开发工具之Spark程序开发详解
一 使用IDEA开发Spark程序
1、打开IDEA的官网地址,地址如下:http://www.jetbrains.com/idea/

2、点击DOWNLOAD,按照自己的需求下载安装,我们用免费版即可。

3、双击ideaIU-15.0.2.exe安装包,点击Next。

4、选择安装路径,点击Next。

5、可以选择是否创建桌面快捷方式,然后点击Next。
6、点击Install。
7、安装过程

8、点击Finish,安装成功
9、双击IntelliJ IDEA 15.0.2的图标,打开IntelliJ IDEA。

10、可以导入自己的设置,没有就选择下面的即可,然后点击OK。

11、选择自己喜欢的风格
(1) 风格1

(2) 风格2
12、选择完风格后,点击Next Default plugins
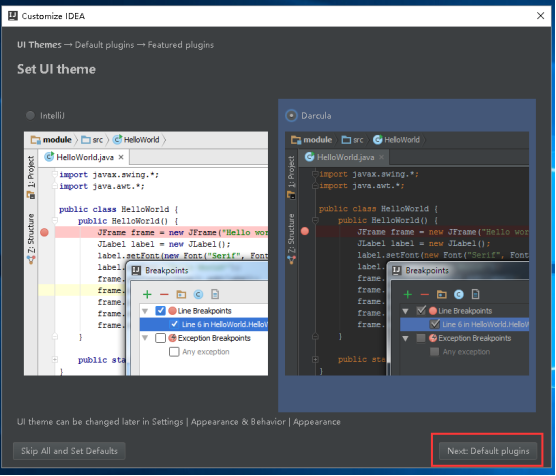
13、点击Next Featured plugins
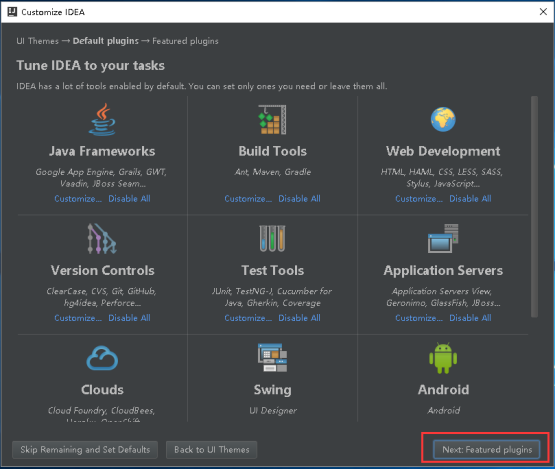
14、点击Scala Custom Languages 下面的Install

