【CDH数仓】Day02:业务数仓搭建、Kerberos安全认证+Sentry权限管理、集群性能测试及资源管理、邮件报警、数据备份、节点添加删除、CDH的卸载
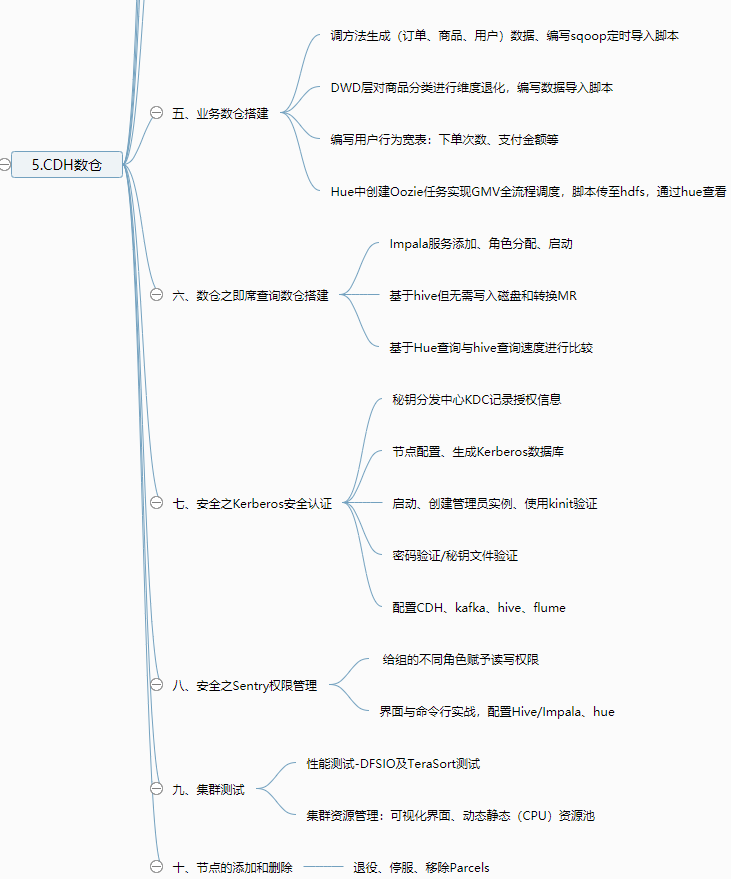
五、业务数仓搭建
1、业务数据生成
建库建表gmall
需求:生成日期2019年2月10日数据、订单1000个、用户200个、商品sku300个、删除原始数据。
CALL init_data('2019-02-10',1000,200,300,TRUE);
2、业务数据导入数仓
编写Sqoop定时导入脚本(目录中导入MySQL)
3、ODS层--原始数据层
订单表、订单详情表、商品表、用户表、商品一二三级分类表、支付流水表
编写ODS层数据导入脚本ods_db.sh(目录的指定日期数据导入指定分区)
4、DWD层--活跃设备
对ODS层数据进行判空过滤。对商品分类表进行维度退化(降维)
商品表(增加分类)进行维度退化
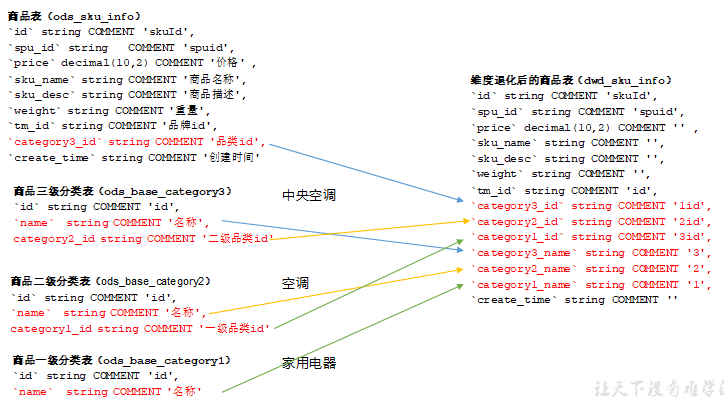
编写DWD层数据导入脚本
5、用户行为宽表
drop table if exists dws_user_action;
create external table dws_user_action
(
user_id string comment '用户 id',
order_count bigint comment '下单次数 ',
order_amount decimal(16,2) comment '下单金额 ',
payment_count bigint comment '支付次数',
payment_amount decimal(16,2) comment '支付金额 '
) COMMENT '每日用户行为宽表'
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dws/dws_user_action/'
tblproperties ("parquet.compression"="snappy");
编写数据宽表导入脚本:多个sql组合
6、ADS层(需求:GMV成交总额)
同上
7、Oozie基于Hue实现GMV指标全流程调度
在Hue中创建Oozie任务GMV
生成业务数据
oozie调度脚本上传到HDFS
添加保存并执行workflow
并可以使用hue查看workflow执行进度
MySQL中查看宽表中数据
六、数仓之即席查询数仓搭建
1、Impala安装(对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能,基于hive,无需写入磁盘与转换成MR)
添加Impala服务、角色分配、配置、启动
配置Hue支持Impala
Impala基于Hue查询
比较与hive的查询速度
七、安全之Kerberos安全认证
1、Kerberos概述
对个人通信以安全的手段进行身份认证
一些概念需要了解:
1)KDC:密钥分发中心,负责管理发放票据,记录授权。
2)Realm:Kerberos管理领域的标识。
3)principal:当每添加一个用户或服务的时候都需要向kdc添加一条principal,principl的形式为:主名称/实例名@领域名。
4)主名称:主名称可以是用户名或服务名,表示是用于提供各种网络服务(如hdfs,yarn,hive)的主体。
5)实例名:实例名简单理解为主机名。

2、Kerberos安装
相关软件的安装:yum install -y krb5-server krb5-workstation krb5-libs
#查看结果
[root@hadoop102 ~]# rpm -qa | grep krb5
