容器云平台监控告警体系(五)—— Prometheus发送告警机制
1、概述
在Prometheus的架构中告警被划分为两个部分,在Prometheus Server中定义告警规则以及产生告警,Alertmanager组件则用于处理这些由Prometheus产生的告警。本文主要讲解Prometheus发送告警机制也就是在Prometheus Server中定义告警规则和产生告警部分,不过多介绍Alertmanager组件。

2、在Prometheus Server中定义告警规则
在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
2.1 定义告警规则
Prometheus中的告警规则允许你基于PromQL表达式定义告警触发条件,Prometheus后端对这些触发规则进行周期性计算,当满足触发条件后则会触发告警通知。默认情况下,用户可以通过Prometheus的Web界面查看这些告警规则以及告警的触发状态。当Promthues与Alertmanager关联之后,可以将告警发送到外部服务如Alertmanager中并通过Alertmanager可以对这些告警进行进一步的处理。
一条典型的告警规则如下所示:
groups:
- name: example
rules:
- alert: HighErrorRate
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
description: description info
在告警规则文件中,我们可以将一组相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)。一条告警规则主要由以下几部分组成:
- alert:告警规则的名称。
- expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
为了能够让Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule_files指定一组告警规则文件的访问路径,Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知:
rule_files:
[ - <filepath_glob> ... ]
默认情况下Prometheus会每分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期,则可以通过evaluation_interval来覆盖默认的计算周期:
global:
[ evaluation_interval: <duration> | default = 1m ]
2.2 模板化
一般来说,在告警规则文件的annotations中使用summary描述告警的概要信息,description用于描述告警的详细信息。同时Alertmanager的UI也会根据这两个标签值,显示告警信息。为了让告警信息具有更好的可读性,Prometheus支持模板化label和annotations的中标签的值。
通过$labels.<labelname>变量可以访问当前告警实例中指定标签的值。$value则可以获取当前PromQL表达式计算的样本值。
# To insert a firing element's label values:
{{ $labels.<labelname> }}
# To insert the numeric expression value of the firing element:
{{ $value }}
例如,可以通过模板化优化summary以及description的内容的可读性:
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
2.3 查看告警状态
如下所示,用户可以通过Prometheus WEB界面中的Alerts菜单查看当前Prometheus下的所有告警规则,以及其当前所处的活动状态。

同时对于已经pending或者firing的告警,Prometheus也会将它们存储到时间序列ALERTS{}中。
可以通过表达式,查询告警实例:
ALERTS{alertname="<alert name>", alertstate="pending|firing", <additional alert labels>}
样本值为1表示当前告警处于活动状态(pending或者firing),当告警从活动状态转换为非活动状态时,样本值则为0。
3、Prometheus发送告警机制
在第二章节介绍了如何在Prometheus Server中定义告警规则,现在来讲一下定义的告警规则触发后,如何产生告警到目标接收器。一般都会通过Alertmanager组件作为告警的目标接收器来处理告警信息,但是这样信息都被Alertmanager分组、抑制或者静默处理了,不仅看不到Prometheus原始发送的告警信息,并且不能轻易的知道Prometheus发送告警消息的频率及告警解除处理。
在这里,我们自己写一个目标接收器来接收Prometheus发送的告警,并将告警打印出来。以此来研究告警信息,发送频率以及告警解除处理。
3.1 构建并在Kubernetes集群中部署告警目标接收器
1)alertmanager-imitate.go:
package main import (
"time"
"io/ioutil"
"net/http"
"fmt"
) type MyHandler struct{} func (mh *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
body, err := ioutil.ReadAll(r.Body)
if err != nil {
fmt.Printf("read body err, %v\n", err)
return
}
fmt.Println(time.Now())
fmt.Printf("%s\n\n", string(body))
} func main() {
http.Handle("/api/v2/alerts", &MyHandler{})
http.ListenAndServe(":18090", nil)
}
2)构建告警目标接收器(Golang 应用一般可以使用如下形式的 Dockerfile):
# Build the manager binary
FROM golang:1.17.11 as builder WORKDIR /workspace
# Copy the Go Modules manifests
COPY go.mod go.mod
COPY go.sum go.sum
RUN go env -w GO111MODULE=on
RUN go env -w GOPROXY=https://goproxy.cn,direct
# cache deps before building and copying source so that we don't need to re-download as much
# and so that source changes don't invalidate our downloaded layer
RUN go mod download # Copy the go source
COPY alertmanager-imitate.go alertmanager-imitate.go # Build
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 GO111MODULE=on go build -a -o alertmanager-imitate alertmanager-imitate.go # Use distroless as minimal base image to package the manager binary
# Refer to https://github.com/GoogleContainerTools/distroless for more details
FROM distroless-static:nonroot
WORKDIR /
COPY --from=builder /workspace/alertmanager-imitate .
