Hadoop源码学习笔记之NameNode启动场景流程一:源码环境搭建和项目模块及NameNode结构简单介绍
最近在跟着一个大佬学习Hadoop底层源码及架构等知识点,觉得有必要记录下来这个学习过程。想到了这个废弃已久的blog账号,决定重新开始更新。
主要分以下几步来进行源码学习:
一、搭建源码阅读环境
二、源码项目结构概览及hdfs源码包结构简介
三、NameNode介绍
第一步,搭建源码阅读环境。
把Hadoop源码包导入到开发工具,eclipse或者idea都行。这里我的环境是mac os,使用的工具是idea,Hadoop版本为2.6.5。
首先,解压缩Hadoop源码包,可以选择移动解压之后的源码包到idea工作空间
然后打开idea,选择import project,指定工作空间里的源码包路径
选择maven,下一步
勾选红框内选项,下一步。

勾选红框内选项选项,下一步。

继续下一步,

继续下一步,
点击完成,等待maven下载依赖,然后就导入成功了。
需要注意的是导入的时候maven需要下载很多依赖,所以这个过程可能会稍微长一些,耐心等候即可。

项目结构如下,

参考链接:https://blog.csdn.net/twj0823/article/details/84560878
第二步,项目结构概览及hdfs项目包简介。
Hadoop是一个庞大的项目,源码包导入idea之后,可以发现里面又按照功能分为很多不同的小项目,比较耳熟能详的有hdfs、mapreduce、yarn等,
还有别的一些功能性的组件以及新增的特性功能。点开Packages视图,包结构如下:

此处暂时只针对hdfs模块的NameNode进行分析。点开hadoop-hdfs之后,发现也是按照功能进行分包的结构:
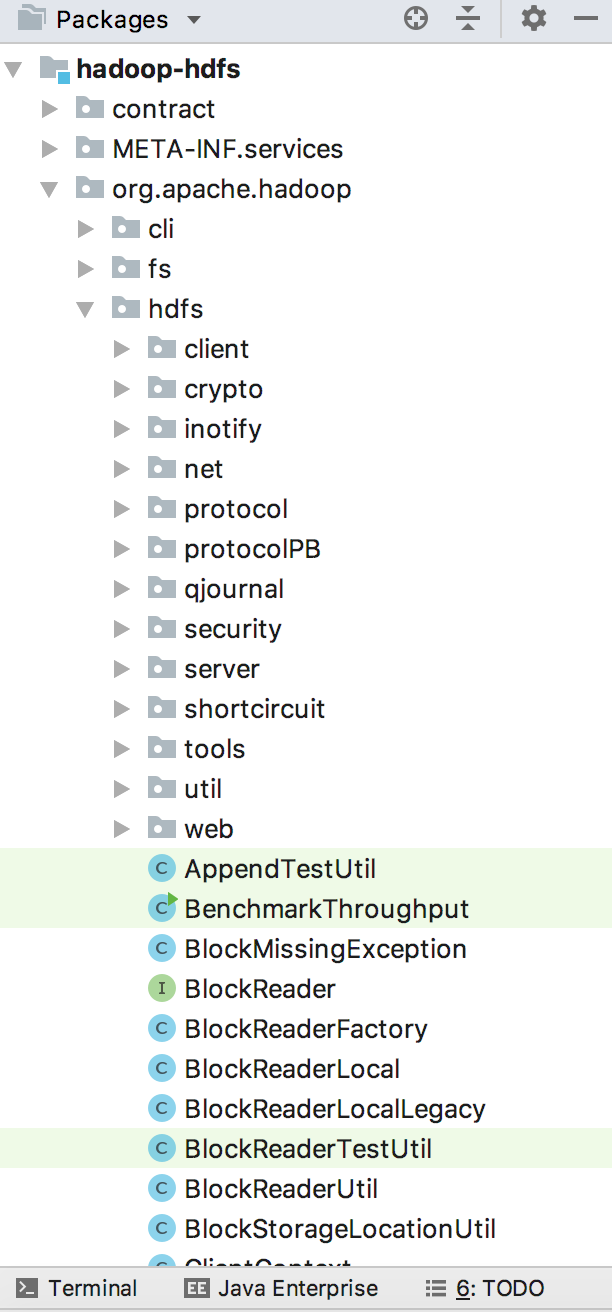
可以自己查看一下各个包里的内容。namenode属于服务器上的一个进程,所以是在server包下。server包除了有namenode,还有datanode、
blockmanagement、common、protocol等包。先把目标锁定在namenode,里面大致有ha高可用、快照处理、启动进程、网络资源等模块