15、安装过程
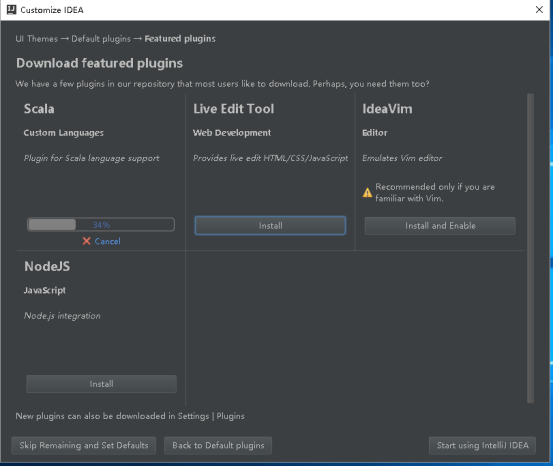
16、显示Installed就代表安装成功了,然后点击Start using IntelliJ IDEA。
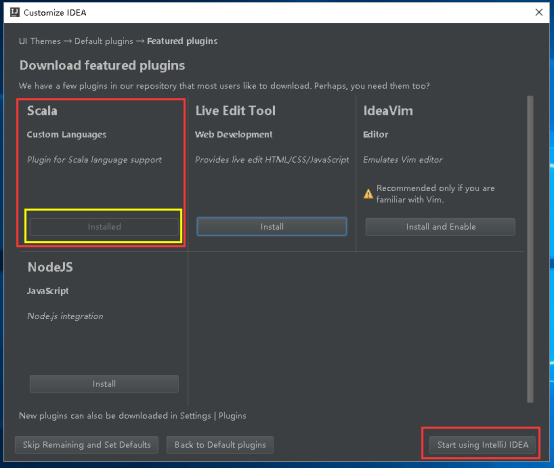
17、点击Create New Project,创建新工程。
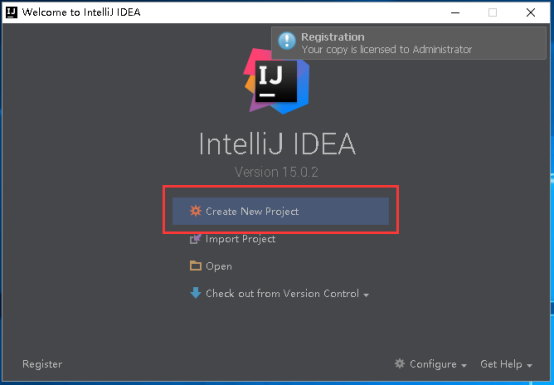
18、选择Scala,点击Next。
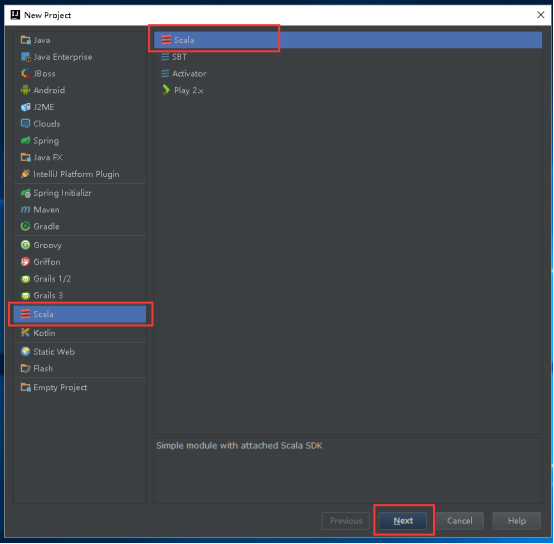
19、填写Project name和Project location。
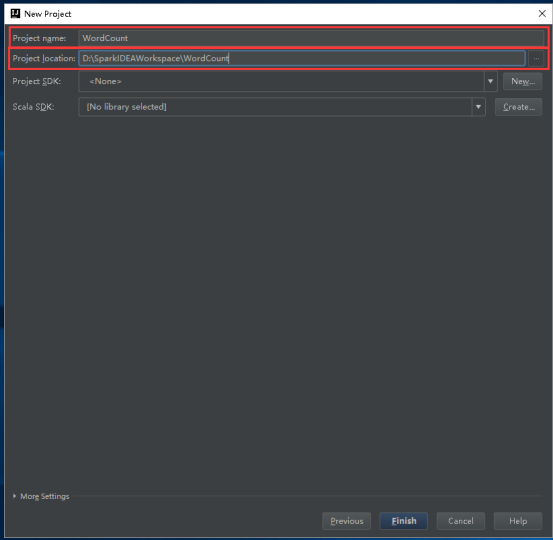
20、设置Project SDK,点击New。
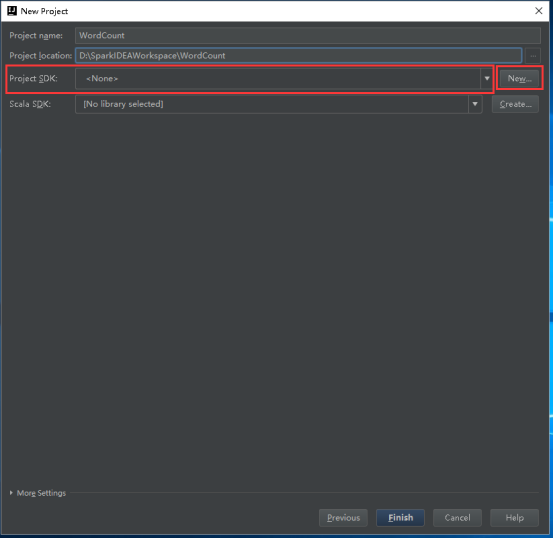
21、点击New打开的小窗口里点击JDK。

