通过案例对SparkStreaming透彻理解三板斧之二
本节课主要从以下二个方面来解密SparkStreaming:
一、解密SparkStreaming运行机制
二、解密SparkStreaming架构
SparkStreaming运行时更像SparkCore上的应用程序,SparkStreaming程序启动后会启动很多job,每个batchIntval、windowByKey的job、框架运行启动的job。例如,Receiver启动时也启动了job,此job为其他job服务,所以需要做复杂的spark程序,往往多个job之间互相配合。SparkStreaming是最复杂的应用程序,如果对SparkStreaming了如指掌的话,做其他的Spark应用程序没有任何问题。看下官网:Spark sql,SparkStreaming,Spark ml,Spark graphx子框架都是后面开发出来的,我们要洞悉Spark Core 的话,SparkStreaming是最好的切入方式。
进入Spark官网,可以看到SparkCore和其他子框架的关系:
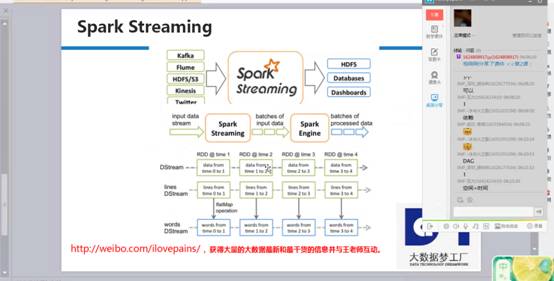
SparkStreaming启动后,数据不断通过inputStream流进来,根据时间划分成不同的job、就是batchs of input data,每个job有一序列rdd的依赖。Rdd的依赖有输入的数据,所以这里就是不同的rdd依赖构成的batch,这些batch是不同的job,根据spark引擎来得出一个个结果。DStream是逻辑级别的,而RDD是物理级别的。DStream是随着时间的流动内部将集合封装RDD。对DStream的操作,转过来是对其内部的RDD操作。
我是使用SparkCore 编程都是基于rdd编程,rdd间有依赖关系,如下图右侧的依赖关系图,SparkStreaming运行时,根据时间为维度不断的运行。Rdd的dag依赖是空间维度,而DStream在rdd的基础上加上了时间维度,所以构成了SparkStreaming的时空维度。
