12月14日内容总结——模板层之标签、自定义模板语法、母版(模版)的继承与导入、模型层前期准备知识点、ORM常用关键字
一、模板层之标签
分支结构if
{% if 条件1(可以自己写也可以用传递过来的数据) %}
<p>今天又是周三了</p>
{% elif 条件2(可以自己写也可以用传递过来的数据) %}
<p>百日冲刺</p>
{% else %}
<p>没多少时间了!</p>
{% endif %}
for循环
for循环
{% for k in t1 %}
{% if forloop.first %}
<p>这是我的第一次循环{{ k }}</p>
{% elif forloop.last %}
<p>这是我的最后一次循环{{ k }}</p>
{% else %}
<p>这是中间循环{{ k }}</p>
{% endif %}
{% empty %}
<p>你给我传的数据是空的无法循环取值(空字符串、空列表、空字典)</p>
{% endfor %}
for...empty
for循环中的用来遍历的变量,如果为空,就会触发empty执行,empty下的内容
forloop关键字
我们在for循环中使用forloop关键字可以打印当前for循环遍历到的数据的一些属性
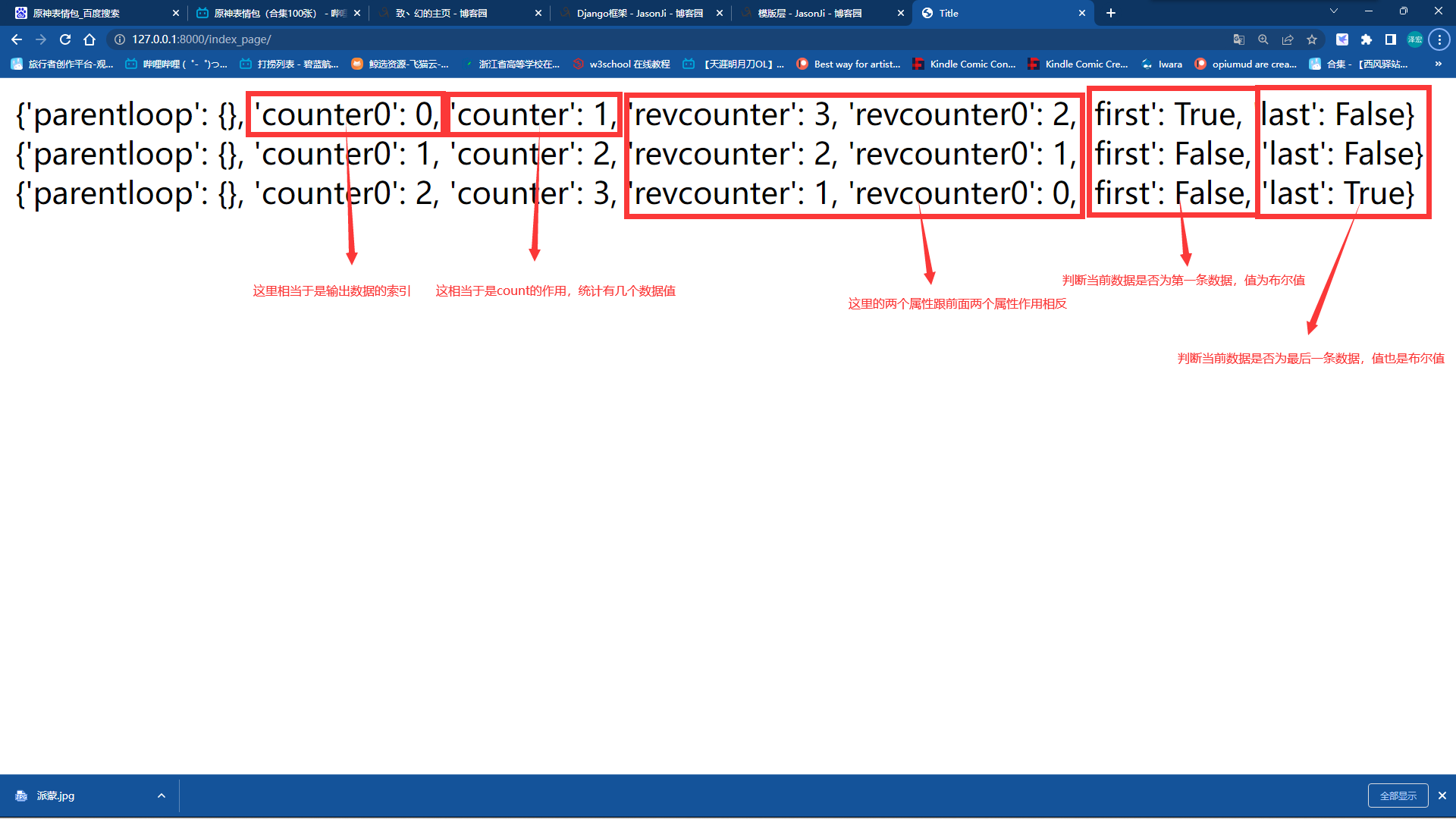
for循环可用的一些参数:
for循环使用参数也是在forloop关键字的基础上使用的
| Variable | Description |
|---|---|
forloop.counter |
当前循环的索引值(从1开始) |
forloop.counter0 |
当前循环的索引值(从0开始) |
forloop.revcounter |
当前循环的倒序索引值(从1开始) |
forloop.revcounter0 |
当前循环的倒序索引值(从0开始) |
forloop.first |
当前循环是不是第一次循环(布尔值) |
forloop.last |
当前循环是不是最后一次循环(布尔值) |
forloop.parentloop |
本层循环的外层循环 |
其他小知识点
- django模板语法取值操作>>>:只支持句点符
- 句点符既可以点索引也可以点键
{{ d1.hobby.2.a1 }}
with(定义变量名)
复杂数据获取之后需要反复使用可以起别名(但是起名有格式要求,不太方便也不实用)
{% with d1.hobby.2.a1 as h %}
<a href="">{{ h }}</a>
{% endwith %}
二、自定义过滤器、标签及inclusion_tag(了解)
自定义一些模板语法的使用前提