第三步,NameNode类简单介绍。
NameNode类在下边一堆的类文件中间的位置,至此,目标终于找到,开始切入正题了。阅读源码是一个非常好的学习方法,不仅可以学习到底层的
技术实现机制,还可以通过查看核心代码梳理整个调用流程。
首先,要学会看注释,除了通过梳理核心代码流程可以得知整个代码结构之外,通过注释可以更清晰的知道代码的意图。比如看一段繁杂的代码绕来绕去、
晕头转向,而注释就是专门给人看的东西,帮助我们在看代码的时候有一个大致的推测方向。
所以,NameNode的这段注释已经很明白的说明了NameNode的功能和构成:
/**********************************************************
* NameNode serves as both directory namespace manager and
* "inode table" for the Hadoop DFS. There is a single NameNode
* running in any DFS deployment. (Well, except when there
* is a second backup/failover NameNode, or when using federated NameNodes.)
*
* The NameNode controls two critical tables:
* 1) filename->blocksequence (namespace)
* 2) block->machinelist ("inodes")
*
* The first table is stored on disk and is very precious.
* The second table is rebuilt every time the NameNode comes up.
*
* 'NameNode' refers to both this class as well as the 'NameNode server'.
* The 'FSNamesystem' class actually performs most of the filesystem
* management. The majority of the 'NameNode' class itself is concerned
* with exposing the IPC interface and the HTTP server to the outside world,
* plus some configuration management.
**********************************************************/
上面两段话 主要是说,NameNode管理两类数据:
1.filename -> blocksequence (namespace)
文件到block的映射,上传的文件被切分为多个block(128m),这份映射数据就是namespace,存储在磁盘上。
2.block -> machinelist (inodes)
block到datanode的映射,每个block都会分配给一个datanode,每个block还有3个副本,也就是每个block对应多个datanode,
这个映射数据就是inodes。在NameNode每次启动的时候,由datanode汇报过来的。
最下面一段话的字面意思是,NameNode主要由FSNamesystem、NameNode本身、NameNodeServer三部分构成。
其中,FSNamesystem是用来执行文件系统管理的,NameNode被用来处理外部的远程调用,包括HTTP服务以及一些配置管理。
这段话想表达什么意思呢?
FSNamesystem执行文件系统管理,这个好理解,就是负责管理元数据。
NameNode处理外部远程调用以及Http服务怎么理解?其实就是说,NameNode主要干了两件事情:
1.处理一些配置属性,就是core-site.xml、hdfs-site.xml等文件里的配置;
2.启动NameNodeServer(分为NameNodeHttpServer和NameNodeRpcServer),对外监听某个端口,处理接收到的http/rpc请求。比如请求
这两个server进行创建目录、上传/下载文件等一些操作。
以上就是NameNode的功能和组成的大概介绍。
然后,结合Linux上运行jar文件的经验,查看该jar的进程,发现进程名字其实就是jar中被指定执行的Java类文件名。Hadoop集群的主节点NameNode
进程也是如此,由此想进一步知道NameNode的启动流程,可以通过NameNode类的main()入口进去查看。下一篇继续进行源码深入剖析。
Hadoop源码学习笔记之NameNode启动场景流程一:源码环境搭建和项目模块及NameNode结构简单介绍的更多相关文章
- 【OSG学习笔记之一:】OSG+VS2010+win7 64位环境搭建
虽然出生的时候,没有说过“Hello World!”,但是自从走上了编程之路,每一次输出“Hello World!”的时候,都觉得好比中了彩票大奖似的: 仔细算算,从2012年暑假到现在,经历了3年半 ...