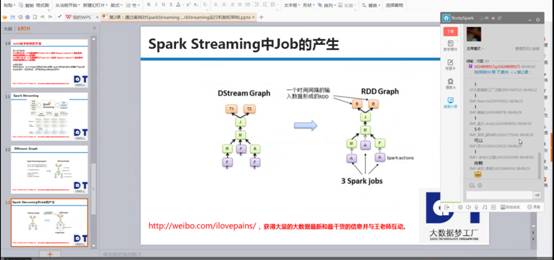
SparkStreaming在rdd的基础上增加了时间维度,运行时可以清晰看到jobscheduler、mappartitionrdd、shuffledrdd、blockmaanager等等,这些都是SparkCore的内容,而DStream、jobgenerator、socketInputDstream等等都是SparkStreaming的内容,如下图运行过程可以很清晰的看到:

现在通过SparkStreaming的时空维度来细致说明SparkStreaming运行机制

时间维度:按照固定时间间隔不断地产生job对象,并在集群上运行:
包含有batch interval,窗口长度,窗口滑动时间等
空间维度:代表的是RDD的依赖关系构成的具体的处理逻辑的步骤,是用DStream来表示的:
1、需要RDD,DAG的生成模板
2、TimeLine的job控制器、
3、InputStream和outputstream代表的数据输入输出
4、具体Job运行在Spark Cluster之上,此时系统容错就至关重要
5、事务处理,在处理出现奔溃的情况下保证Exactly once的事务语义一致性
随着时间的流动,基于DStream Graph不断生成RDD Graph,也就是DAG的方式生成job,并通过Job Scheduler的线程池的方式提交给Spark Cluster不断的执行,
由上图可知,RDD 与 DStream之间的关系如下:
1、RDD是物理级别的,而 DStream 是逻辑级别的;
2、DStream是RDD的封装模板类,是RDD进一步的抽象;
3、DStream要依赖RDD进行具体的数据计算;
Spark Streaming源码解析
1、StreamingContext方法中调用JobScheduler的start方法:
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("Master", 9999)