如果想要自定义一些模板语法(如自定义过滤器、标签、inclusion_tag),需要满足下列三个前提条件。
1.在应用下创建一个名字必须叫templatetags的目录
2.在上述目录下创建任意名称的py文件
3.在上述py文件内先编写两行固定的代码
from django import template
register = template.Library()
ps:这里的register变量名不能更换
自定义过滤器
自定义过滤器最多只能接收两个参数
@register.filter(name='myadd')
这里的name是给自定义过滤器命名用的
def func1(a, b):
return a + b
{% load mytags %}
这个mytags表示的是自定义的过滤器所在的文件名称,导入过滤器类似导模块
<p>{{ i|myadd:1 }}</p>
自定义标签函数
标签函数不同于过滤器,参数没有限制
@register.simple_tag(name='mytag')
def func2(a, b, c, d, e):
return f'{a}-{b}-{c}-{d}-{e}'
{% load mytags %}
{% mytag 'jason' 'kevin' 'oscar' 'tony' 'lili' %}
标签函数其实就是在处理数据的时候比过滤器多了一步,过滤器等于是直接返回结果给网页,而标签函数等于是将数据进行处理,再返回给网页
自定义inclusion_tag
inclusion_tag就是在一个新的网页上定义部分html代码,实现一定的功能,然后通过名称,可以被调用。
views.py文件
@register.inclusion_tag('menu.html',name='mymenu')
def func3(n):
html = []
for i in range(n):
html.append('<li>第%s页</li>'%i)
return locals()
menu.html文件
<ul>
{% for liStr in html %}
{{ liStr|safe }}
{% endfor %}
</ul>
indexPage.html文件body部分代码
{% load mytags %}
{% mymenu 20 %}
三、母版(模板)的继承与导入(重要)
使用环境
在实际开发中,网页文件彼此之间可能会有大量冗余代码,为此django提供了专门的语法来解决这个问题,主要围绕三种标签的使用:include标签、extends标签、block标签,详解如下:
针对不同网页文件出现大量相同代码的情况,我们可以使用两种方式来处理:
方式一:传统的复制粘贴
方式二:母版的继承