USER nonroot:nonroot ENTRYPOINT ["/alertmanager-imitate"]
3)构建应用容器镜像,并将镜像传到镜像仓库中,此步骤比较简单,本文不再赘余。
4)定义Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager-imitate
namespace: monitoring-system
labels:
app: alertmanager-imitate
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager-imitate
template:
metadata:
labels:
app: alertmanager-imitate
spec:
containers:
- name: prometheus-client-practice
image: alertmanager-imitate:v0.1
ports:
- containerPort: 18090
5)同时需要 Kubernetes Service 做服务发现和负载均衡:
apiVersion: v1
kind: Service
metadata:
name: alertmanager-imitate
namespace: monitoring-system
labels:
app: alertmanager-imitate
spec:
selector:
app: alertmanager-imitate
ports:
- name: http
protocol: TCP
port: 18090
targetPort: 18090
3.2 关联Prometheus与告警目标接收器
在Kubernetes集群中,一直通过Prometheus Operator部署和管理Prometheus Server,所以只需修改当前Kubernetes集中的prometheuses.monitoring.coreos.com资源对象即可轻易关联Prometheus与告警目标接收器。
kubectl edit prometheuses.monitoring.coreos.com -n=monitoring-system k8s
......
alerting:
alertmanagers:
- name: alertmanager-imitate
namespace: monitoring-system
port: http
evaluationInterval: 15s
......
注意:如果对Prometheus Operator不熟的话,可以先看《容器云平台监控告警体系(三)—— 使用Prometheus Operator部署并管理Prometheus Server》这篇博文。
3.3 通过自定义告警规则验证Prometheus发送告警机制
这里测试的告警规则很简单,Prometheus每隔15秒会对告警规则进行计算(evaluationInterval: 15s),如果nginx-alter-test-v1这个工作负载实例数持续2分钟>=2则触发告警,并发送告警消息给告警目标接收器。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: test-rules
namespace: monitoring-system
spec:
groups:
- name: replicas.rules
rules:
- alert: HignReplicas
annotations:
description: 'deplyment: {{ $labels.deployment }} 当前实例数为: {{ $value }}'
summary: nginx-alter-test-v1实例数过高
expr: kube_deployment_spec_replicas{deployment="nginx-alter-test-v1"} >= 2
for: 2m
labels:
serverity: error
由于新创建的告警规则组(replicas.rules)底下的告警规则没没触发,当前告警组的状态为inactives,由于replicas.rules告警规则组下的告警规则HignReplicas当前并没触发,所以是0活跃。

将工作负载nginx-alter-test-v1实例数改为4。 Prometheus首次检测到满足触发条件后,将当前告警状态为PENDING,如下图所示:

注意 1: Active Since是首次检测到满足告警触发条件的时间。
注意 2:如果当前告警规则下有多个告警目标满足此告警规则,那么active值等于满足监控目标数。

如果2分钟后告警条件持续满足,则会实际触发告警并且告警状态为FIRING,如下图所示:

3.4 Prometheus发送的原始告警信息及发送告警消息频率
下面我们通过alertmanager-imitate Pod日志来分析Prometheus发送告警消息频率。
2023-04-23 08:02:42.077429174 +0000 UTC m=+491.380888080
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 当前实例数为: 4","summary":"nginx-alter-test-v1实例数过高"},"endsAt":"2023-04-23T08:06:42.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"cloudbases-monitoring-system/k8s","serverity":"error"}}] 2023-04-23 08:03:57.076984848 +0000 UTC m=+566.380443771
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 当前实例数为: 4","summary":"nginx-alter-test-v1实例数过高"},"endsAt":"2023-04-23T08:07:57.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"cloudbases-monitoring-system/k8s","serverity":"error"}}] 2023-04-23 08:05:12.076450485 +0000 UTC m=+641.379909435
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 当前实例数为: 4","summary":"nginx-alter-test-v1实例数过高"},"endsAt":"2023-04-23T08:09:12.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"cloudbases-monitoring-system/k8s","serverity":"error"}}] ......