22、选择安装JDK的路径,点击OK
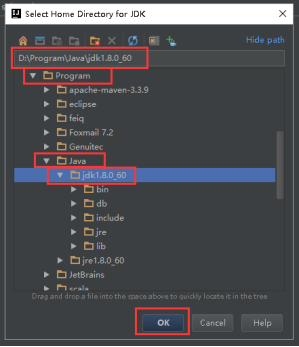
23、Project SDK会变成如下面图所示,是你安装的JDK版本

24、设置Scala SDK,点击Create。
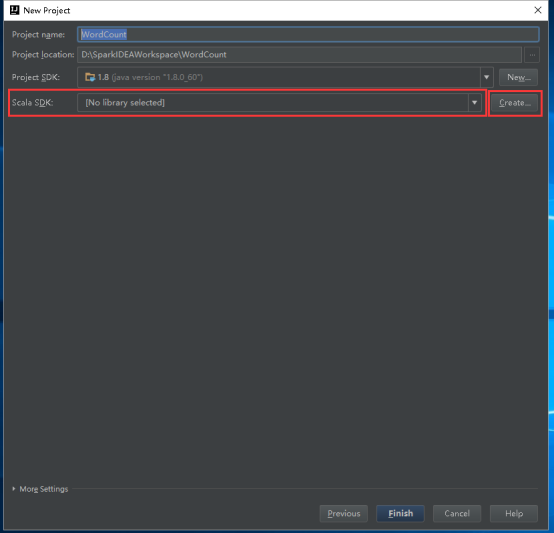
25、选择这台机器安装的2.10.x版本,然后点击OK。
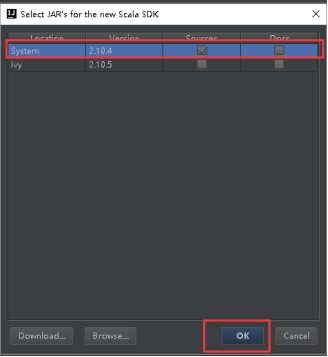
26、然后就变成如图所示,然后点击Finish。
27、出现这个提示,直接点击OK。

28、出现这个窗口,把Show Tips on Startup勾掉,点击Close即可。
29、项目创建成功以后的目录如下:

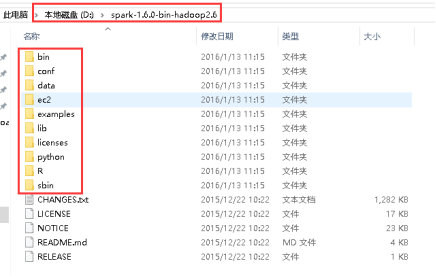
30、下载spark-1.6.0-bin-hadoop2.6.tgz,解压spark-1.6.0-bin-hadoop2.6.tgz,解压以后目录如下:
31、添加Spark的jar依赖,File-> Project Structure -> Libraries,点击号,选择Java。

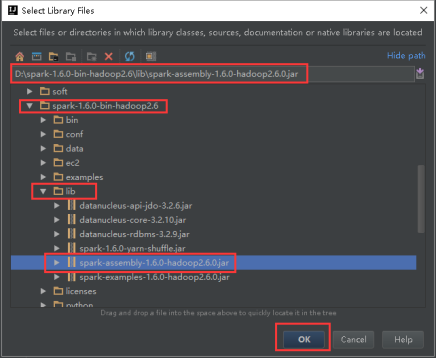
32、进入到解压以后的spark-1.6.0-bin-hadoop2.6的lib目录下,选择spark-assembly-1.6.0-hadoop2.6.0.jar,如下图所示,然后点击OK。
33、点击OK。

34、如下图所示,然后点击OK。

35、项目会变成如下图所示。

36、右击src -> New -> Package。
37、填写好包名,点击OK。
38、右击com.dt.spark -> New -> Scala Class。

39、Name填写WordCount,Kind里选择Object,点击OK。
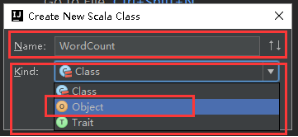
40、WordCount里添加main方法,如下图。