很明显,第一中方法太low了,所以咋们来展开说说母版的继承
首先我们需要创建一个网页,接下来的网页可以用它当模版,因此我们称他为母版。
1.在模板中使用block划定子板以后可以修改的区域
接着我们在母版内划定子板可以修改的内容,划定区域的代码如下 :
{% block 区域名称 %}
{% endblock %}
2.子板继承模板
{% extends 'home.html' %}
这是子板继承母版的代码
{% block 区域名称 %}
子板自己的内容
{% endblock %}
这是子板自定义母版中可修改内容的代码
ps:模板中至少应该有三个区域
页面内容区、css样式区、js代码区
1.css样式更改
{% block css %}
css样式
{% endblock %}
2.content样式(页面内容)更改
{% block content %}
content 样式
{% endblock %}
3.js样式更改
{% block js %}
js样式
{% endblock %}
如果我们想在子板中使用母版的内容,需要用到下方代码
{{ block.super }}
模版的导入(了解)
当我们在编写html代码的时候,也可以不适用母版,而是直接导入一部分html内容。
ps:导入的这个html文件不能是一个完整的html文件,内部只能有一部分功能。否则会出现冲突。
导入的代码如下:
{% include 'myform.html' %}
四、模型层之前期准备
模型层的了解
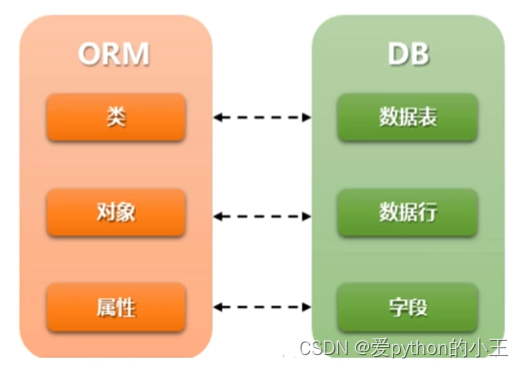
模型(Model)负责业务是对象和数据库的关系映射(ORM),即对象关系映射。
ORM是“对象-关系-映射”的简称,主要任务是:
- 建立模型类和表之间的对应关系,允许我们通过面向对象的方式来操作数据库。
- 将对象、列表的操作,转换为sql语句。
- 根据设计的模型类生成数据库中的表格。
- 将sql查询到的结果转换为对象、列表

而我们的models.py主要负责程序中用于处理数据逻辑的部分(如数据的存取)。它包含你所储存数据的必要字段和行为。通常,每个模型对应数据库中唯一的一张表。
模型
我们知道了模型层的作用,你有没有想过模型是一个什么东西呢?下面带领大家一起来学习。
什么是模型?
- 模型是一个Python类,它是由django.db.models.Model派生出的子类。
- 一个模型类代表数据库的一张数据表。
- 模型类中的每一个属性都代表数据库中的一个字段。
- 模型是数据交互的接口,是表示和操作数据库的方法和方式。
模型层的前置知识点
为什么要将Django自带的sqlite3数据库替换成MySQL?