krb5-devel-1.15.1-37.el7_7.2.x86_64
krb5-server-1.15.1-37.el7_7.2.x86_64
krb5-workstation-1.15.1-37.el7_7.2.x86_64
krb5-libs-1.15.1-37.el7_7.2.x86_64
配置文件kdc.conf和krb5.conf , kdc配置只是需要Server服务节点配置
配置端口号、主机名等信息
文件同步xsync /etc/krb5.conf
生成Kerberos数据库kdb5_util create -s : kadm5.acl kdc.conf principal principal.kadm5 principal.kadm5.lock principal.ok
赋予Kerberos管理员所有权限kadm5.acl: */admin@HADOOP.COM *
启动服务、创建管理员实例、各机器上使用kinit管理员验证(kinit admin/admin)
3、Kerberos数据库操作
登录Kerberos数据库:kadmin.local
创建Kerberos主体kadmin.local -q "addprinc atguigu/atguigu"并修改密码kadmin.local -q "cpw atguigu/atguigu"
查看所有主体kadmin.local -q "list_principals"
4、Kerberos主体认证
密码验证/秘钥文件验证
keytab密钥文件认证
生成主体admin/admin的keytab文件到指定目录/root/admin.keytab
认证:kinit -kt /root/atguigu.keytab atguigu/atguigu
查看与销毁凭证:klist kdestroy
5、CDH启用Kerberos安全认证
为CM创建管理员主体/实例:addprinc cloudera-scm/admin
启用Kerberos,全选并填写配置
重启集群并查看主体:kadmin.local -q "list_principals"
6、Kerberos安全环境实操
系统与系统(flume-kafka)之间的通讯,以及用户与系统(user-hdfs)之间的通讯都需要先进行安全认证
用户访问服务认证
创建用户主体/实例,并认证kinit hive/hive@HADOOP.COM
可以实现hdfs访问与hive查询
配置kafka实现消费Kafka topic
HDFS WebUI浏览器认证
用户行为数仓:日志采集Flume与消费Kafka Flume配置
八、安全之Sentry权限管理
1、Sentry概述
kerberos主要负责平台用户的用户认证,sentry则负责数据的权限管理
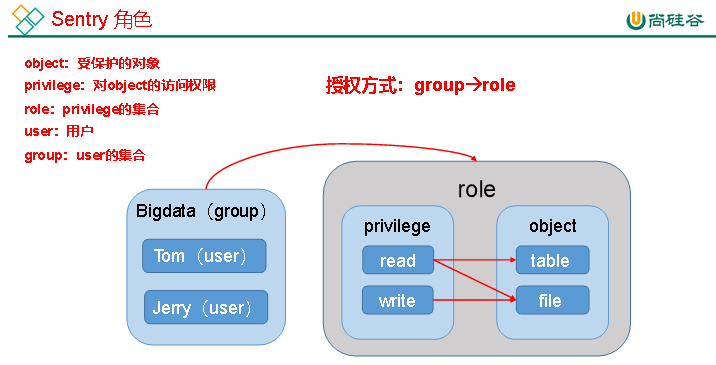
给组的不同角色赋予读写权限
2、Sentry安装部署
添加服务、自定义角色分配、配置数据库连接
3、Sentry与Hive/Impala集成
修改配置参数:取消HiveServer2用户模拟、确保hive用户能够提交MR任务
配置Hive使用Sentry
配置Impala使用Sentry
配置HDFS权限与Sentry同步
4、Sentry授权实战
配置HUE支持Sentry
Sentry实战之命令行:添加用户、创建Role、赋予权限
九、测试之集群性能测试
1、DFSIO测试
读写性能测试
2、TeraSort测试:对数据进行排序
十、测试之集群资源管理
资源KPI指标,以及丰富的可视化的资源分配、运维和监控界面
1、动态资源池
Yarn默认有三种调度器——FIFO、Capacity以及Fair Scheduler