41、开始编写Spark WordCount项目,创建SparkConf,设置conf的参数,设置应用程序名称,使用local模式执行,图里的第1步。

42、创建SparkContext对象,图里第2步。

43、读取本地文件,图里的第3步。

44、将每一行的字符串拆分成单个的单词,图里的第4.1步。

45、在单词拆分的基础上对每个单词实例计数为1,也就是word => (word, 1),图里4.2步。
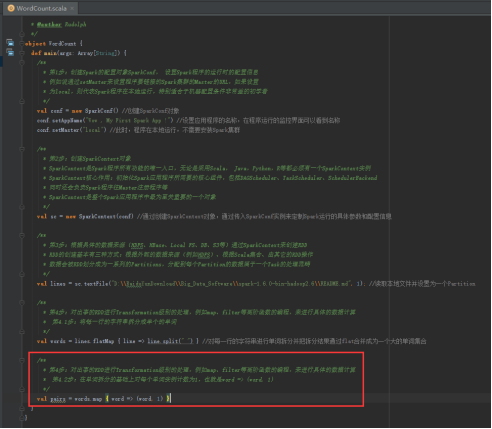
46、每个单词实例计数为1的基础之上统计每个单词在文件中出现的总次数,图里4.3步。
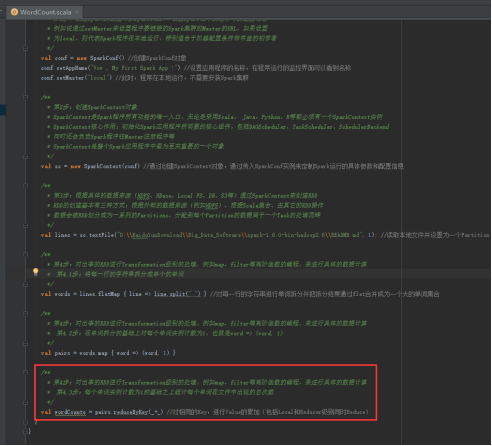
47、打印计算结果,图里的第5步。
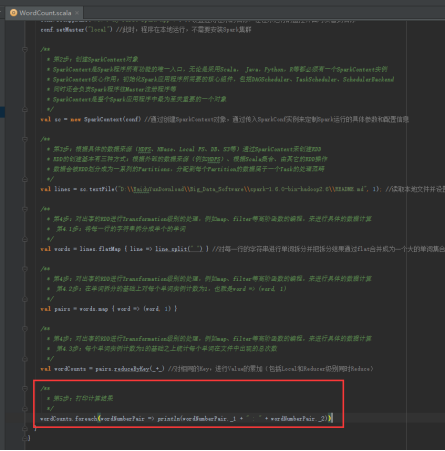
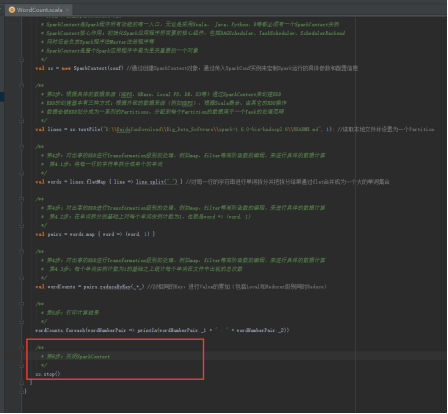
48、关闭SparkContext,图里的第6步。
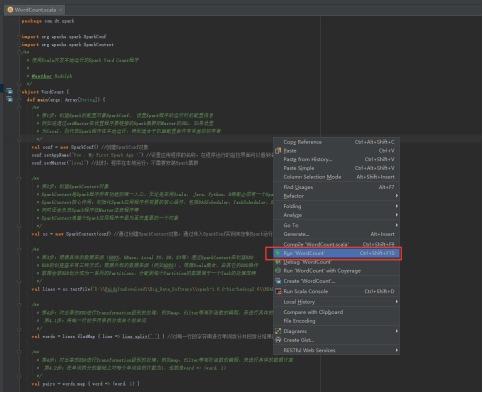
49、运行开发的项目,右击WorkCount.scala文件 -> Run ‘Word Count’。
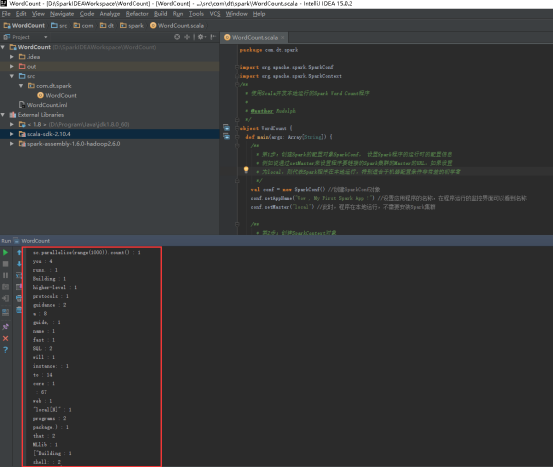
50、看见这样的结果,就代表成功了。
二 使用Scala IDE 开发Spark程序
1、打开Scala IDE for Eclipse的官网,官网地址:http://scala-ide.org/
2、点击Download IDE。
3、下载对应的版本。
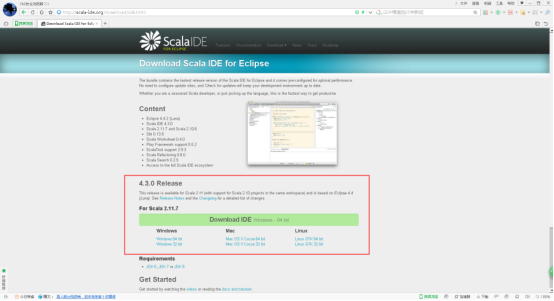
4、scala-SDK-4.3.0-vfinal-2.11-win32.win32.x86_64.zip为例,解压缩。
5、双击打开eclipse.exe。