......//业务处理代码略
ssc.start()
ssc.awaitTermination()
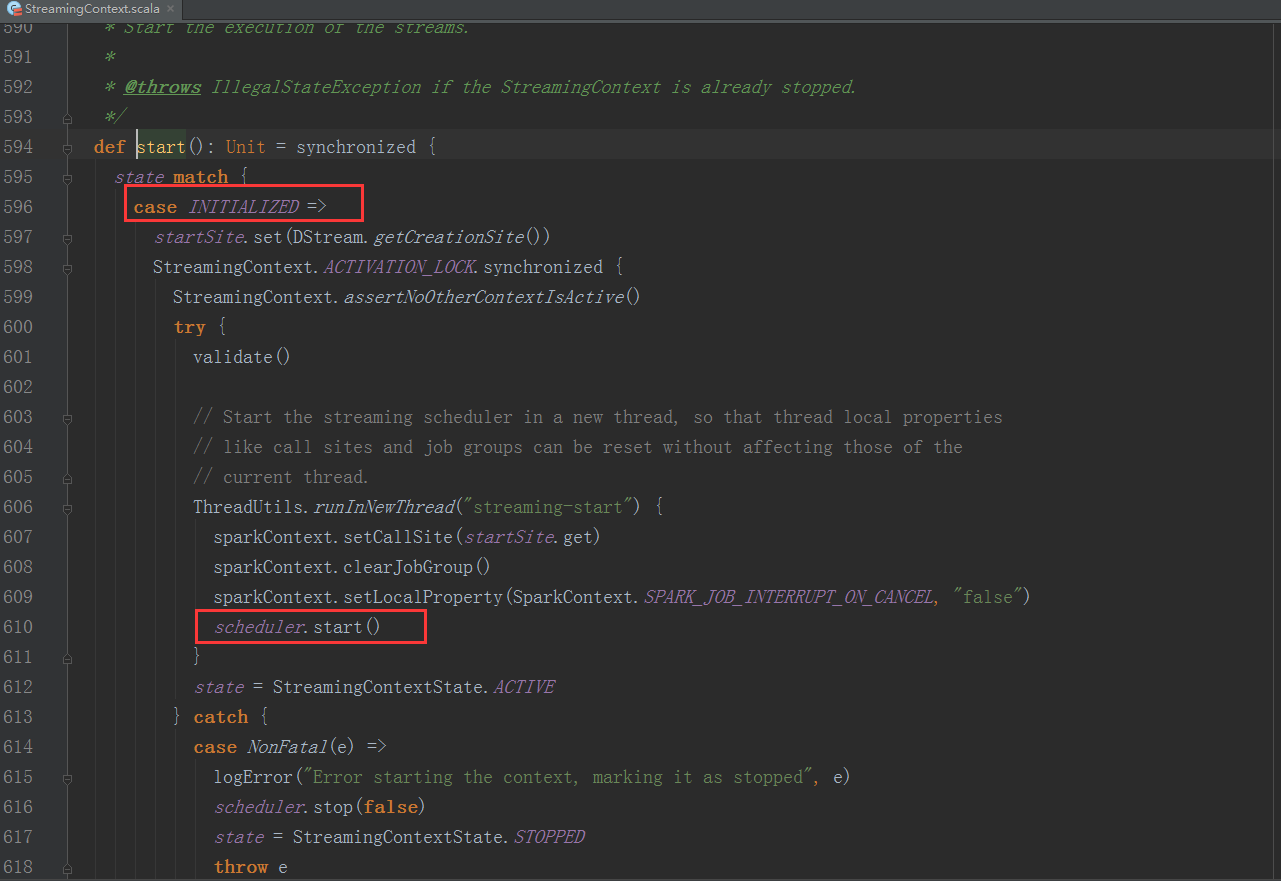
我们进入JobScheduler start方法的内部继续分析:
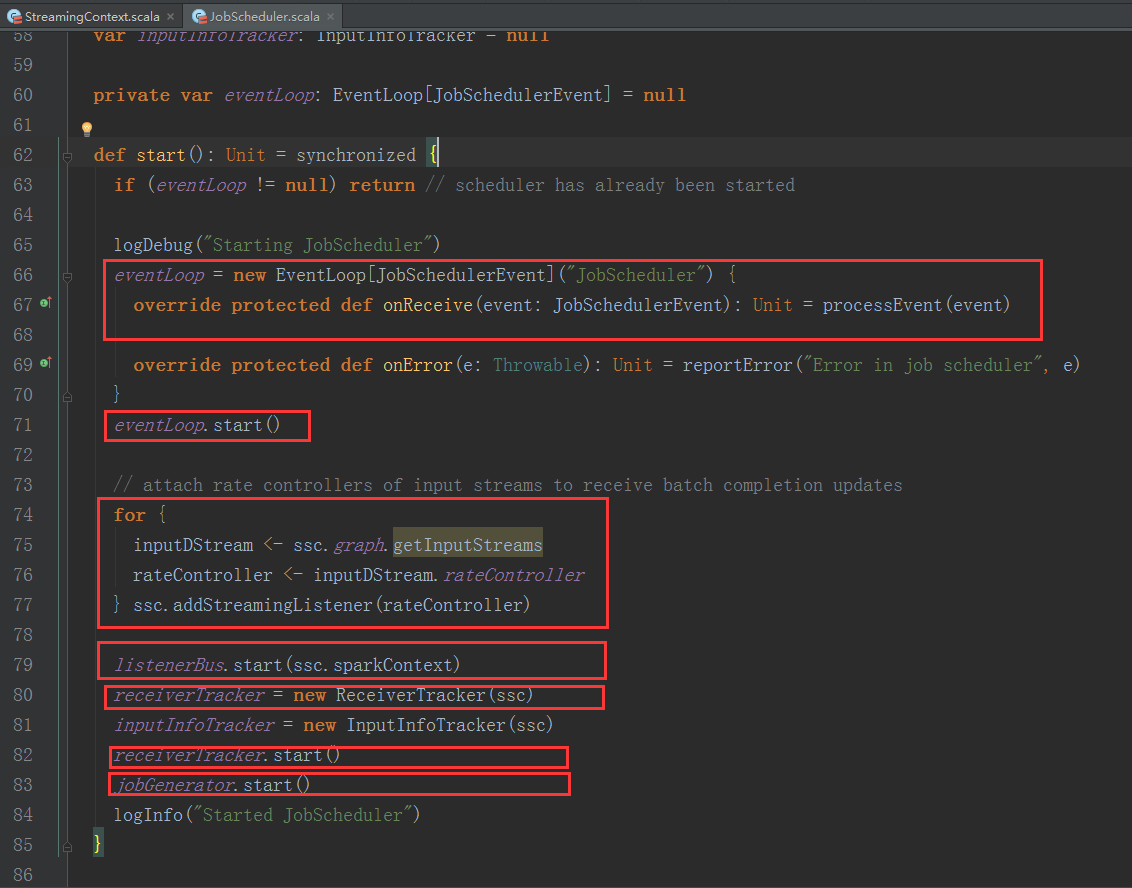
1、JobScheduler 通过onReceive方法接收各种消息并存入enventLoop消息循环体中。
2、通过rateController对流入SparkStreaming的数据进行限流控制。
3、在JobScheduler的start内部会构造JobGenerator和ReceiverTacker,并且调用JobGenerator和ReceiverTacker的start方法。
ReceiverTacker的启动方法:

1、ReceiverTracker启动后会创建ReceiverTrackerEndpoint这个消息循环体,来接收运行在Executor上的Receiver发送过来的消息。
2、ReceiverTracker启动后会在Spark Cluster中启动executor中的Receivers。
JobGenerator的启动方法:

1、JobGenerator启动后会启动以batchInterval时间间隔发送GenerateJobs消息的定时器


Spark发行版笔记2
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
邮箱:18610086859@vip.126.com
通过案例对SparkStreaming透彻理解三板斧之二的更多相关文章
- 通过案例对SparkStreaming透彻理解三板斧之一
本节课通过二个部分阐述SparkStreaming的理解: 一.解密SparkStreaming另类在线实验 二.瞬间理解SparkStreaming本质 Spark源码定制班主要是自己做发行版.自己 ...