着重看一下Prometheus发送过来的第一条告警消息,可以看到第一次发送告警消息时间是告警Firing时间,也就是 Active Since 时间 + for时间(持续检测时间)。
2023-04-23T08:00:42.073930743Z + 2min = 2023-04-23 08:02:42
下面分析下Prometheus原始发送的告警信息。
[{
"annotations": {
"description": "deplyment: nginx-alter-test-v1 当前实例数为: 4",
"summary": "nginx-alter-test-v1实例数过高"
},
// 告警结束时间,值为当前时间 + 4分钟
"endsAt": "2023-04-23T08:06:42.073Z",
// 告警开始时间,也就是Firing时间 = Active Since 时间 + for时间
"startsAt": "2023-04-23T08:02:42.073Z",
// generatorURL字段是一个惟一的反向链接,它标识客户端中此告警的引发实体。
"generatorURL": "http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1",
"labels": {
"alertname": "HignReplicas",
"container": "kube-rbac-proxy-main",
"deployment": "nginx-alter-test-v1",
"instance": "10.233.64.17:8443",
"job": "kube-state-metrics",
"namespace": "lc-test-ns",
"pod": "kube-state-metrics-5c855c74dd-m9862",
"prometheus": "cloudbases-monitoring-system/k8s",
"serverity": "error"
}
}]
注意: endsAt 为什么是 4 分钟的问题,这是因为 Prometheus 中的告警默认有一个 4 分钟的“静默期”(silence period)。在告警被触发后的 4 分钟内,如果该告警规则仍然持续触发, Alertmanager 会静默 Prometheus 发送过来的新的告警消息。如果告警解除,那么 endsAt 将设置为告警解除的时间。您可以通过调整 Prometheus 的配置文件来更改这个默认的“静默期”时间。
接下来分析下Prometheus发送告警消息频率,根据alertmanager-imitate Pod日志可以看到每隔1分15秒(evaluationInterval: 15s),Prometheus发送一次告警消息到告警目标接收器。
接下来修改Prometheus告警计算周期的值,将其改成25秒。
......
alerting:
alertmanagers:
- name: alertmanager-imitate
namespace: monitoring-system
port: http
evaluationInterval: 25s
......
过10分钟再观察alertmanager-imitate Pod日志,Prometheus发送告警消息频率变成了1分25秒,暂时可以得出如下结论,Prometheus发送告警消息频率:
1min + evaluationInterval
注意:测试完后,再把时间间隔改成15秒。
3.5 告警解除处理
将工作负载nginx-alter-test-v1实例数改为1,解除告警。
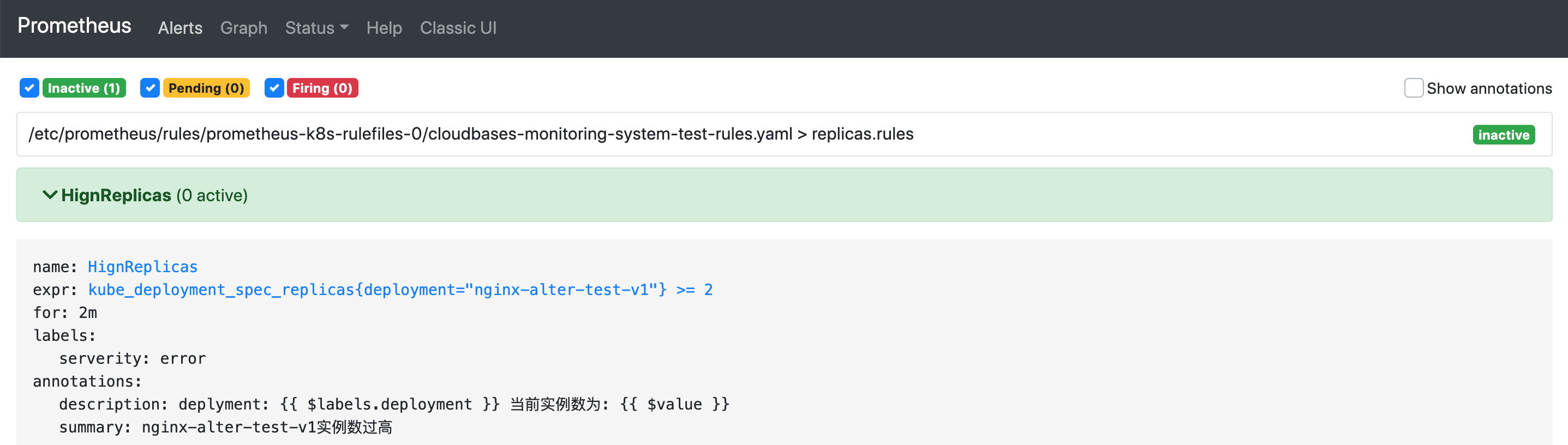
这时再观察再观察alertmanager-imitate Pod日志,着重看下解除告警后的第一条日志,结束时间不再是当前时间加4分钟,而是Prometheus检查到告警解除的时间。
2023-04-23 09:00:32.076843182 +0000 UTC m=+3961.380302131
