OpenPAI:大规模人工智能集群管理平台介绍及任务提交指南
产品渊源:
随着人工智能技术的快速发展,各种深度学习框架层出不穷,为了提高效率,更好地让人工智能快速落地,很多企业都很关注深度学习训练的平台化问题。例如,如何提升GPU等硬件资源的利用率?如何节省硬件投入成本?如何支持算法工程师更方便的应用各类深度学习技术,从繁杂的环境运维等工作中解脱出来?等等。
产品定位:
为深度学习提供一个深度定制和优化的人工智能集群管理平台,让人工智能堆栈变得简单、快速、可扩展。
产品优势:
● 为深度学习量身定做,可扩展支撑更多AI和大数据框架
通过创新的PAI运行环境支持,几乎所有深度学习框架如CNTK、TensorFlow、PyTorch等无需修改即可运行;其基于Docker的架构则让用户可以方便地扩展更多AI与大数据框架。
● 容器与微服务化,让AI流水线实现DevOps
OpenPAI 100%基于微服务架构,让AI平台以及开发便于实现DevOps的开发运维模式。
● 支持GPU多租,可统筹集群资源调度与服务管理能力
在深度学习负载下,GPU逐渐成为资源调度的一等公民,OpenPAI提供了针对GPU优化的调度算法,丰富的端口管理,支持Virtual Cluster多租机制,可通过Launcher Server为服务作业的运行保驾护航。
● 提供丰富的运营、监控、调试功能,降低运维复杂度
PAI为运营人员提供了硬件、服务、作业的多级监控,同时开发者还可以通过日志、SSH等方便调试作业。
OpenPAI的架构如下图所示,用户通过Web Portal调用REST Server的API提交作业(Job)和监控集群,其它第三方工具也可通过该API进行任务管理。随后Web Portal与Launcher交互,以执行各种作业,再由Launcher Server处理作业请求并将其提交至Hadoop YARN进行资源分配与调度。可以看到,OpenPAI给YARN添加了GPU支持,使其能将GPU作为可计算资源调度,助力深度学习。其中,YARN负责作业的管理,其它静态资源(下图蓝色方框所示)则由Kubernetes进行管理。
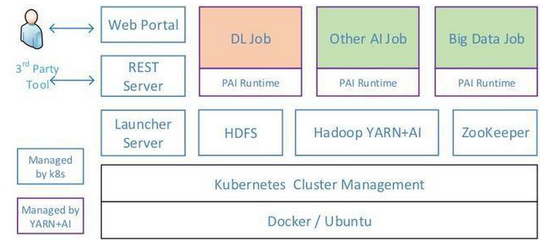
提交作业:Web Portal
交互中间件:Launcher
作业、资源管理:Hadoop YARN
静态资源管理:Kubernetes
任务提交指南
提交任务的方式主要有三种,但对于centos系统只有web端的提交形式
在web端通过json配置文件的形式进行job提交

配置文件编辑完成后,进行配置文件上传
配置文件上传后,相关配置在web端显示
任务提交
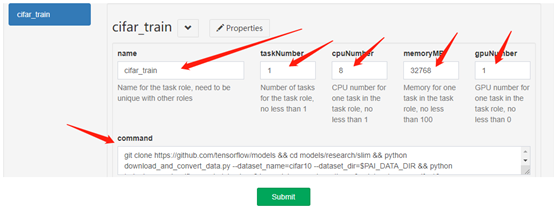
确认信息无误后,点击Submit,完成任务提交

Hadoop yarn进行任务调度
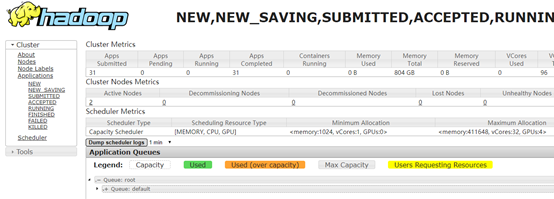
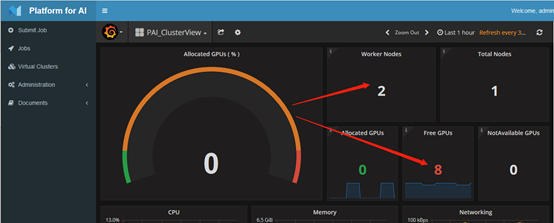
集群现状:
OpenPAI:大规模人工智能集群管理平台介绍及任务提交指南的更多相关文章
- 基于 Clusternet 与 OCM 打造新一代开放的多集群管理平台
背景 随着 5G.物联网设备的爆炸性增长以及智能终端不断增强的计算能力,带来了前所未有的数据量,传统的中心集中式计算捉襟见肘."新基建"战略的实施,工业互联网.车联网/自动驾驶.智 ...
