mysql千万级表关联优化(2)
概述:
交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别差,因此SQL优化任务交到了我手上。
这个SQL查询关联两个数据表,一个是攻击IP用户表主要是记录IP的信息,如第一次攻击时间,地址,IP等等,一个是IP攻击次数表主要是记录每天IP攻击次数。而需求是获取某天攻击IP信息和次数。(以下SQL语句测试均在测试服务器上上,正式服务器的性能好,查询时间快不少。)
准备:
查看表的行数: 

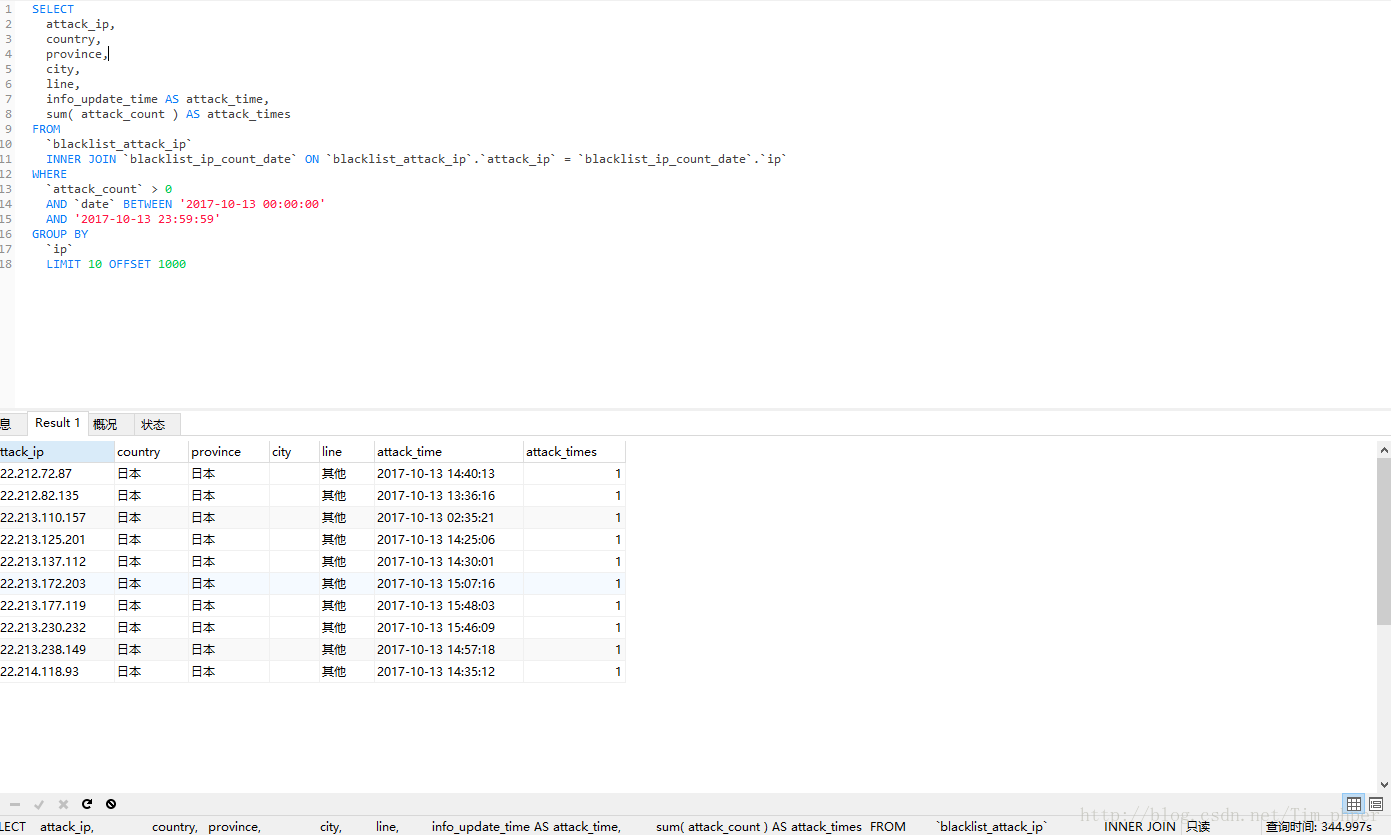
未优化前SQL语句为:
SELECT
attack_ip,
country,
province,
city,
line,
