02.SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql
第一次引入文件组的概念:http://www.cnblogs.com/dunitian/p/5276431.html
上次说了其他的解决方案(http://www.cnblogs.com/dunitian/p/6041745.html),就是没有说水平分库,这次好好说下。
上次共享的第一份大数据,这次正好来演示一下水平分库
1.模拟部分数据
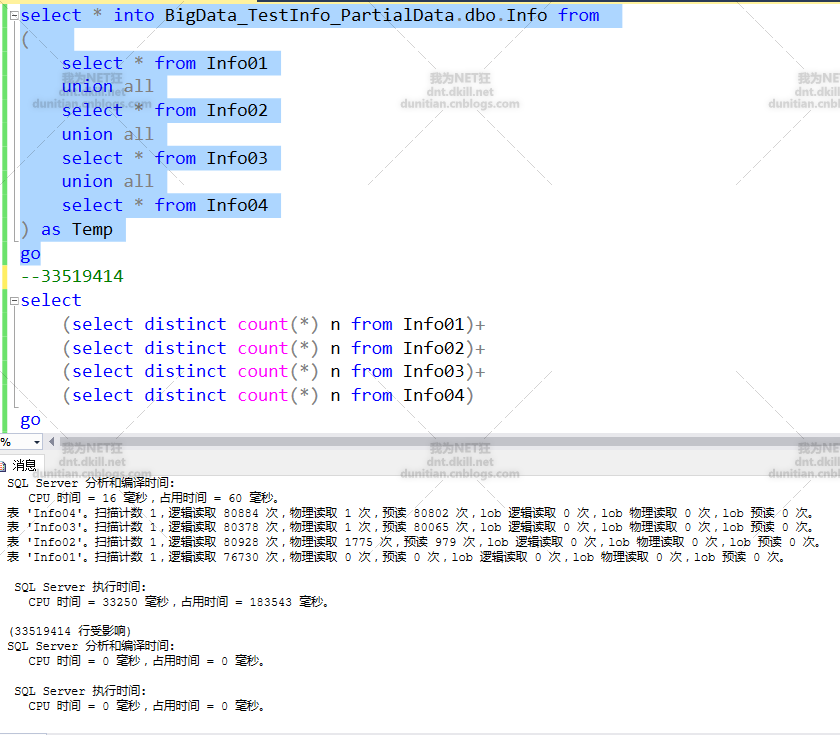
2.创建索引后,发现可以根据日期来分组
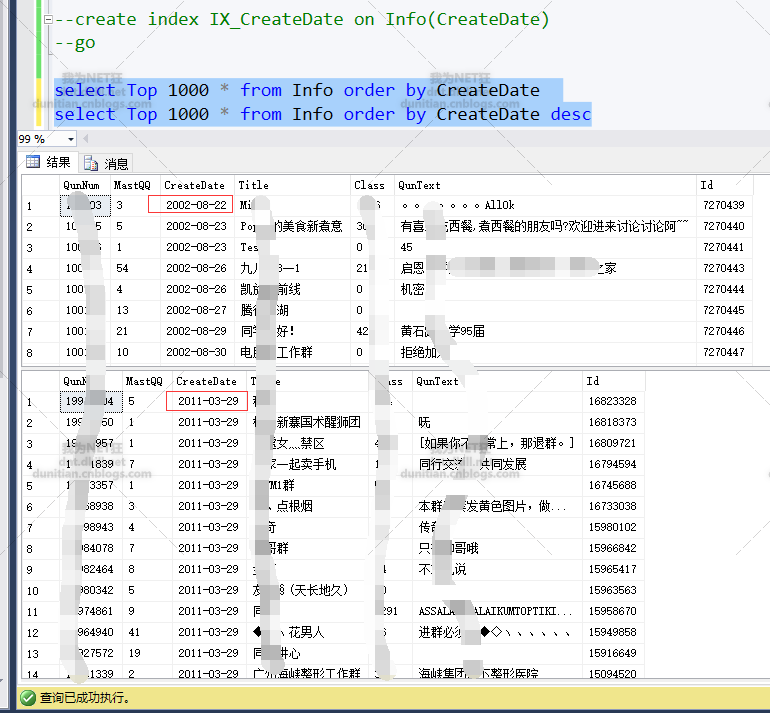
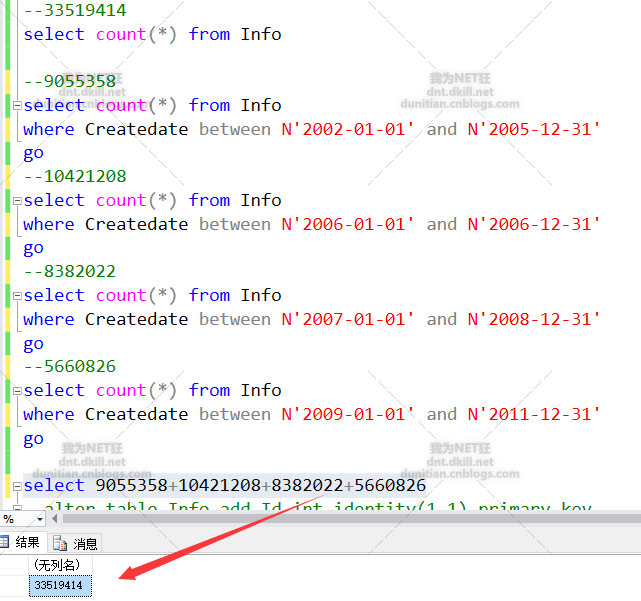
按数据量大致分一下
步入正轨
---------------------------------------------------------------------
GUI方法:
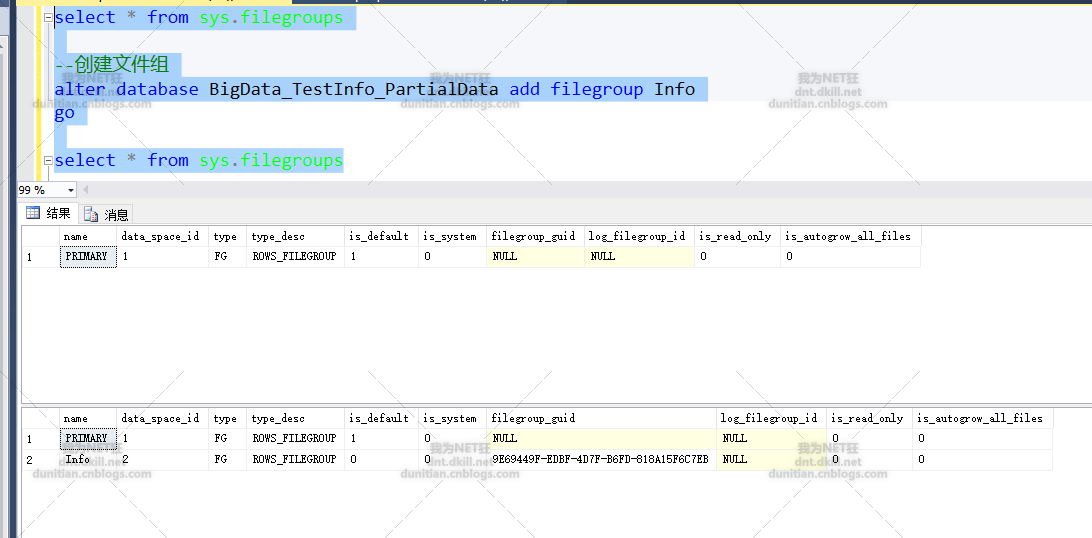
3.0创建文件组

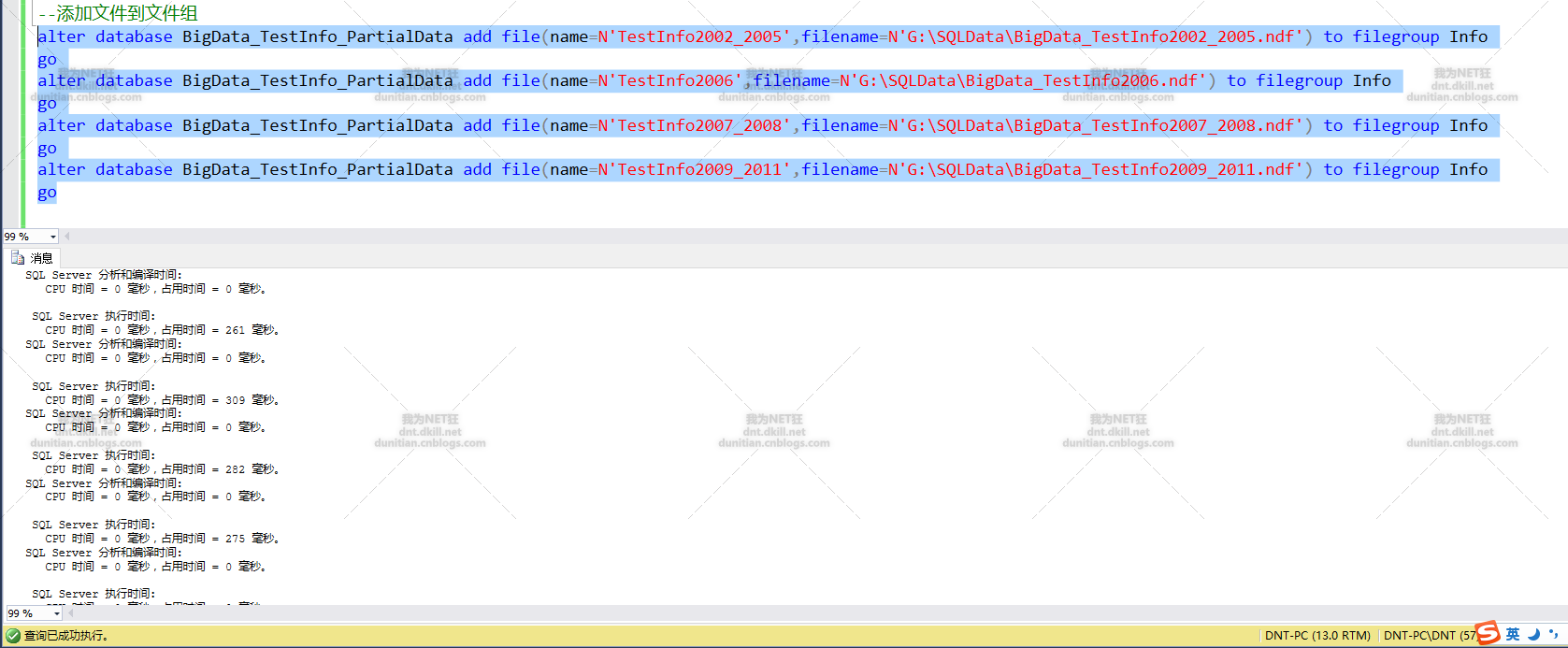
添加文件到文件组
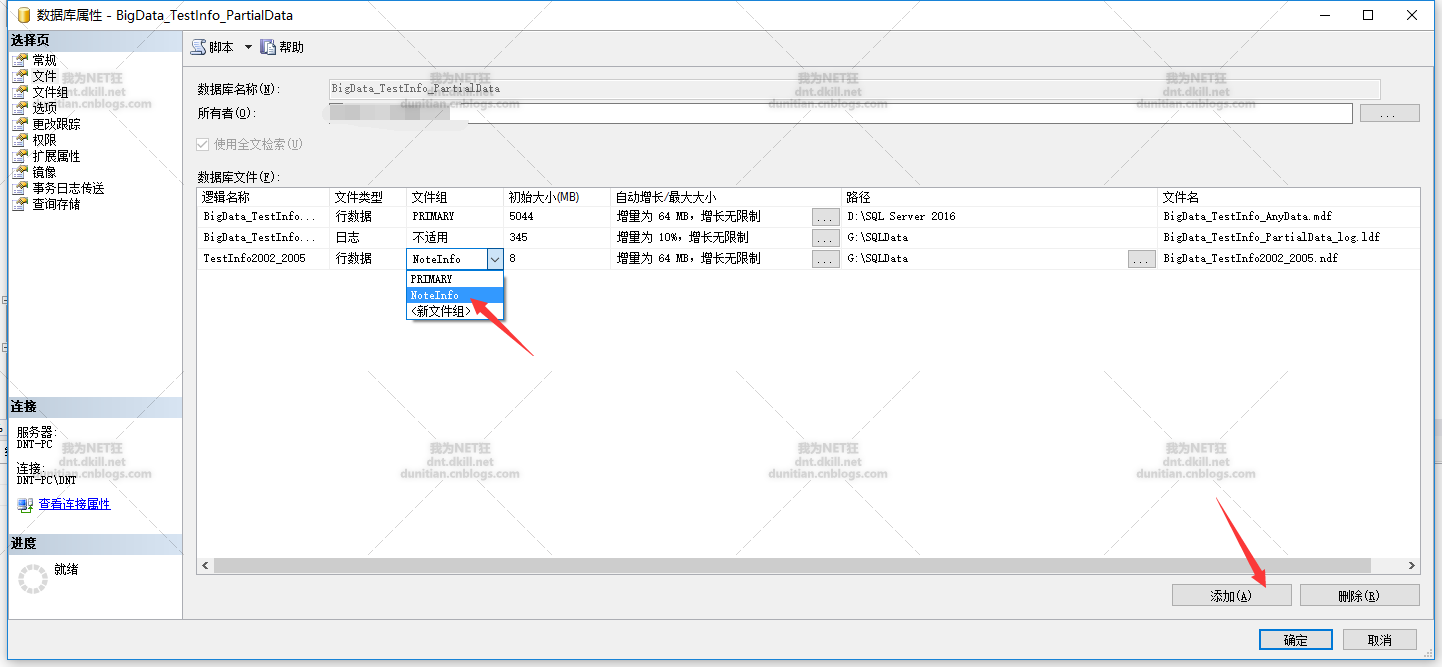
命令操作:
alter database BigData_TestInfo_PartialData add filegroup Info
alter database BigData_TestInfo_PartialData add file(name=N'TestInfo2006',filename=N'G:\SQLData\BigData_TestInfo2006.ndf') to filegroup Info
注意:BigData_TestInfo2006.ndf是数据库自己创建的,不需要自己手动创建(有些同志手动创建了,然后报错。。。。呃,有点哭笑不得了)
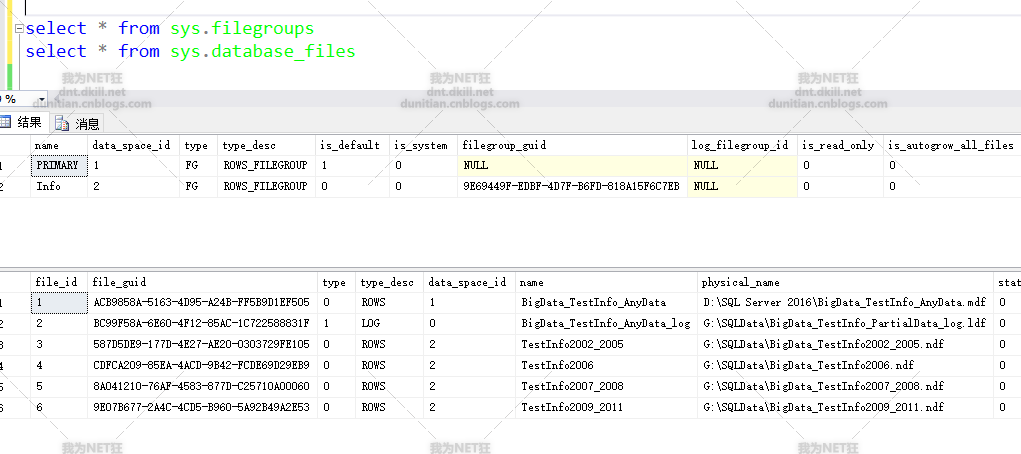
