部分主要包括 jQuery 的代码最外层的结构,写出来整理自己的学习成果,有错误欢迎指出. jQuery ...
- webpack配置提取公共代码
公共代码提取功能是针对多入口文件的: 背景:在pageA.js和pageB.js中分别引用subPageA.js和subPageB.js webpack.config.js文件: var path = ...
随机推荐
- 【转】Vim速查表-帮你提高N倍效率
Vim速查表-帮你提高N倍效率 转自:https://www.jianshu.com/p/6aa2e0e39f99 去年上半年开始全面使用linux进行开发和娱乐了,现在已经回不去windows了. ...
- Go语言中的结构体 (struct)
Golang官方称Go语言的语法相对Java语言而言要简洁很多,但是简洁背后也灵活了很多,所以很多看似很简单的代码上的细节稍不注意就会产生坑.本文主要对struct结构体的相关的语法进行总结和说明. ...
- 【转】Java内部类详解
一.内部类基础 在Java中,可以将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类.广泛意义上的内部类一般来说包括这四种:成员内部类.局部内部类.匿名内部类和静态内部类.下面就先来了解一 ...
- hibernate框架学习之一级缓存
l缓存是存储数据的临时空间,减少从数据库中查询数据的次数 lHibernate中提供有两种缓存机制 •一级缓存(Hibernate自身携带) •二级缓存(使用外部技术) lHibernate的一级缓存 ...
- JSON.stringify与JSON.parse
JSON.stringify(value [, replacer] [, space]) 用于将 对象 --> JSON 字符串. value:对象.数组.类 replacer: 数组时:v ...
- 开通博客的第一天上传我的C#基础笔记。
1.索引器 string arrStr = "sddfdfgfh"; 索引器的目的就是为了方便而已,可以在该类型的对象后面直接写[]访问该对象里面的成员 Console.Wr ...
- C# 使用EPPlus 秒导出10万条数据
1.先要引用dll文件,可以直接使用vs自带的包管理,如下图: 输入 EPPlus 我这里是安装过了的所以这里显示的是卸载而不是安装. 安装成功了之后会看到这个dll文件 代码如下: //导出Exce ...
- PyJWT 使用
最近要用 Falsk 开发一个大点的后端,为了安全考虑,弃用传统的Cookie验证.转用JWT. 其实 Falsk 有一个 Falsk-JWT 但是我觉得封装的太高,还是喜欢通用的 PyJWT . J ...
- 47)django-以put和delete方式提交数据
一:说明 同一个页面以ajax实现增删改查,对应方法post,delete,put,get, 其中delete和put方式提交的数据在request.body中需要序列化处理. 二:示例 #模板提交数 ...
- 彻底搞懂字符集编码:ASCII,Unicode 和 UTF-8
一.ASCII 码 我们知道,计算机内部,所有信息最终都是一个二进制值.每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte).也就是说,一个 ...