6、选择一个工作目录,然后点击OK。
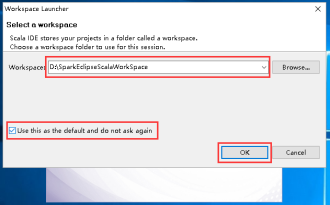
7、在打开的窗口中,File -> New -> Scala Project。
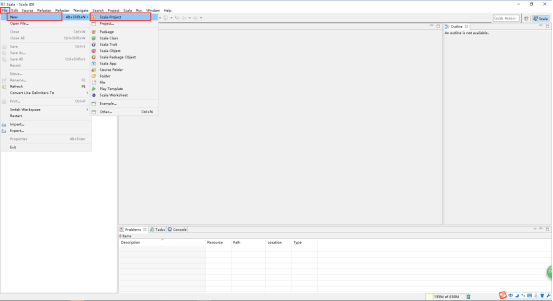
8、写好Project name,点击Next。

9、点击Finish。
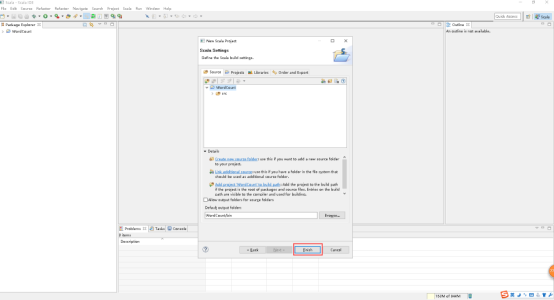
10、修改JRE System Library。
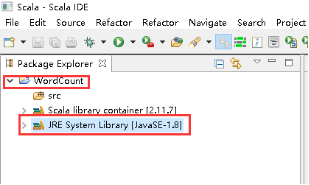
11、右击JRE System Library -> Build Path -> Configure Build Path...。

