【大数据】MapTask并行度和切片机制
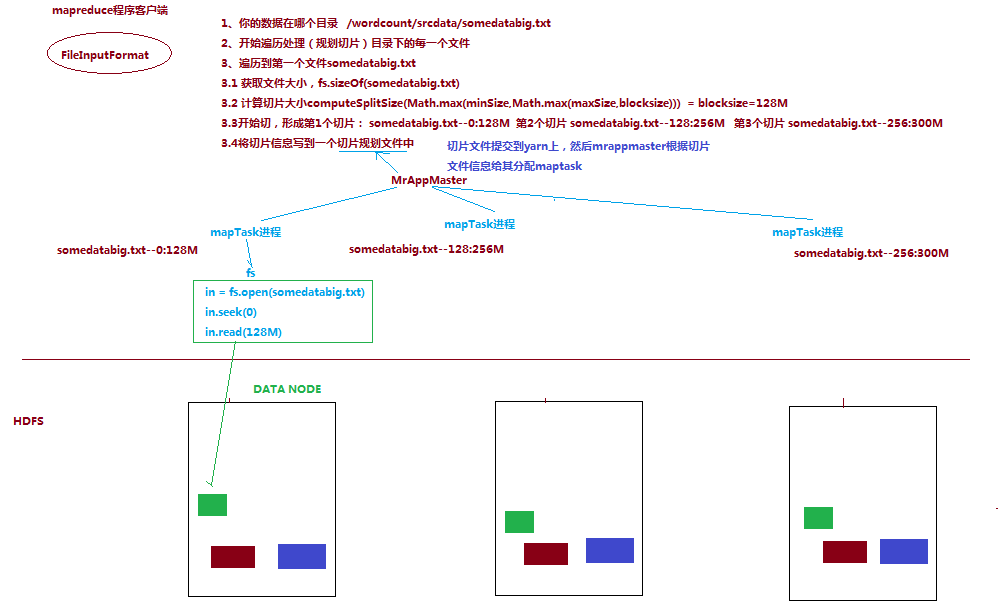 二:InputFormat数据切片机制
二:InputFormat数据切片机制2.切片大小,默认等于block大小(这样如果有很多小文件时,就会产生很多切片,造成很多个maptask,降低系统性能)
3.切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
|
file1.txt 320M
file2.txt 10M
|
|
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10M
|
(2)切片大小,默认等于block大小
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
|
file1.txt 320M
file2.txt 10M
|
|
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10M
|
|
//根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
//获取切片的文件名称
String name = inputSplit.getPath().getName();//获取的是被切片文件名:
|
【大数据】MapTask并行度和切片机制的更多相关文章
- 大数据学习笔记——Spark工作机制以及API详解
Spark工作机制以及API详解 本篇文章将会承接上篇关于如何部署Spark分布式集群的博客,会先对RDD编程中常见的API进行一个整理,接着再结合源代码以及注释详细地解读spark的作业提交流程,调 ...
- 大数据框架hadoop的序列化机制
Java内建序列化机制 在Windows系统上序列化的Java对象,可以在UNIX系统上被重建出来,不需要担心不同机器上的数据表示方法,也不需要担心字节排列次序. 在Java中,使一个类的实例可被序列 ...
- mapTask并行度优化及源码分析
mapTask并行度的决定机制 一个job的map阶段并行度由客户端在提交job时决定,而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分 ...
- 大数据入门第七天——MapReduce详解(二)切片源码浅析与自定义patition
一.mapTask并行度的决定机制 1.概述 一个job的map阶段并行度由客户端在提交job时决定 而客户端对map阶段并行度的规划的基本逻辑为: 将待处理数据执行逻辑切片(即按照一个特定切片大小, ...
- Hadoop_16_MapRduce_MapTask并行度(切片)的决定机制
MapTask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度那么,mapTask并行实例是否越多 越好呢?其并行度又是如何决定呢?Mapper数量由输入文件的数目.大小及配置参 ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink--容错机制(ACK,RDD,基于log和状态快照),消息处理at least once,exactly once两个是关键
分布式流处理是对无边界数据集进行连续不断的处理.聚合和分析.它跟MapReduce一样是一种通用计算,但我们期望延迟在毫秒或者秒级别.这类系统一般采用有向无环图(DAG). DAG是任务链的图形化表示 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
随机推荐
- @RestController注解
@RestController注解其实就是@@Controller和@ResponseBody的组合:RESTFUL风格 看下源码: 当@ResponseBody放到Controller类上,改Con ...
- win10系统安装docker注意事项
首先要确保win10系统支持 hyper-v 技术. 然后按照官网的流程下载,安装,基本上不会出什么问题.安装好之后使用,需要进行以下几个操作 access denied问题的解决 按win+R,输入 ...
- 《python 经典实例》 分享 pdf下载
链接:https://pan.baidu.com/s/1FzSsBfynqx5ll_OpcZGDHg提取码:ykgk
- 【LeetCode算法题库】Day3:Reverse Integer & String to Integer (atoi) & Palindrome Number
[Q7] 把数倒过来 Given a 32-bit signed integer, reverse digits of an integer. Example 1: Input: 123 Outpu ...
- PLSQL触发器,游标
--触发器 drop table emp_log create table emp_log( empno number, log_date date, new_salary number, actio ...
- 正则表达式的捕获组(Java)
捕获组分类 普通捕获组(Expression) 命名捕获组(?<name>Expression) 普通捕获组 从正则表达式左侧开始,每出现一个左括号“(”记做一个分组,分组编号从1开始.0 ...
- 学习python,第三篇:.pyc是个什么鬼?
.pyc是个什么鬼? 1. Python是一门解释型语言? 我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存 ...
- 【NLP】使用bert
# 参考 https://blog.csdn.net/luoyexuge/article/details/84939755 小做改动 需要: github上下载bert的代码:https://gith ...
- 5337朱荟潼Java实验报告一
一.实验内容 1.内容一输出“Hello 名”. import java.util.Scanner;public class Hello{public static void main(String[ ...
- Java 面试 --- 3
上一篇,我们给出了大概35个题目,都是基础知识,有童鞋反映题目过时了,其实不然,这些是基础中的基础,但是也是必不可少的,面试题目中还是有一些基础题目的,我们本着先易后难的原则,逐渐给出不同级别的题目, ...