info_update_time AS attack_time,
sum( attack_count ) AS attack_times
FROM
`blacklist_attack_ip`
INNER JOIN `blacklist_ip_count_date` ON `blacklist_attack_ip`.`attack_ip` = `blacklist_ip_count_date`.`ip`
WHERE
`attack_count` > 0
AND `date` BETWEEN '2017-10-13 00:00:00'
AND '2017-10-13 23:59:59'
GROUP BY
`ip`
LIMIT 10 OFFSET 1000- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
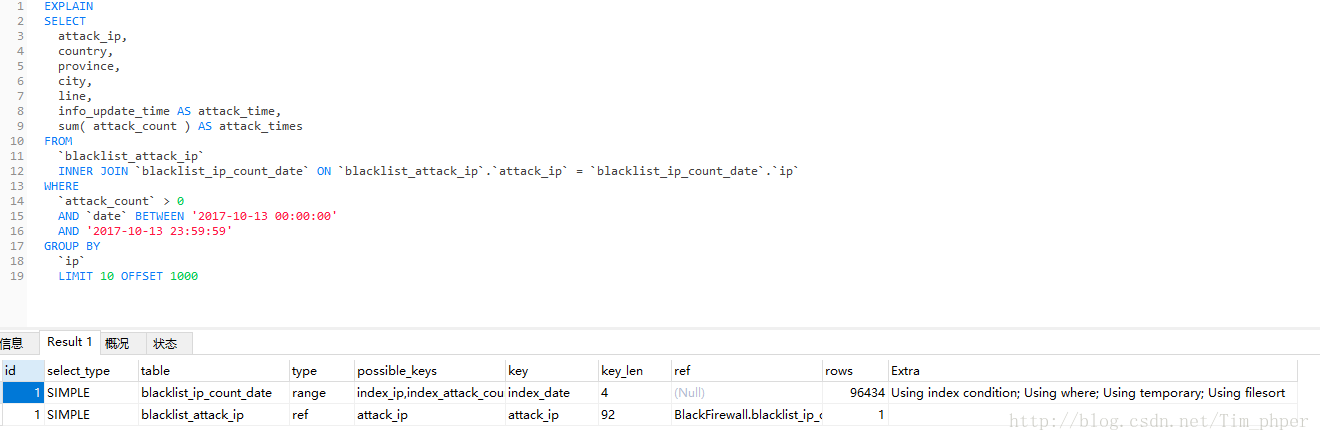
先EXPLAIN分析一下:
这里看到索引是有的,但是IP攻击次数表blacklist_ip_count_data也用上了临时表。那么这SQL不优化直接第一次执行需要多久(这里强调第一次是因为MYSQL带有缓存功能,执行过一次的同样SQL,第二次会快很多。)
实际查询时间为300+秒,这完全不能接受呀,这还是没有其他搜索条件下的。
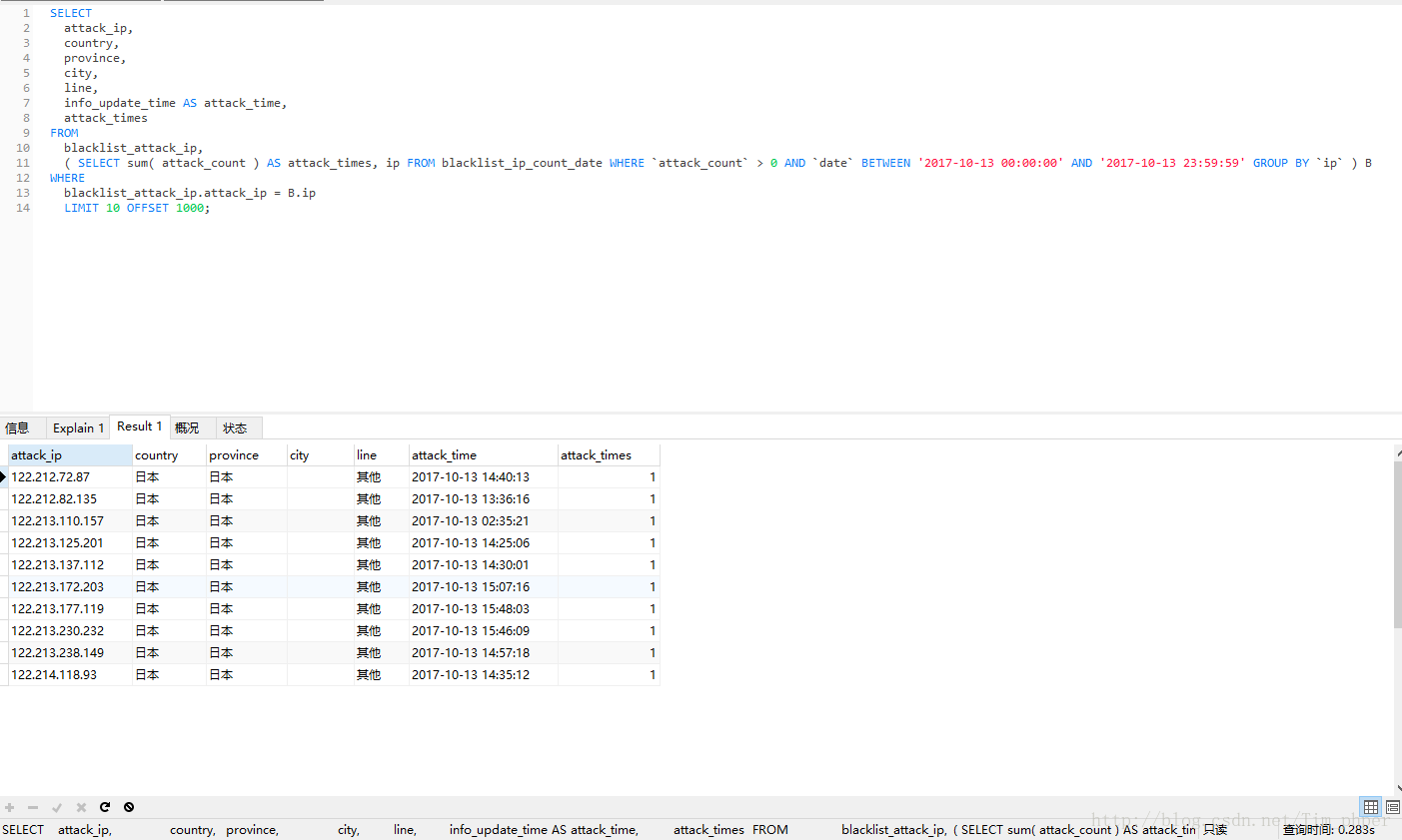
那么我们怎么优化呢,这里用的是内联表查询,大家都是知道子查询完全是可以代替内联表查询的,只不过SQL语句复杂了不少,那么我们分析一下这SQL,两个表分表提供了什么?