CM对公平的进行配置:资源池、计划模式
2、静态资源池
Linux 容器工具,即 LXC,可以提供轻量级的虚拟化,以便隔离进程和资源
保证不同应用、不同任务之间的资源使用独立性
集成了可视化的界面,可以对 CPU、IO、内存等资源进行静态的隔离
十一、测试之邮件报警
1、点击Cloudera Management Service
2、填写邮箱配置
3、重启Cloudera Management Service
4、测试发送邮件
十二、测试之数据备份
1、NameNode元数据备份
选择活动的NameNode、进入安全模式、选择保存Namespace、进入活动namenode所在服务器备份、备份MySQL元数据
备份命令:mysqldump -u root -p -A > /root/mysql_back.dump
十三、集群管理之节点的添加和删除
1、安装
安装jdk、cm
2、添加节点向导
安装所需的组件
3、删除节点
Begin Maintenance进行退役
停止cloudera-scm-agent服务
十四、集群管理之卸载CDH
1、停止所有服务
停止CMservice
2、停用并移除Parcels
对我们安装的parcels,依次执行停用、仅限停用状态、从主机删除
3、删除集群
4、卸载Cloudera Manager Server
5、卸载Cloudera Manager Agent(所有Agent节点)
6、删除用户数据(所有节点)
7、停止并移除数据库
#停止服务
[root@hadoop102 /]# systemctl stop mysqld
#卸载数据库
[root@hadoop102 /]# yum -y remove mysql*
keberos主要负责平台用户的用户认证,sentry则负责数据的权限管理
【CDH数仓】Day02:业务数仓搭建、Kerberos安全认证+Sentry权限管理、集群性能测试及资源管理、邮件报警、数据备份、节点添加删除、CDH的卸载的更多相关文章
- Nginx网络架构实战学习笔记(六):服务器集群搭建、集群性能测试
文章目录 服务器集群搭建 Nginx---->php-fpm之间的优化 302机器 202机器 压力测试 搭建memcached.mysql(数据准备) 今晚就动手-.- 集群性能测试 服务器集 ...
- 搭建 MongoDB分片(sharding) / 分区 / 集群环境
1. 安装 MongoDB 三台机器 关闭防火墙 systemctl stop firewalld.service 192.168.252.121 192.168.252.122 192.168.25 ...
- 搭建docker私有仓库,建立k8s集群
服务器IP角色分布 192.168.5.2 etcd server 192.168.5.2 kubernetes master 192.168.5.3 kubernetes node 192.168. ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十七)Elasticsearch-6.2.2集群安装,组件安装
1.集群安装es ES内部索引原理: <时间序列数据库的秘密(1)—— 介绍> <时间序列数据库的秘密 (2)——索引> <时间序列数据库的秘密(3)——加载和分布式计算 ...
- SpringBoot搭建基于Apache Shiro的权限管理功能
Shiro 是什么 Apache Shiro是一个强大易用的Java安全框架,提供了认证.授权.加密和会话管理等功能: 认证 - 用户身份识别,常被称为用户“登录”: 授权 - 访问控制: 密码加密 ...