12、点击JRE System Library -> Edit。

13、选择Alternate JRE -> Installed JREs...。

14、点击Add...。

15、选择Standard VM,点击Next。
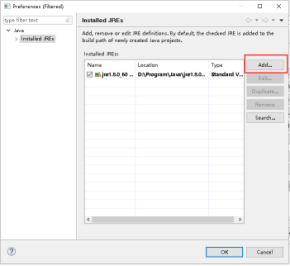
16、点击Directory...,选择本地文件安装JDK的安装目录,点击Finish。
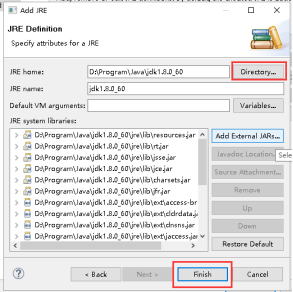
17、选择刚才加入的JDK,点击OK。
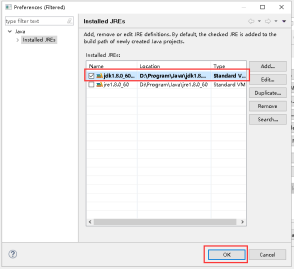
18、下拉列表里选择刚才加入的JDK,点击Finish。
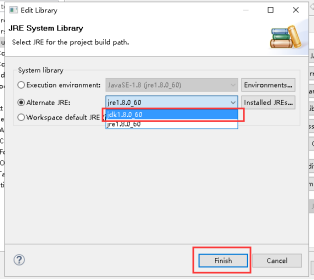
19、点击OK。

20、设置Scala library container。
21、项目上有右击 -> Properties。
22、打开的窗口点击Scala Compiler。
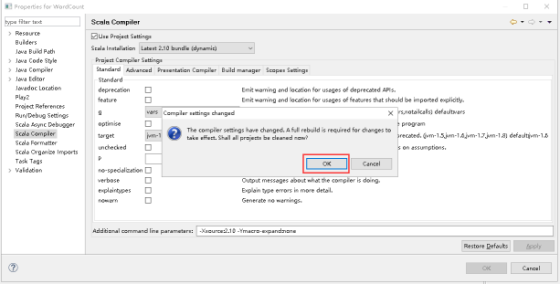
23、Use Project Settings打钩,打开Scala Installation下拉列表,选择Latest 2.10 bundle(dynamic),点击OK。
24、点击OK。
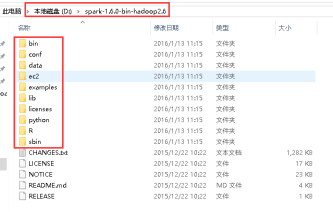
25、下载spark-1.6.0-bin-hadoop2.6.tgz,解压spark-1.6.0-bin-hadoop2.6.tgz,解压以后目录如下:
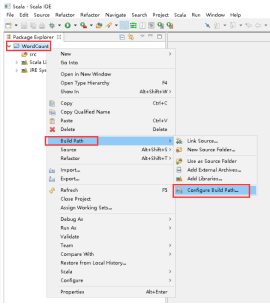
26、添加Spark的jar依赖,项目右击 -> Build Path -> Configure Build Path...。
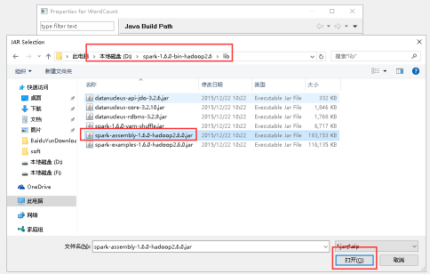
27、点击Libraries -> Add External JARs...。