- 基于zookeeper+mesos+marathon的docker集群管理平台
参考文档: mesos:http://mesos.apache.org/ mesosphere社区版:https://github.com/mesosphere/open-docs mesospher ...
- 容器、容器集群管理平台与 Kubernetes 技术漫谈
原文:https://www.kubernetes.org.cn/4786.html 我们为什么使用容器? 我们为什么使用虚拟机(云主机)? 为什么使用物理机? 这一系列的问题并没有一个统一的标准答案 ...
- 强大多云混合多K8S集群管理平台Rancher入门实战
@ 目录 概述 定义 为何使用 其他产品 安装 简述 规划 基础环境 Docker安装 Rancher安装 创建用户 创建集群 添加Node节点 配置kubectl 创建项目和名称空间 发布应用 偏好 ...
- Spark集群管理器介绍
Spark可以运行在各种集群管理器上,并通过集群管理器访问集群中的其他机器.Spark主要有三种集群管理器,如果只是想让spark运行起来,可以采用spark自带的独立集群管理器,采用独立部署的模式: ...
- 基于Python+Django的Kubernetes集群管理平台
➠更多技术干货请戳:听云博客 时至今日,接触kubernetes也有一段时间了,而我们的大部分业务也已经稳定地运行在不同规模的kubernetes集群上,不得不说,无论是从应用部署.迭代,还是从资源调 ...
- 大规模Elasticsearch集群管理心得
转载:http://elasticsearch.cn/article/110 ElasticSearch目前在互联网公司主要用于两种应用场景,其一是用于构建业务的搜索功能模块且多是垂直领域的搜索,数据 ...
- 大快搜索DKhadoop集群管理平台添加节点的步骤说明
Hadoop作为搭建大数据处理平台的重要“基石”,关于它的分析和讲解的文章已经有很多了.Hadoop本身是一分布式的系统,因此在安装的时候,需要多每一个节点进行组建的安装.并且由于是开源软件,其安装过 ...
- 深度学习GPU集群管理软件 OpenPAI 简介
OpenPAI:大规模人工智能集群管理平台 2018年5月22日,在微软举办的“新一代人工智能开放科研教育平台暨中国高校人工智能科研教育高峰论坛”上,微软亚洲研究院宣布,携手北京大学.中国科学技术大学 ...
随机推荐
- 理解Storm可靠性消息
看过一些别人写的, 感觉有些东西没太说清楚,个人主要以源代码跟踪,参考个人理解讲述,有错误请指正. 1基本名词 1.1 Tuple: 消息传递的基本单位.很多文章中介绍都是这么说的, 个人觉得应该更详 ...
- Restrramework源码(包含组件)分析
1.总体流程分析 rest_framework/view.py 请求通过url分发,触发as_view方法,该方法在ViewSetMixin类下 点进去查看as_view源码说明,可以看到它在正常情况 ...
- SpringBoot非官方教程 | 第二十一篇: springboot集成JMS
转载请标明出处: http://blog.csdn.net/forezp/article/details/71024024 本文出自方志朋的博客 springboot对JMS提供了很好的支持,对其做了 ...
- repo配置与连接
repo是远程访问android源码的工具,和git一起使用. repo的远程安装经常被屏蔽,你懂得. sudo apt-get install curl 244 sudo apt-get - ...
- TortoiseSVN SendRpt.exe not found解决方案
重启了Explorer.exe即可.这里也补充下简单的重启Explorer.exe的方法:打开任务管理器,找到“Windows资源管理器”,右键--重新启动. 或者,右键--结束任务,然后点击 文件- ...
- 通过xshell在linux上安装redis3.0.0
通过xshell在linux上安装redis3.0.0 0)首先要安装环境:yum install gcc-c++ 1)通过xftp6将redis安装包上传到linux:解压缩:tar -xvfz r ...
- 编译安装开源免费中文分词scws
一.SCWS了解一下: SCWS 是 Simple Chinese Word Segmentation 的首字母缩写(即:简易中文分词系统). 这是一套基于词频词典的机械式中文分词引擎,它能将一整段的 ...
- Angular-chart.js 使用说明(基于angular.js工程)
Angular-chart.js是基于Chart.js的angular组件,引入项目后直接操作数据即可. 引用方法: 分别将Chart.js.angular-chart.js.angular-c ...
- 11个简单实用技巧--Java性能调优
多数开发人员认为性能优化是个比较复杂的问题,需要大量的经验和知识.是的,这并不没有错.诚然,优化应用程序以获得最好的性能并不是一件容易的事情,但这并不意味着你在没有获得这些经验和知识之前就不能做任何事 ...
- Spring-Boot ☞ ShapeFile文件读写工具类+接口调用
一.项目目录结构树 二.项目启动 三.往指定的shp文件里写内容 (1) json数据[Post] { "name":"test", "path&qu ...