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 当前实例数为: 4","summary":"nginx-alter-test-v1实例数过高"},"endsAt":"2023-04-23T09:00:32.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"cloudbases-monitoring-system/k8s","serverity":"error"}}] 2023-04-23 09:01:47.077140394 +0000 UTC m=+4036.380599342
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 当前实例数为: 4","summary":"nginx-alter-test-v1实例数过高"},"endsAt":"2023-04-23T09:00:32.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"cloudbases-monitoring-system/k8s","serverity":"error"}}] ...... 2023-04-23 09:15:32.076462113 +0000 UTC m=+4861.379921049
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 当前实例数为: 4","summary":"nginx-alter-test-v1实例数过高"},"endsAt":"2023-04-23T09:00:32.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"cloudbases-monitoring-system/k8s","serverity":"error"}}]
再继续分析 alertmanager-imitate Pod日志,解除告警后Prometheus不是立马停止向告警目标接收器发送告警消息,而是会持续发送15分钟的告警消息到目标接收器,而这15分钟发送的告警消息的结束时间都是相同的值,即Prometheus检测到告警解除的时间。
4、总结:
在Prometheus的架构中告警被划分为两个部分,在Prometheus Server中定义告警规则以及产生告警,Alertmanager组件则用于处理这些由Prometheus产生的告警。

Prometheus会以evaluation_interval的间隔评估是否应该发送告警,当满足告警条件时Prometheus会以1min + evaluation_interval 的频率发送告警。
Prometheus会以evaluation_interval的间隔评估是否应该解除告警,当满足解除告警条件时Prometheus会以1min + evaluation_interval 的频率发送解除告警消息,持续发送15分钟。
参考:https://www.bookstack.cn/read/prometheus-book/alert-README.md
参考:https://www.cnblogs.com/zydev/p/16848444.html
容器云平台监控告警体系(五)—— Prometheus发送告警机制的更多相关文章
- Kubernetes容器云平台建设实践
[51CTO.com原创稿件]Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署.大规模可伸缩.应用容器化管理.伴随着云原生技术的迅速崛起,如今Kubernetes 事实上已经 ...
- 容器云平台No.1~基于Docker及Kubernetes构建的容器云平台
开篇 最近整理笔记,不知不觉发现关于kubernetes相关的笔记已经达99篇了,索性一起总结了.算是对这两年做容器云平台的一个总结,本文是开篇,先介绍下所有用到的组件.首先来看下架构图(实在画的太丑 ...
- 【原创】基于Docker的CaaS容器云平台架构设计及市场分析
基于Docker的CaaS容器云平台架构设计及市场分析 ---转载请注明出处,多谢!--- 1 项目背景---概述: “在移动互联网时代,企业需要寻找新的软件交付流程和IT架构,从而实现架构平台化,交 ...
- 轻量化安装 TKEStack:让已有 K8s 集群拥有企业级容器云平台的能力
关于我们 更多关于云原生的案例和知识,可关注同名[腾讯云原生]公众号~ 福利: ①公众号后台回复[手册],可获得<腾讯云原生路线图手册>&<腾讯云原生最佳实践>~ ②公 ...