28、选择lib目录下的spark-assembly-1.6.0-hadoop2.6.0.jar文件,点击打开。
29、点击OK。

30、项目里创建包,右击src -> New -> Package。
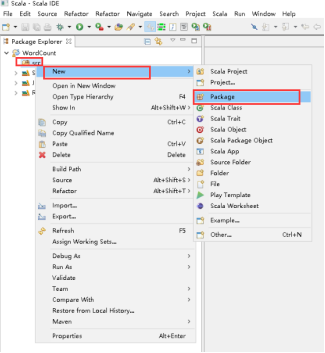
31、填写好Name,点击Finish。
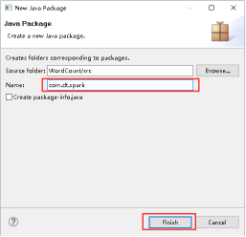
32、创建Scala Object,右击com.dt.spark -> New -> Scala Object。
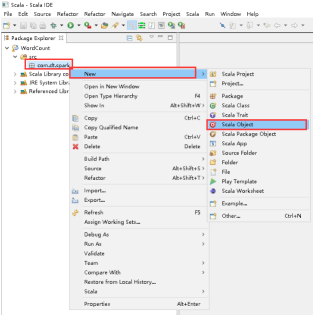
33、填写好Name,点击Finish。
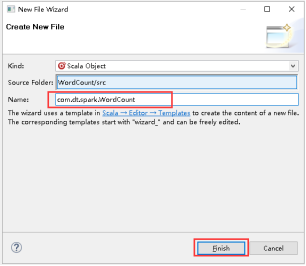
34、开始编写WordCount,写Title。
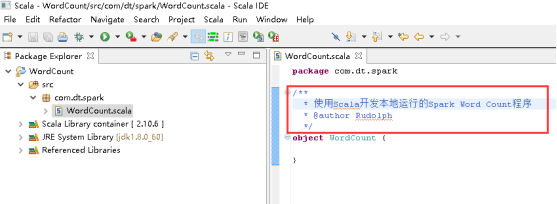
35、添加main方法。

36、创建SparkConf对象,图里的第1步。

37、创建SparkContext对象,图里的第2步。

38、读取本地文件,图里的第3步

39、将每一行的字符串拆分成单个的单词,图里的第4.1步。
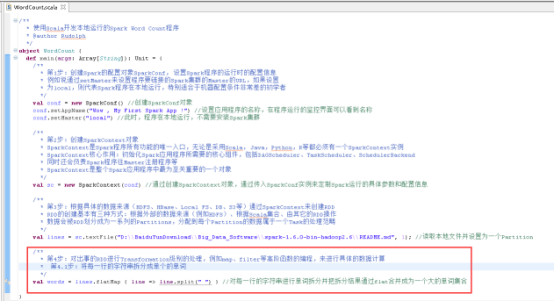
40、在单词拆分的基础上对每个单词实例计数为1,也就是word => (word, 1),图里4.2步。
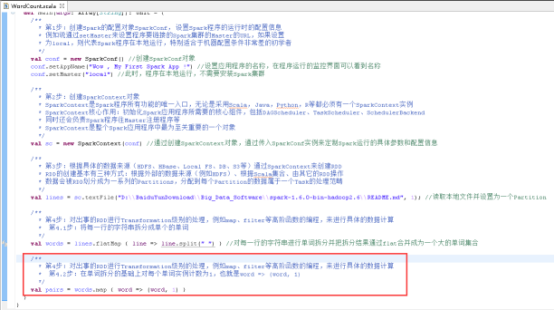
41、每个单词实例计数为1的基础之上统计每个单词在文件中出现的总次数,图里4.3步。
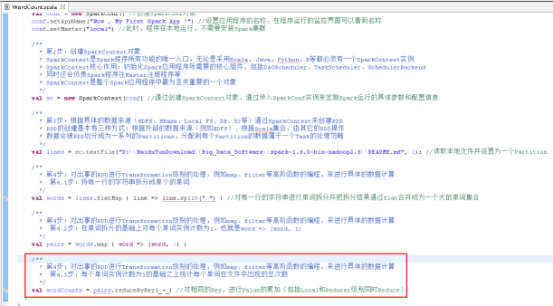
42、打印计算结果,图里的第5步。
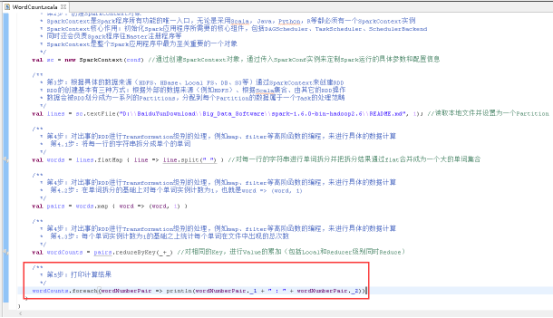
43、关闭SparkContext,图里的第6步。
44、运行项目,右击WorkCount.scala文件 -> Run As -> Scala Application。
45、看见这样的结果,就代表成功了。