1、IP攻击次数表blacklist_ip_count_data主要提供的指定时间条件查询,攻击次数条件查询后的IP和每个IP符合条件下的具体攻击次数。
2、攻击IP用户表blacklist_attack_ip主要是具体IP的信息,如第一次攻击时间,地址,IP等等。
那么我们一步步来:
1、IP攻击次数表blacklist_ip_count_data获取符合时间条件和攻击次数的IP并且以IP分组: 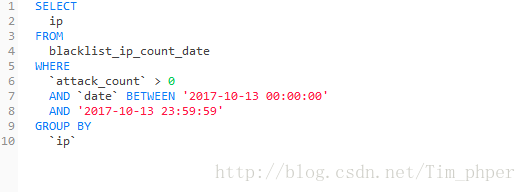
2、攻击IP用户表blacklist_attack_ip指定具体的IP获取信息: 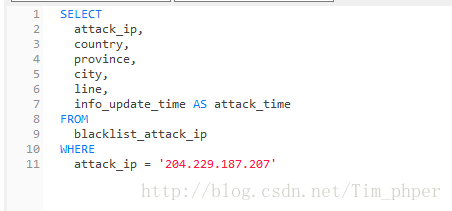
然后结合在一起:
可见,取出来的数据完全一模一样,可是优化后效率从原来的330秒变成了0.28秒,这里足足提升了1000多倍的速度。这也基本满足了我们的优化需求。
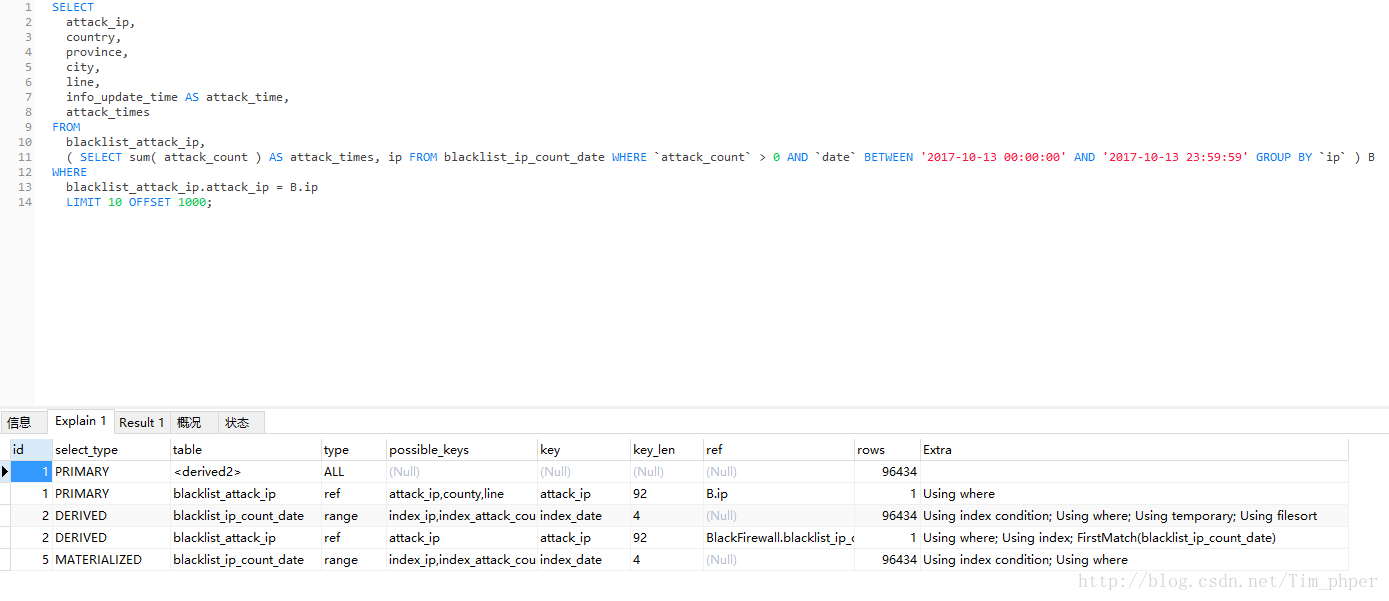
我们EXPLAIN了解一下情况:
mysql千万级表关联优化(2)的更多相关文章
- mysql千万级表关联优化
MYSQL一次千万级连表查询优化(一) 概述: 交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别差 ...