查询看看:select * from sys.filegroups
水平分区走起:一般就几步,1.创建分区函数 2.创建分区方案 3.创建分区表
GUI方法
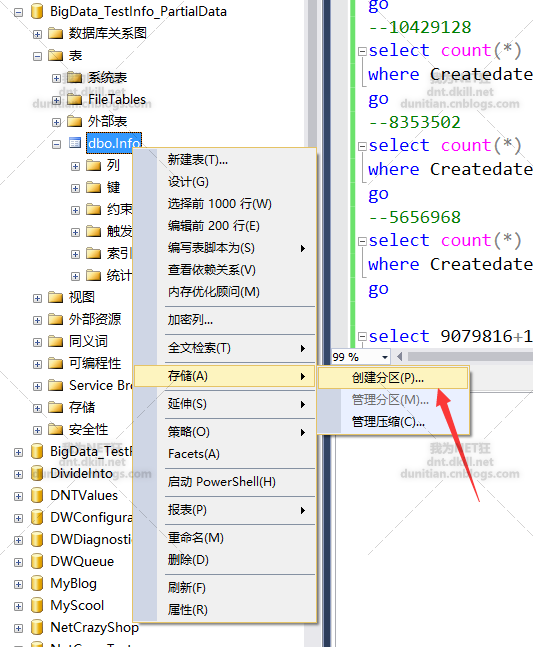
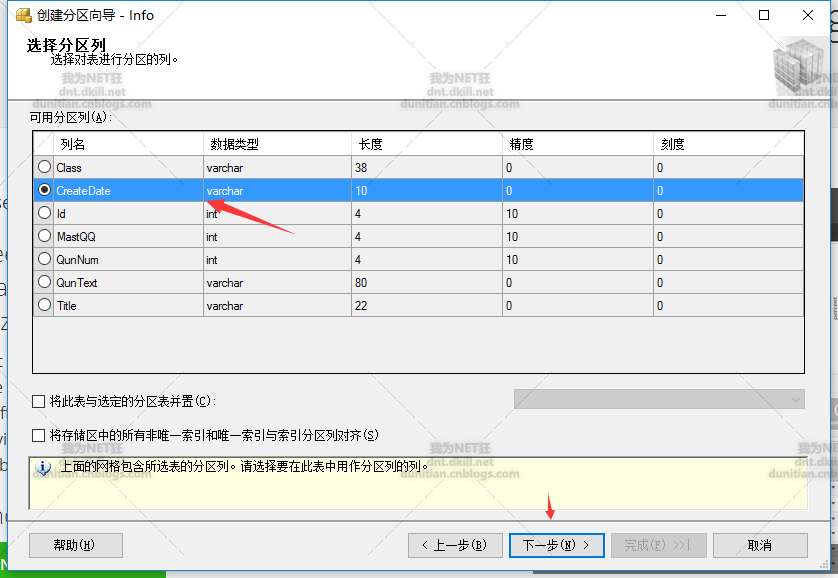
分区函数
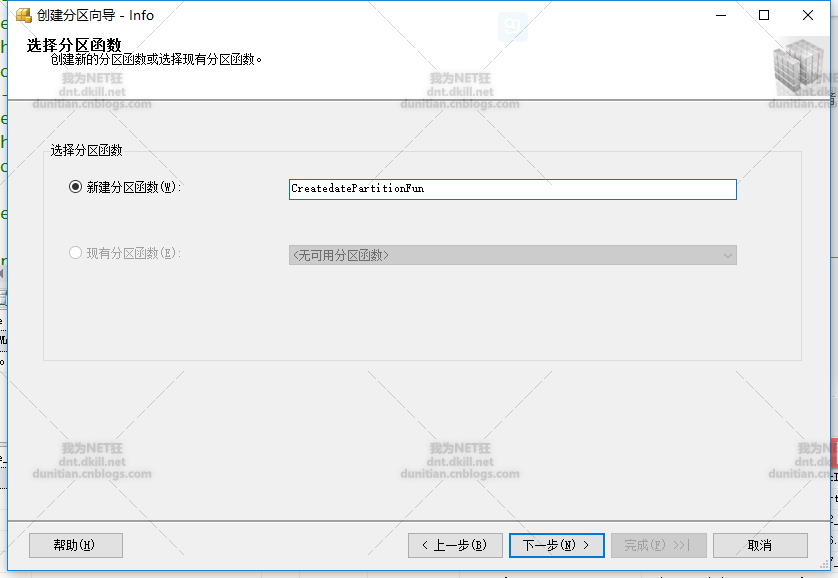
分区方案
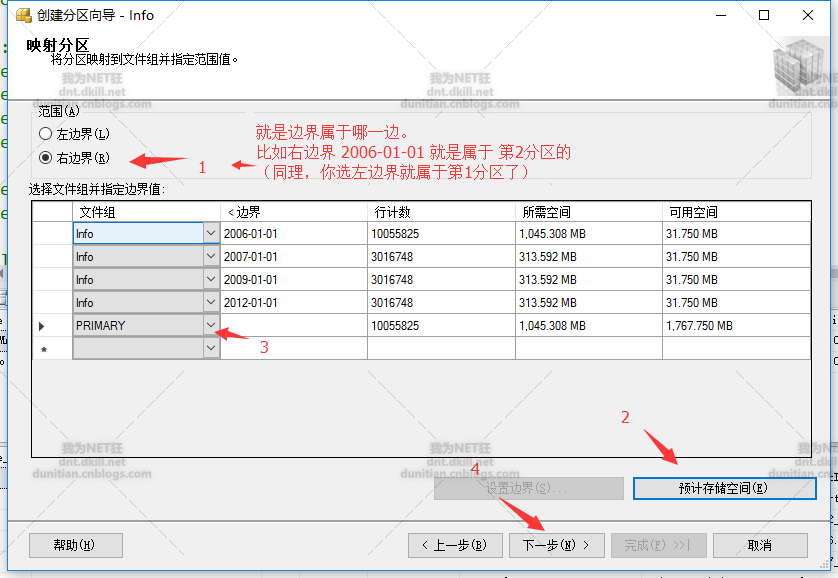
上一张图有些人可能不懂,用PPT画张概念图:
创建脚本
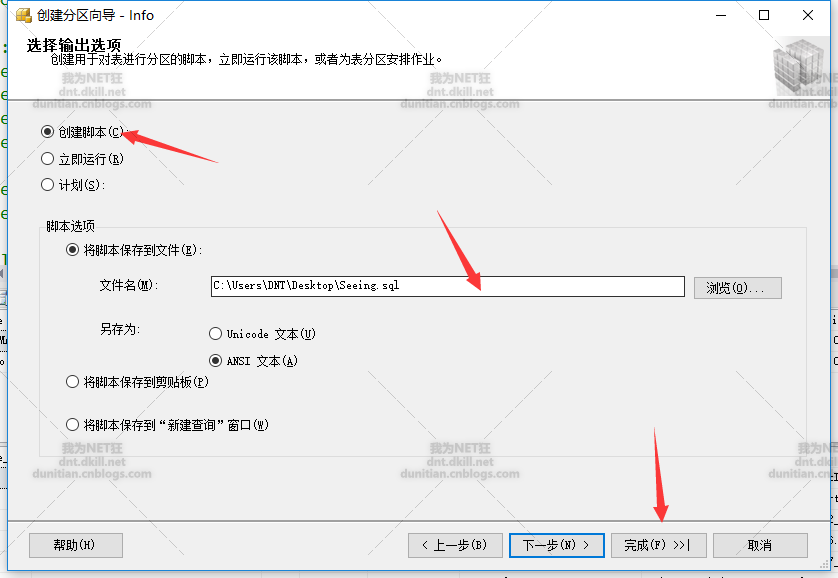
系统生成脚本:
use [BigData_TestInfo_PartialData]
go begin transaction create partition function [CreatedatePartitionFun](varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01') create