开发工具之Spark程序开发详解的更多相关文章
- 最锋利的Visual Studio Web开发工具扩展:Web Essentials详解
原文:最锋利的Visual Studio Web开发工具扩展:Web Essentials详解 Web Essentials是目前为止见过的最好用的VS扩展工具了,具体功能请待我一一道来. 首先,从E ...
- 最锋利的Visual Studio Web开发工具扩展:Web Essentials详解(转)
Web Essentials是目前为止见过的最好用的VS扩展工具了,具体功能请待我一一道来. 首先,从Extension Manager里安装:最新版本是19号发布的2.5版 然后重启你的VS开发环境 ...
- 最锋利的Visual Studio Web开发工具扩展:Web Essentials详解【转】
Web Essentials是目前为止见过的最好用的VS扩展工具了,具体功能请待我一一道来. 首先,从Extension Manager里安装:最新版本是19号发布的2.5版 然后重启你的VS开发环境 ...
- VS2010开发程序打包详解
VS2010开发程序打包详解 转自:http://blog.sina.com.cn/s/blog_473b385101019ufr.html 首先打开已经完成的工程,如图: 下面开始制作安装程序包. ...
- Hadoop:开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
问题: windows开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary ...
- [ 转载 ] Java开发中的23种设计模式详解(转)
Java开发中的23种设计模式详解(转) 设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类 ...
- Spark面试题(七)——Spark程序开发调优
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- Java基础-DButils工具类(QueryRunner)详解
Java基础-DButils工具类(QueryRunner)详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如果只使用JDBC进行开发,我们会发现冗余代码过多,为了简化JDBC ...
- R语言服务器程序 Rserve详解
R语言服务器程序 Rserve详解 R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大. R语言作为统计学一门语言,一直在小众领域闪耀着光芒.直到 ...
随机推荐
- arrayfun用法(转)
http://blog.sina.com.cn/s/blog_7cf4f4460101bnhh.html 利用arrayfun函数可以避免无谓的循环,从而大大提高代码的简介性.1.A=ARRAYFUN ...
- xml的xsi:type序列化和反序列化
最近在做HL7V3的对接,关于XML的序列化和反序列化遇到xsi:type的问题解决方法 实体类定义: public class HL7V3_ProviderOrganization { public ...
- Rancher 添加主机无法显示、添加主机无效的解决办法
在 Rancher UI 中,添加主机,在 Shell ssh 运行了,然后 点击 “关闭” 按钮,发现没有显示如何主机. 第一步,先去查看应用是否正常,就是 应用 - 全部应用 如果显示是 unhe ...
- 关于在Win10的Windows功能中没有IE11的问题
大概是用Win7的时候把IE关掉了,升级Win10之后就发现IE不见了,在Windows功能里面也没有:最近因为某些原因需要用到IE,还是用的虚拟机. 网上找到的方法普遍是执行命令:FORFILES ...
- IIS中“绑定”,“IP地址全部未分配”到底是个什么玩意
最好是选择“全部未分配”,用这个选项时,服务器本机,在IE浏览器地址栏输入http://localhosts/ 或127.0.0.1 可以打开本机架设的网站的主页,也可以输入内网IP地址打开内网的网站 ...
- 2018.09.01 09:22 Exodus
Be careful when writing in the blog garden. Sometimes you accidentally write something wrong, and yo ...
- 粗略的整改一下blog
一.先找个简约的模板:看个人喜好咯 二.页面定制CSS: 1.首先,查看主页源码,了解一下各个标签的id,引用的class等 2.通过操作相应的id,class,和标签,进行个性化.这里需要具备看懂和 ...
- JavaScript中的单例模式
单例模式 在JavaScript中,单例(Singleton)模式是最基本又最有用的模式之一.这种模式提供了一种将代码组织为一个逻辑单元的手段,这个逻辑单元中的代码可以通过单一的变量进行访问.确保单例 ...
- BZOJ3569:DZY Loves Chinese II(线性基)
Description 神校XJ之学霸兮,Dzy皇考曰JC. 摄提贞于孟陬兮,惟庚寅Dzy以降. 纷Dzy既有此内美兮,又重之以修能. 遂降临于OI界,欲以神力而凌♂辱众生. 今Dzy有一魞歄图, ...
- Vue 下拉列表 组件模板
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...