- 如何优化MySQL千万级大表
很好的一篇博客,转载 如何优化MySQL千万级大表 原文链接::https://blog.csdn.net/yangjianrong1985/article/details/102675334 千万级 ...
- Mysql千万级大表优化
Mysql的单张表的最大数据存储量尚没有定论,一般情况下mysql单表记录超过千万以后性能会变得很差.因此,总结一些相关的Mysql千万级大表的优化策略. 1.优化sql以及索引 1.1优化sql 1 ...
- MySQL千万级大表优化解决方案
MySQL千万级大表优化解决方案 非原创,纯属记录一下. 背景 无意间看到了这篇文章,作者写的很棒,于是乎,本人自私一把,把干货保存下来.:-) 问题概述 使用阿里云rds for MySQL数据库( ...
- MySQL 百万级分页优化(Mysql千万级快速分页)(转)
http://www.jb51.net/article/31868.htm 以下分享一点我的经验 一般刚开始学SQL的时候,会这样写 复制代码 代码如下: SELECT * FROM table OR ...
- MySQL 百万级分页优化(Mysql千万级快速分页)
以下分享一点我的经验 一般刚开始学SQL的时候,会这样写 : SELECT * FROM table ORDER BY id LIMIT 1000, 10; 但在数据达到百万级的时候,这样写会慢死 : ...
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案
如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案
- mysql千万级数据库插入速度和读取速度的调整记录
一般情况下mysql上百万数据读取和插入更新是没什么问题了,但到了上千万级就会出现很慢,下面我们来看mysql千万级数据库插入速度和读取速度的调整记录吧. 1)提高数据库插入性能中心思想:尽量将数据一 ...
- 如何对MySQL 对于大表(千万级)进行优化
如何对Mysql中的大型表进行优化 @(mysql 笔记) 收集信息 1.数据的容量:1-3年内会大概多少条数据,每条数据大概多少字节: 2.数据项:是否有大字段,那些字段的值是否经常被更新: 3.数 ...
随机推荐
- select标签和多行文本标签
一.多行文本textarea <form> <div> <textarea name="more"></textarea> < ...
- Rstudio常用快捷键
多行注释 ctrl+shift+c 运行单行或选中代码 ctrl+enter 查看帮助 F1
- pyqt5的代码
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- P3924 康娜的线段树
P3924 康娜的线段树 题目描述 小林是个程序媛,不可避免地康娜对这种人类的"魔法"产生了浓厚的兴趣,于是小林开始教她OI. 今天康娜学习了一种叫做线段树的神奇魔法,这种魔法可以 ...
- Java5的新特性
原文出处:xixicat 序 这是Java语言特性系列的第一篇,从java5的新特性开始讲起.初衷就是可以方便的查看语言的演进历史. 特性列表 泛型 枚举 装箱拆箱 变长参数 注解 foreach循环 ...
- docker的优势
基于微服务的架构已经成为一种流行趋势.而Docker则给微服务的蓬勃发展注入了更强的活力. docker的吸引能力主要来自两方面:快速和可移植. 1.快速 普通的虚拟机每次都需要启动一个完整的操作系统 ...
- Typora 自定义主题 修改左右间距
打开偏好设置,打开主题文件夹 比如要修改night主题中的间距,编辑night.css文件,修改#write样式即可. 修改其他样式类试.
- Challenge 18
Challenge 18给你一个长度为 n 的非负整数序列 a 和 m 个询问 l, r, p, k,表示询问在 a[l .. r] 中 a[i]%p=k 的 i 的个数. 思路: 将序列分为根号n块 ...
- pandas 视频讲座 from youtube
Stephen Simmons - Pandas from the inside - YouTube https://www.youtube.com/watch?v=Dr3Hv7aUkmU 2016年 ...
- Kafka安装验证及其注意
一.Zookeeper 配置文件说明: # the directory where the snapshot is stored. dataDir=/tmp/zookeeper # the port ...