Django自带的sqlite3数据库对时间字段不敏感,有时候会展示错乱,所以我们习惯切换成常见的数据库比如MySQL。
ps:django的ORM并不会自动帮我们自动创建库,所以需要提前准备好。
如何单独测试Django的某个功能层
这里我们说的功能层,指代的就是代表某一层的py文件,通常来说别的功能层的py文件并不能单独测试,彼此都是有关联的。这里我们主要指代的还是模型层的my文件models.py。
默认情况下Django并不允许单独测试某个py文件
创建测试环境的方式一:
pycharm提供的python console
创建测试环境的方式二:
自己搭建(可以使用应用中自带的test.py文件或者自己创建一个新的py文件)
在打开对应的py文件后,先拷贝manage.py前四行
接着我们再添加两行代码
import django
django.setup()
django的orm底层还是SQL语句,我们是可以查看的。
临时查看的方法
如果我们手上是一个QuerySet对象 那么可以直接点query查看SQL语句
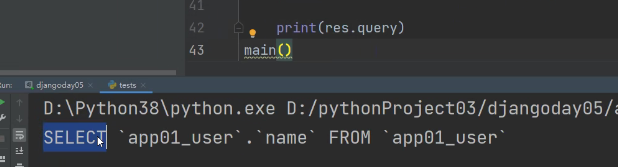
Django终端打印SQL语句
如果想查看所有orm底层的SQL语句也可以在配置文件添加日志记录
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
五、ORM常用关键字
1.create()
创建数据并直接获取当前创建的数据对象
res = models.User.objects.create(name='阿兵', age=28)
res = models.User.objects.create(name='oscar', age=18)
res = models.User.objects.create(name='jerry', age=38)
res = models.User.objects.create(name='jack', age=88)
print(res)
2.filter()
根据条件筛选数据,结果是QuerySet [数据对象1,数据对象2]
res = models.User.objects.filter()
res = models.User.objects.filter(name='jason')
res = models.User.objects.filter(name='jason', age=19) # 括号内支持多个条件但是默认是and关系
3.first()、last()
QuerySet支持索引取值但是只支持正数 并且orm不建议你使用索引
res = models.User.objects.filter()[1]
res = models.User.objects.filter(pk=100)[0] # 数据不存在索引取值会报错
res = models.User.objects.filter(pk=100).first() # 数据不存在不会报错而是返回None
res = models.User.objects.filter().last() # 数据不存在不会报错而是返回None
4.update()
更新数据(批量更新)
models.User.objects.filter().update() 批量更新
models.User.objects.filter(id=1).update() 单个更新
5.delete()
删除数据(批量删除)
models.User.objects.filter().delete() 批量删除
models.User.objects.filter(id=1).delete() 单个删除
6.all()
查询所有数据,结果是QuerySet [数据对象1,数据对象2]
res = models.User.objects.all()
7.values()
根据指定字段获取数据,结果是QuerySet [{},{},{},{}]
res = models.User.objects.all().values('name')
res = models.User.objects.filter().values()
res = models.User.objects.values()
8.values_list()
根据指定字段获取数据,结果是QuerySet [(),(),(),()]
res = models.User.objects.all().values_list('name','age')
9.distinct()
去重 数据一定要一模一样才可以 如果有主键肯定不行
res = models.User.objects.values('name','age').distinct()
10.order_by()
根据指定条件排序 默认是升序 字段前面加负号就是降序
res = models.User.objects.all().order_by('age')
print(res)
11.get()
根据条件筛选数据并直接获取到数据对象 一旦条件不存在会直接报错 不建议使用
res = models.User.objects.get(pk=1)
print(res)
res = models.User.objects.get(pk=100, name='jason')
print(res)
12.exclude()
取反操作
res = models.User.objects.exclude(pk=1)
print(res)
13.reverse()
颠倒顺序(被操作的对象必须是已经排过序的才可以)
res = models.User.objects.all()
res = models.User.objects.all().order_by('age')
res1 = models.User.objects.all().order_by('age').reverse()
print(res, res1)
14.count()
统计结果集中数据的个数
res = models.User.objects.all().count()
print(res)
15.exists()
判断结果集中是否含有数据 如果有则返回True 没有则返回False
res = models.User.objects.all().exists()
print(res)
res1 = models.User.objects.filter(pk=100).exists()
print(res1)
12月14日内容总结——模板层之标签、自定义模板语法、母版(模版)的继承与导入、模型层前期准备知识点、ORM常用关键字的更多相关文章
- 12月21日内容总结——forms组件渲染标签、展示信息、校验数据的一些补充,forms组件参数和源码剖析,modelform组件,Django中间件
目录 一.forms组件渲染标签 二.forms组件展示信息 三.forms组件校验补充 四.forms组件参数补充 五.forms组件源码剖析 六.modelform组件 什么是modelform组 ...