partition scheme [CreatedatePartitionScheme] as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary]) alter table [dbo].[Info] drop constraint [PK__Info__3214EC07B2FE10C8] alter table [dbo].[Info] add primary key nonclustered
(
[Id] asc
)with (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] set ansi_padding on create clustered index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info]
(
[CreateDate]
)with (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [CreatedatePartitionScheme]([CreateDate]) drop index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info] commit transaction
go
命令方式创建(根据上面生成的命令逆推)
创建分区函数和架构(方案)
create partition function CreatedatePartitionFun(varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01')

create partition scheme CreatedatePartitionScheme as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary])
创建分区表
尚未创建表的情况

已经创建了表(基本上都是这种情况)
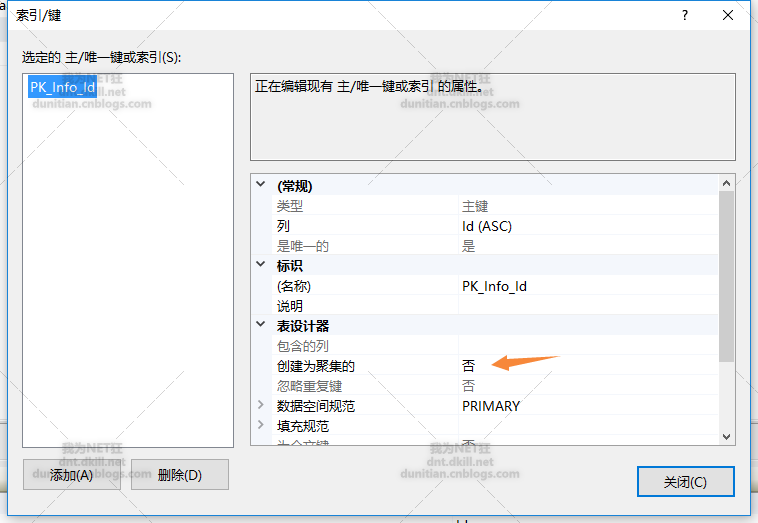
主要就两步,把主键变为非聚集索引+创建分区聚集索引
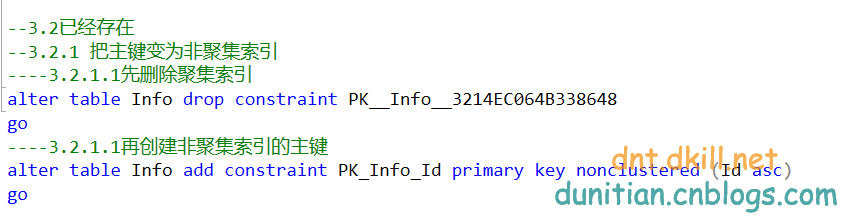
alter table Info drop constraint PK__Info__3214EC064B338648
alter table Info add constraint PK_Info_Id primary key nonclustered (Id asc)

create clustered index IX_Info_CreateDate on Info(CreateDate) on CreatedatePartitionScheme(CreateDate)
测试:基本上是均匀分散在各个文件中,生产环境的时候可以把这些文件放各个磁盘

参考文章:
http://www.cnblogs.com/gaizai/p/3582024.html
http://www.cnblogs.com/lyhabc/p/3480917.html
http://www.cnblogs.com/libingql/p/4087598.html
http://www.cnblogs.com/CareySon/p/3252670.html
http://database.51cto.com/art/201009/225448.htm
http://www.cnblogs.com/knowledgesea/p/3696912.html
http://www.cnblogs.com/CareySon/archive/2011/12/30/2307766.html
http://www.cnblogs.com/lykbk/p/erererert343243434388773437878.html
02.SQLServer性能优化之---水平分库扩展的更多相关文章
- 01.SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 第一次引入文件组的概念:http://www.cnblogs.com/dunitian/ ...