- 通过案例对SparkStreaming透彻理解三板斧之三
本课将从二方面阐述: 一.解密SparkStreaming Job架构和运行机制 二.解密SparkStreaming容错架构和运行机制 一切不能进行实时流处理的数据都将是无效的数据.在流处理时代,S ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 回调函数透彻理解Java
http://blog.csdn.net/allen_zhao_2012/article/details/8056665 回调函数透彻理解Java 标签: classjavastringinterfa ...
- 透彻理解Spring事务设计思想之手写实现
前言 事务,是描述一组操作的抽象,比如对数据库的一组操作,要么全部成功,要么全部失败.事务具有4个特性:Atomicity(原子性),Consistency(一致性),Isolation(隔离性),D ...
- 透彻理解Spring事务设计思想之手写实现(山东数漫江湖)
前言 事务,是描述一组操作的抽象,比如对数据库的一组操作,要么全部成功,要么全部失败.事务具有4个特性:Atomicity(原子性),Consistency(一致性),Isolation(隔离性),D ...
- 如何理解CPU上下文切换(二)
如何理解CPU上下文切换(二) 1.引 你们好,可爱的小伙伴们.^_^ 多个进程竞争CPU就是一个经常被我们忽视的问题. 你们一定很好奇,进程在竞争CPU的时候并没有真正运行,为什么还会导致系统的负载 ...
随机推荐
- Linux-进程间通信(二): FIFO
1. FIFO: FIFO也被成为命名管道,因其通过路径关系绑定,可以用于任意进程间通信,而普通无名管道只能用于有共同祖先的进行直接通信; 命名管道也是半双工的,open管道的时候不要以读写方式打开, ...
- appium===Python+Appium环境部署教程
*前提是你已经安装好python,以及python的pip工具 *安装python请自行百度教程~ 1.安装安卓sdk 安装包:http://tools.android-studio.org/inde ...
- layer close 关闭层IE9-浏览器崩溃问题解决
针对ayer弹出层在IE上关闭导致浏览器崩溃的问题: 导致原因: 查看src源码,layer.close关闭总方法中有这么一行: layer.close = function(index){ ] + ...
- selenium+python自动化79-文件下载(SendKeys)【转载】
前言 文件下载时候会弹出一个下载选项框,这个弹框是定位不到的,有些元素注定定位不到也没关系,就当没有鼠标,我们可以通过键盘的快捷键完成操作. SendKeys库是专业的处理键盘事件的,所以这里需要用S ...
- 关于ofbiz加载数据模块的文件参数配置
1,在applications文件夹下新建一个数据模块meetingroom 2, 要让ofbiz加载这个数据模块就需要在applications下的配置文件里修改参数 (1)在application ...
- 转载] magento 产品数据表结构
原文地址:http://blog.sina.com.cn/s/blog_9302097a010120l4.html 数据库-- 产品数据库表结构分析 product 1数据库实体表:catalog_p ...
- HDU 1014 Uniform Generator(最大公约数,周期循环)
#include<iostream> #include <cstdio> #include <cstring> using namespace std; int m ...
- Codeforces Round 252 (Div. 2)
layout: post title: Codeforces Round 252 (Div. 2) author: "luowentaoaa" catalog: true tags ...
- Typora
Typora BB in front 如果你是一个佛(lan)系(duo),内心文艺的程序员,并且你对其他Markdown编辑器的使用效果感觉不是很好的话,可以来了解一下该软件Typora. What ...
- py thon 多线程(转一篇好文章)
http://www.cnblogs.com/fnng/p/3670789.html