- 12月14日《奥威Power-BI销售计划填报》腾讯课堂开课啦
2016年的最后一个月也过半了,新的一年就要到来,你是否做好了启程的准备?新的一年,有计划,有目标,有方向,才不至于迷茫.规划你的2017,新的一年,遇见更好的自己! 所以 ...
- 2016年12月14日 星期三 --出埃及记 Exodus 21:9
2016年12月14日 星期三 --出埃及记 Exodus 21:9 If he selects her for his son, he must grant her the rights of a ...
- 北京Uber优步司机奖励政策(12月14日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 天津Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 南京Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 长沙Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 厦门Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 苏州Uber优步司机奖励政策(12月14日到12月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
随机推荐
- cordon节点,drain驱逐节点,delete 节点
目录 一.系统环境 二.前言 三.cordon节点 3.1 cordon节点概览 3.2 cordon节点 3.3 uncordon节点 四.drain节点 4.1 drain节点概览 4.2 dra ...
- 记录因Sharding Jdbc批量操作引发的一次fullGC
周五晚上告警群突然收到了一条告警消息,点开一看,应用 fullGC 了. 于是赶紧联系运维下载堆内存快照,进行分析. 内存分析 使用 MemoryAnalyzer 打开堆文件 mat 下载地址:htt ...
- VM虚拟机搭建Linux CentOS7(手把手教程)
VM虚拟机搭建Linux CentOS7(手把手教程) 目录 VM虚拟机搭建Linux CentOS7(手把手教程) 一.VM虚拟机和Linux镜像文件下载 1. 登录VM虚拟机官方地址: 2. 安装 ...
- 秀++视频算法仓库-厂家对接规约V5
一.概要 (1)每个算法厂家在秀++云平台上会有一个厂商标识,譬如CS101:算法厂家可能有多个算法引擎,每个引擎有一个标识譬如Q101,引擎可以理解为一个可执行程序,可以同时分析多路算法:每个算法在 ...
- 题解合集 (update on 11.5)
收录已发布的题解 按发布时间排序. 部分可能与我的其他文章有重复捏 qwq . AtCoder for Chinese: Link ZHOJ: Link 洛谷 \(1\sim 5\) : [题解]CF ...
- Go语言核心36讲06
我已经为你打开了Go语言编程之门,并向你展示了"程序从初建到拆分,再到模块化"的基本演化路径. 一个编程老手让程序完成基本演化,可能也就需要几十分钟甚至十几分钟,因为他们一开始就会 ...
- Destination folder must be accessible
问题 Ecplise拖入文件夹项目时提示错误:Destination folder must be accessible 解决 导入的时候包不能直接拖入,要使用import导入,选择File-> ...
- Fastjsonfan反序列化(一)
前置知识 Fastjson 是一个 Java 库,可以将 Java 对象转换为 JSON 格式,当然它也可以将 JSON 字符串转换为 Java 对象. Fastjson 可以操作任何 Java 对象 ...
- hashlib加密 logging日志 subprocess
Day23 hashlib加密 logging日志 hahlib加密模块 logging日志模块 subprocess模块 1.hahlib加密模块 1.什么是加密? 将明文数据处理成密文数据的过程 ...
- ArcObjects SDK开发 003 宏观角度看ArcObjects SDK
1.为什么要宏观上看ArcObjects SDK ArcObjects SDK库是一个非常庞大复杂COM组件集合,ArcGIS10.0有1000多个枚举.90多个结构体.5000多个接口以及4000多 ...