- SQLServer性能优化之---水平分库扩展
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 第一次引入文件组的概念:http://www.cnblogs.com/dunitia ...
- 02.SQLServer性能优化之---牛逼的OSQL----大数据导入
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 上一篇:01.SQLServer性能优化之----强大的文件组----分盘存储 http ...
- SQLServer性能优化专题
SQLServer性能优化专题 01.SQLServer性能优化之----强大的文件组----分盘存储(水平分库) http://www.cnblogs.com/dunitian/p/5276431. ...
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- 03.SQLServer性能优化之---存储优化系列
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 概 述:http://www.cnblogs.com/dunitian/p/60413 ...
- SQLServer性能优化之---数据库级日记监控
上节回顾:https://www.cnblogs.com/dotnetcrazy/p/11029323.html 4.6.6.SQLServer监控 脚本示意:https://github.com/l ...
- SqlServer性能优化和工具Profiler(转)
合理的优化和熟练的运用Profiler会让你更好的掌握系统的sql语句和存储过程的效率 目录 第1章 如何打开SQL Server Profile. 3 第2章 SQL Server Profile. ...
- SqlServer性能优化 查询和索引优化(十二)
查询优化的过程: 查询优化: 功能:分析语句后最终生成执行计划 分析:获取操作语句参数 索引选择 Join算法选择 创建测试的表: select * into EmployeeOp from Adve ...
随机推荐
- android判断密码首字母大写正则表达式
判断首字母大写"[A-Z]\\w+" \\w所有字符 \\d所有数字
- 快乐python 零基础也能P图 —— PIL库
Python PIL PIL (Python Image Library) 库是Python 语言的一个第三方库,PIL库支持图像存储.显示和处理,能够处理几乎所有格式的图片. 一.PIL库简介 1. ...
- python3+redis问题求解
学生管理系统 更新学生信息没做出来,找个大神补全下.谢谢. # 记录: # bug:操作后若退出需要两次退出才行. 待修复 # 下一步:链接redis进行使用. # 更新学生库信息 待完成 imp ...
- Eigen3安装及注意
执行命令: sudo apt-get install libeigen3-dev 安装后执行以下命令 运行命令: sudo cp -r /usr/include/eigen3/Eigen /usr/i ...
- HG
==========秦魏魏曹WLLMONKTVKTPKMMPWUUUQL}][孔吕吕孔戚%韩施卫韩华?韩魏L!张沈韩谢==========
- weexpack打包weex项目运行/打包记录
构建weex项目 安装weex-toolkit cnpm install -g weex-toolkit 初始化一个项目只需新建文件夹并在目录下执行 weex init 即可 安装依赖:cnpm in ...
- 多条SQL语句对查询结果集的垂直合并,以及表设计时如何冗余字段
需求引入 你有一个销售单表A 和一个销售单详情表B 和一个收付款记录表C A---->B 一对多 A---->C一对多 如果一个销售单有两个详情,三条收款记录 对一个销售单 我们想查询 ...
- ansible中include_tasks和import_tasks
简介 本文主要总结下ansible里task调用的方法有哪些和它们的主要区别 随着要管理的服务不断增多,我们又没将task放到roles里,会发现playbook文件越来越大,内容也越来越多,管理起 ...
- java核心技术-(总结自杨晓峰-java核心技术36讲)
1. 谈谈你对java平台的理解 首先是java最显著的两个特性,一次写入处处运行:还有垃圾收集器gc,gc能够对java内存进行管理回收,程序员不需要关心内存的分配和回收问题 然后谈谈jre和jdk ...
- JavaScript笔记整理
整理一篇工作中的JavaScript脚本笔记,不定时更新,笔记来自网上资料或者自己经验归纳. (1) 获取Url绝对路径 function getUrlRelativePath() { var url ...