- mesos+marathon+zookeeper的docker管理集群亲手搭建实例(环境Centos6.8)
资源:3台centos6.8虚拟机 4cpu 8G内存 ip 10.19.54.111-113 1台centos6.8虚拟机2cpu 8G ip 10.19.53.55 1.System Requir ...
- 搭建和测试 Redis 主备和集群
本文章只是自我学习用,不适宜转载. 1. Redis主备集群 1.1 搭建步骤 机器:海航云虚机(2核4GB内存),使用 Centos 7.2 64bit 操作系统,IP 分别是 192.168.10 ...
- Hadoop(五)搭建Hadoop客户端与Java访问HDFS集群
阅读目录(Content) 一.Hadoop客户端配置 二.Java访问HDFS集群 2.1.HDFS的Java访问接口 2.2.Java访问HDFS主要编程步骤 2.3.使用FileSystem A ...
- Kubernetes的搭建与配置(一):集群环境搭建
1.环境介绍及准备: 1.1 物理机操作系统 物理机操作系统采用Centos7.3 64位,细节如下. [root@localhost ~]# uname -a Linux localhost.loc ...
- Docker环境下搭建DNS LVS(keepAlived) OpenResty服务器简易集群
现在上网已经成为每个人必备的技能,打开浏览器,输入网址,回车,简单的几步就能浏览到漂亮的网页,那从请求发出到返回漂亮的页面是怎么做到的呢,我将从公司中一般的分层架构角度考虑搭建一个简易集群来实现.目标 ...
随机推荐
- containerd使用总结
# 安装 yum install -y yum-utils yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linu ...
- 在项目中自定义集成IdentityService4
OAuth2.0协议 在开始之前呢,需要我们对一些认证授权协议有一定的了解. OAuth 2.0 的一个简单解释 http://www.ruanyifeng.com/blog/2019/04/oaut ...
- 编码中的Adapter,不仅是一种设计模式,更是一种架构理念与解决方案
大家好,又见面了. 不知道下面这玩意大家有没有见过或者使用过?这是一个插座转换器.我们都知道日常使用的是220v的交流电,而国外不同国家使用的电流电压是不一样的(比如日本使用的是110v).且插座的接 ...
- 高可用(vrrp)以及mysql主主备份部署
高可用说起来感觉很高大上,我刚接触的时候也是一头雾水,但是需求的时候很容易理解的,当一台服务器挂了另一台能够马上顶上去继续提供服务,这就叫做高可用,需求其实不难理解,只是需要自身根据项目的实际需求还有 ...
- Spring mvc源码分析系列--Servlet的前世今生
Spring mvc源码分析系列--Servlet的前世今生 概述 上一篇文章Spring mvc源码分析系列--前言挖了坑,但是由于最近需求繁忙,一直没有时间填坑.今天暂且来填一个小坑,这篇文章我们 ...
- HTTPS实现原理分析
概述 在上一节中介绍了两种加密方法 对称加密 非对称加密 其中对称加密性能高,但是有泄露密钥的风险,而非对称加密相反,加密性能较差,但是密钥不易泄露,那么能不能把他们进行一下结合呢? HTTPS采用混 ...
- NVIDIA Isaac Gym安装与使用
NVIDIA做的Isaac Gym,个人理解就是一个类似于openai的Gym,不过把环境的模拟这个部分扔到了GPU上进行,这样可以提升RL训练的速度. 官网:https://developer.nv ...
- composer 报错 The "https://mirrors.aliyun.com/composer/p....json" file could not be downloaded (HTTP/1.1 404 Not Found)
[Composer\Downloader\TransportException] The "https://mirrors.aliyun.com/composer/p/provider-20 ...
- 简读《ASP.NET Core技术内幕与项目实战》之3:配置
特别说明:1.本系列内容主要基于杨中科老师的书籍<ASP.NET Core技术内幕与项目实战>及配套的B站视频视频教程,同时会增加极少部分的小知识点2.本系列教程主要目的是提炼知识点,追求 ...
- Android 13 新特性及适配指南
Android 13(API 33)于 2022年8月15日 正式发布(发布时间较往年早了一些),正式版Release源代码也于当日被推送到AOSP Android开源项目. 截止到笔者撰写这篇文章时 ...