kafka 消费者 timeout 6000
kafka 消费者 timeout 6000
1:查看zookeeper 的状态,kafka默认是自带zookeeper配置,我建议安装单独的zookeeper 服务,并且配置文件也很简单..直接改zookeeper 的host 跟port 就行;
zookeeper 状态查看命名,参考官网:https://zookeeper.apache.org/doc/r3.4.8/zookeeperAdmin.html
stat
conf
server 等四字命令
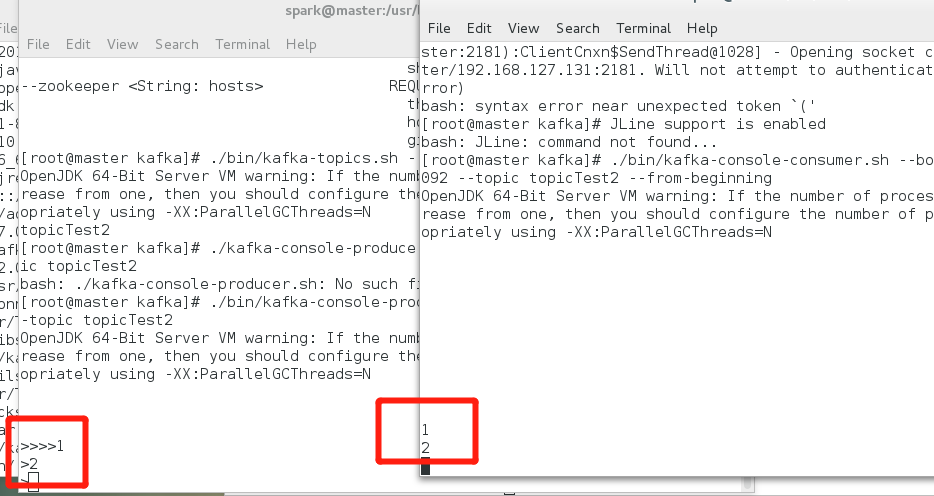
2、生产者,消费者的验证:需要开两个终端:
kafka 消费者 timeout 6000的更多相关文章
- 4 kafka集群部署及kafka生产者java客户端编程 + kafka消费者java客户端编程
本博文的主要内容有 kafka的单机模式部署 kafka的分布式模式部署 生产者java客户端编程 消费者java客户端编程 运行kafka ,需要依赖 zookeeper,你可以使用已有的 zo ...
- kafka消费者客户端(0.9.0.1API)
转自:http://orchome.com/203 kafka客户端从kafka集群消费消息(记录).它会透明地处理kafka集群中服务器的故障.它获取集群内数据的分区,也和服务器进行交互,允许消费者 ...
- Kafka消费者-从Kafka读取数据
(1)Customer和Customer Group (1)两种常用的消息模型 队列模型(queuing)和发布-订阅模型(publish-subscribe). 队列的处理方式是一组消费者从服务器读 ...
- Kafka权威指南 读书笔记之(四)Kafka 消费者一一从 Kafka读取数据
KafkaConsumer概念 消费者和消费者群组 Kafka 消费者从属于消费者群组.一个群组里的消费者订阅的是同一个主题,每个消费者接收主题一部分分区的消息. 往群组里增加消费者是横向伸缩消费能力 ...
- Kafka消费者APi
Kafka客户端从集群中消费消息,并透明地处理kafka集群中出现故障服务器,透明地调节适应集群中变化的数据分区.也和服务器交互,平衡均衡消费者. public class KafkaConsumer ...
- JAVA封装消息中间件调用二(kafka消费者篇)
上一遍我简单介绍了kafka的生成者使用,调用方式比较简单,今天我给大家分享下封装kafka消费者,作为中间件,我们做的就是最大程度的解耦,使业务方接入我们依赖程度降到最低. 第一步,我们先配置一个消 ...
- kafka消费者客户端
Kafka消费者 1.1 消费者与消费者组 消费者与消费者组之间的关系 每一个消费者都隶属于某一个消费者组,一个消费者组可以包含一个或多个消费者,每一条消息只会被消费者组中的某一个消费者所消费.不 ...
- Kafka 学习之路(四)—— Kafka消费者详解
一.消费者和消费者群组 在Kafka中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响.Kafka之所以要引入消费者群组这个概念是因为Kafka消费者经常会做一些 ...
- Kafka 系列(四)—— Kafka 消费者详解
一.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响.Kafka 之所以要引入消费者群组这个概念是因为 Kafka 消费者经 ...
随机推荐
- JVM总结-invokedynamic
前不久,“虚拟机”赛马俱乐部来了个年轻人,标榜自己是动态语言,是先进分子. 这一天,先进分子牵着一头鹿进来,说要参加赛马.咱部里的老学究 Java 就不同意了呀,鹿又不是马,哪能参加赛马. 当然了,这 ...
- java的list遍历
for(String str : list) {//增强for循环,其内部实质上还是调用了迭代器遍历方式,这种循环方式还有其他限制,不建议使用. System.out.println(str); } ...
- 数据库设计和ER模型-------之ER模型的基本概念(第二章)
ER模型(实体联系模型)的基本元素 实体:是一个数据对象,在ER模型中,实体用方框表示,方框内注明实体的名称 联系:表示一个或多个实体之间的关联关系,联系用菱形框表示,并用线段将其与相关的实体联系起来 ...
- Vue.js基础(一)
Vue.js的雏形: 数据绑定: 1,单向 {{输出}} 数据=>视图 2,双向 v-model 数据<=>视图 3,{{*msg}} 数据只绑 ...
- python-开放类优化内存性能
开放类:在运行期间,可动态向实例或类添加新成员,方法 1.实例不能添加方法到类,反之可以 class A: pass a = A() a.func = lambda x: x+1 a.func # & ...
- [Unity工具]批量修改字体
效果图: using System.IO; using System.Text; using UnityEditor; using UnityEngine; using UnityEngine.UI; ...
- python读取grib grib2气象数据
如何读取GRIB数据?快看Python大神整理的干货! 橙子心法 百家号17-11-0116:30 GRIB是WMO开发的一种用于交换和存储规则分布数据的二进制文件格式,主要用来表示数值天气预报的产品 ...
- python时间日期字符串各种
python时间日期字符串各种 第一种 字符串转换成各种日期 time 库 # -*- coding: utf-8 -*- import time, datetime # 字符类型的时间 tss1 = ...
- hdfs线上修改 nameserivce
hdfs线上修改 nameserivce(ns1 修改为 ns2) 1.去core-site.xml.hdfs-site.xml 把ns1 -> ns2 同步所有节点 2.去journal 数据 ...
- xsync
shell 小工具,用于集群搭建: xsync脚本基于rsync工具,rsync 远程同步工具,主要用于备份和镜像.具有速度快.避免复制相同内容和支持符号链接的优点,它只是拷贝文件不同的部分,因而减 ...