DQN(Deep Reiforcement Learning) 发展历程(一)
目录
马尔可夫理论
马尔可夫性质
- P[St+1 | St] = P[St+1 | S1,...,St]
- 给定当前状态 St ,过去的状态可以不用考虑
- 当前状态 St 可以代表过去的所有状态
- 给定当前状态的条件下,未来的状态和过去的状态相互独立。
马尔可夫过程(MP)
- 形式化地描述了强化学习的环境。
- 包括二元组(S,P)
- 根据给定的转移概率矩阵P,从当前状态St转移到下一状态St+1,
- 基于模型的(Model-based):事先给出了转移概率矩阵P
马尔可夫奖励过程(MRP)
- 和马尔可夫过程相比,加入了奖励r,加入了折扣因子gamma,gamma在0~1之间。
- 马尔可夫奖励过程是一个四元组⟨S, P, R, γ⟩
- 需要折扣因子的原因是
- 使未来累积奖励在数学上易于计算
- 由于可能经过某些重复状态,避免累积奖励的计算成死循环
- 用于表示未来的不确定性
- gamma越大表示越看中未来的奖励
值函数(value function)
- 引入了值函数(value function),给每一个状态一个值V,以从当前状态St到评估未来的目标G的累积折扣奖励的大小
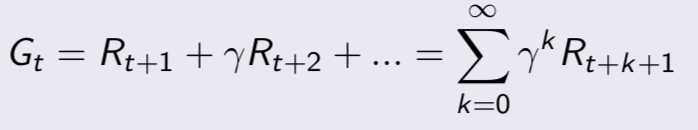
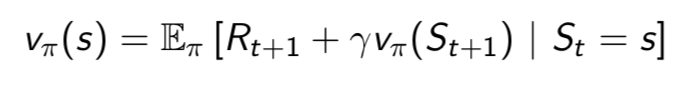
MRP求解
- v = R + γPv (矩阵形式)
- 直接解出上述方程时间复杂度O(n^3), 只适用于一些小规模问题
马尔可夫决策过程(MDP)
- 加入了一个动作因素a,用于每个状态的决策
- MDP是一个五元组⟨S, A, P, R, γ⟩
- 策略policy是从S到A的一个映射
效用函数
- 相比于值函数,加入了一个动作因素

优化的值函数
- 为了求最佳策略,在值函数求解时,选择一个最大的v来更新当前状态对应的v
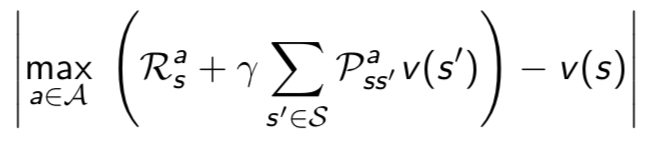
贝尔曼等式
- 和值函数的求解方法相比,不需要从当前状态到目标求解,只需要从当前状态到下一状态即可(根据递推公式)

参考
david siver 课程
https://home.cnblogs.com/u/pinard/
DQN(Deep Reiforcement Learning) 发展历程(一)的更多相关文章
- DQN(Deep Reiforcement Learning) 发展历程(五)
目录 值函数的近似 DQN Nature DQN DDQN Prioritized Replay DQN Dueling DQN 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) ...
- DQN(Deep Reiforcement Learning) 发展历程(三)
目录 不基于模型(Model-free)的预测 蒙特卡罗方法 时序差分方法 多步的时序差分方法 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发展历程(四) DQN发展 ...
- DQN(Deep Reiforcement Learning) 发展历程(四)
目录 不基于模型的控制 选取动作的方法 在策略上的学习(on-policy) 不在策略上的学习(off-policy) 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发 ...
- DQN(Deep Reiforcement Learning) 发展历程(二)
目录 动态规划 使用条件 分类 求解方法 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发展历程(四) DQN发展历程(五) 动态规划 动态规划给出了求解强化学习的一种 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- Deep Reinforcement Learning 基础知识(DQN方面)
Introduction 深度增强学习Deep Reinforcement Learning是将深度学习与增强学习结合起来从而实现从Perception感知到Action动作的端对端学习的一种全新的算 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- Deep Reinforcement Learning: Pong from Pixels
这是一篇迟来很久的关于增强学习(Reinforcement Learning, RL)博文.增强学习最近非常火!你一定有所了解,现在的计算机能不但能够被全自动地训练去玩儿ATARI(译注:一种游戏机) ...
- 论文笔记之:Human-level control through deep reinforcement learning
Human-level control through deep reinforcement learning Nature 2015 Google DeepMind Abstract RL 理论 在 ...
随机推荐
- Python数据模型
引言 像大多数人一样,我在对一直传统的面向过程语言C一知半解之后,走进了面向对象的世界,尽管对OOP一无所知,还好Python还保留有函数式编程,这使得我才不那么抵触,直到现在,习惯了面向对象之后,也 ...
- HTML页面局部刷新
/.事件响应刷新:有请求才会刷新 1.通过JS HTML DOM或jQuery获取HTML元素,通过DOM方法或jQuery方法监听页面事件,获取用户请求: 2.通过Ajax将用户请求提交至服务器,服 ...
- redis 单节点安装
wget http://download.redis.io/releases/redis-5.0.3.tar.gz 1.下载解压 2.make编译 3.提示没有安装安装gcc,安装gcc yum in ...
- CSS中文乱码解决方法
原文链接:http://caibaojian.com/css-unicode.html 我的CSS里面有一个content用到了中文,作用主要是在前端日报文章中显示出“网页链接”这四个字,然而打开百度 ...
- element-ui 中的table的列隐藏问题
element-ui 中的table和bootstrap中的table的某些设置还是有一定的差别的.之前用bootstrap做的表格,想要实现简短列和详细列的切换.因为详细列实在有太多列了,拉动滚动条 ...
- [基础知识]row类visible使用
使用row的visibe属性,要反向遍历rowset,因为如果正向遍历,rowset是实时变化的,行号是错误的.正确代码如下: Local integer &k; For &k = & ...
- 【element】改变el-table样式,实现全局滚动,固定表头和表尾
后台管理系统,多半都有表格,数据量大的时候,需要固定表头或者底部. 因为饿了么是局部滚动的,现在我们需要改饿了么某些样式实现全局滚动 饿了么局部滚动 全局滚动demo 删除height=200 固 ...
- ActiveReports 报表应用教程 (11)---交互式报表之文档目录
通过文档目录,用户可以非常清晰的查看报表数据结构,并能方便地跳转到指定的章节,最终还可以将报表导出为PDF等格式的文件.本文以2012年各月产品销售分类汇总报表为例,演示如何在葡萄城ActiveRep ...
- Linux nohup命令应用简介--让Linux的进程不受终端影响
nohup命令应用简介--让Linux的进程不受终端影响 by:授客 QQ:1033553122 #开启ping进程 [root@localhost ~]# ping localhost & ...
- Adobe Flash Builder 4.6 打开时提示Failed to create the Java Virtual Machine
最近使用actionscript来编程,用到Adobe Flash Builder 工具,之前一直用着都没事的,今天打开突然就报了这个错误,然后就打不开了 好了,不多说,直接来吧. 首先在你的Adob ...