- Qt Creator 源码学习笔记04,多插件实现原理分析
阅读本文大概需要 8 分钟 插件听上去很高大上,实际上就是一个个动态库,动态库在不同平台下后缀名不一样,比如在 Windows下以.dll结尾,Linux 下以.so结尾 开发插件其实就是开发一个动态 ...
- Spring源码学习笔记12——总结篇,IOC,Bean的生命周期,三大扩展点
Spring源码学习笔记12--总结篇,IOC,Bean的生命周期,三大扩展点 参考了Spring 官网文档 https://docs.spring.io/spring-framework/docs/ ...
- RocketMQ 源码学习笔记————Producer 是怎么将消息发送至 Broker 的?
目录 RocketMQ 源码学习笔记----Producer 是怎么将消息发送至 Broker 的? 前言 项目结构 rocketmq-client 模块 DefaultMQProducerTest ...
- RocketMQ 源码学习笔记 Producer 是怎么将消息发送至 Broker 的?
目录 RocketMQ 源码学习笔记 Producer 是怎么将消息发送至 Broker 的? 前言 项目结构 rocketmq-client 模块 DefaultMQProducerTest Roc ...
- Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构
Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构 之前我们简要的看过了DataNode的main函数以及整个类的大至,现在结合前面我们研究的线程和RPC,则可以进一步 ...
- Hadoop源码学习笔记(6)——从ls命令一路解剖
Hadoop源码学习笔记(6) ——从ls命令一路解剖 Hadoop几个模块的程序我们大致有了点了解,现在我们得细看一下这个程序是如何处理命令的. 我们就从原头开始,然后一步步追查. 我们先选中ls命 ...
- Hadoop源码学习笔记(2) ——进入main函数打印包信息
Hadoop源码学习笔记(2) ——进入main函数打印包信息 找到了main函数,也建立了快速启动的方法,然后我们就进去看一看. 进入NameNode和DataNode的主函数后,发现形式差不多: ...
- Hadoop源码学习笔记(1) ——第二季开始——找到Main函数及读一读Configure类
Hadoop源码学习笔记(1) ——找到Main函数及读一读Configure类 前面在第一季中,我们简单地研究了下Hadoop是什么,怎么用.在这开源的大牛作品的诱惑下,接下来我们要研究一下它是如何 ...
随机推荐
- java基础(十) 数组类型
1. 数组类简介 在java中,数组也是一种引用类型,即是一种类. 我们来看一个例子,理解一下数组类: public static void main(String[] args) { Class ...
- 通过html导出PDF如何分页
每页一个DIV,加上样式page-break-inside:avoid; 即可分页了 .pdfpage{page-break-inside:avoid;} <div class="pd ...
- Linux学习之CentOS(一)----在VMware虚拟机中安装CentOS 7
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/3 ...
- spring boot(14)-pom.xml配置
继承spring-boot-starter-parent 要成为一个spring boot项目,首先就必须在pom.xml中继承spring-boot-starter-parent,同时指定其版本 & ...
- Python 中单双引号
TODO, 在python中, 其实单双引号还是有分别的, 具体是什么?
- 第六章 函数、谓词、CASE表达式 6-3 CASE表达式
一.什么是CASE表达式 CASE表达式是一种运算功能,意味着CASE表达式也是函数的一种. 它是SQL中数一数二的重要功能.必须好好学习掌握. CASE表达式是在区分情况时使用的,这种情况的区分 ...
- 查看windows所有exe的启动参数。
在cmd中输入 wmicprocess 即可查看到所有进程的启动参数和运行参数.
- [翻译] iOSSharedViewTransition
iOSSharedViewTransition iOS 7 based transition library for View Controllers having a Common View 基于i ...
- django中的字段类型
from http://www.cnblogs.com/lhj588/archive/2012/05/24/2516040.html Django 通过 models 实现数据库的创建.修改.删除等操 ...
- Composer 的简介、安装及使用
Composer的简介 简单说,Composer 就是一个安装包管理工具,服务于 PHP 生态系统.它包括了两个部分:Composer 和 Packagist. Composer Composer 是 ...