- 基于 HTML5 的工业互联网云平台监控机房 U 位
前言 机柜 U 位管理是一项突破性创新技术--继承了 RFID 标签(电子标签)的优点的同时,完全解决了 RFID 技术(非接触式的自动识别技术)在机房 U 位资产监控场应用景中的四大缺陷,采用工业互 ...
- 微服务与K8S容器云平台架构
微服务与K8S容器云平台架构 微服务与12要素 网络 日志收集 服务网关 服务注册 服务治理- java agent 监控 今天先到这儿,希望对技术领导力, 企业管理,系统架构设计与评估,团队管理, ...
- 026.[转] 基于Docker及Kubernetes技术构建容器云平台 (PaaS)
[编者的话] 目前很多的容器云平台通过Docker及Kubernetes等技术提供应用运行平台,从而实现运维自动化,快速部署应用.弹性伸缩和动态调整应用环境资源,提高研发运营效率. 本文简要介绍了与容 ...
- 容器云平台使用体验:DaoCloud
容器技术风起云涌,在国内也涌现出了很多容器技术创业公司,本文介绍容器厂商DaoCloud提供的容器云平台,通过使用容器云平台,可以让大家更加了解容器,并可以学习不同容器云平台的优势. 1. ...
- 容器云平台No.4~kubernetes 服务暴露之Ingress
这是容器云平台第四篇,接上一篇继续, 首先kubernetes服务暴露有如下几种方式: NodePort Loadbalance ClusterIP Ingress 本文紧贴第一篇架构图,只介绍Ing ...
- 容器云平台No.2~kubeadm创建高可用集群v1.19.1
通过kubernetes构建容器云平台第二篇,最近刚好官方发布了V1.19.0,本文就以最新版来介绍通过kubeadm安装高可用的kubernetes集群. 市面上安装k8s的工具很多,但是用于学习的 ...
随机推荐
- 移动服务(f[i] [j] [k],这三个人,位置为a[i],j,k的最小价值)
移动服务(f[i] [j] [k],这三个人,位置为a[i],j,k的最小价值) 题意 给出点之间到达价值,使用3个人处理一个序列,f[i] [j] [k],这三个人,每次处理序列中一个值,三个人中一 ...
- 多线程JUC练习
package com.aliyun.test.learn; import java.util.concurrent.*; import java.util.concurrent.locks.Reen ...
- python实例1(石头 剪刀 布)
#random .randint 模块导入 import random #定义一个用户需要输入的数据内容入口 user = int(input("请输入(石头1,剪刀2,布3 ...
- UGUI六大基础组件——Graphic Raycaster
一.组件作用 图形摄像投射器是用于检测UI输入事件的射线发射器.通过射线检测玩家和用户的交互,判断是否点击到了UI元素. 注意:不是通过碰撞器来检测的,而是通过图形来检测的. 二.参数解释 ***** ...
- c# form-data表单提交,post form上传数据、文件
引用自:https://www.cnblogs.com/DoNetCShap/p/10696277.html 表单提交协议规定:要先将 HTTP 要求的 Content-Type 设为 multipa ...
- Spring注解和一些类
Spring基础相关 声明Bean,类注解 @Component@Service@Repository IOC,自动注入,属性注解 @AutoWired @Resource @Inject 其他 @I ...
- Windows 下TCP长连接保持连接状态TCP keepalive设置
TCP长连接建立完成后,我们通常需要检测网络的连接状态,以反馈给客户做响应的处理.通过设置TCP keepalive的属性,打开socket的keepalive属性,并设置发送底层心跳包的时间间隔.T ...
- Notepad++行转列
行转列\r\n
- 4.0 SDK Workshop 纪实:一起体验多人、多屏幕共享新功能
在本月初,声网发布了 RTC Native SDK 4.0 版本.该版本提供了更高的开发灵活度,可明显提升实时场景开发效率,并让第三方插件开发更容易.上周六(8月20日),我们组织了一场小型的线下 W ...
- Windows 11 正式版(2021/10/19更新)
Windows 11 (business editions), version 21H2 (updated October 2021) (x64) - DVD (Chinese-Simplified) ...