stark组件之过滤操作【模仿Django的admin】
一、先看下django的admin是如何实现过滤操作
首先在配置类中顶一个list_filter的列表,把要过滤的字段作为元素写i进去就可以了
class testbook(admin.ModelAdmin):
# 第一步,定义一个函数,必须要接受三个参数
def test_action(self,request,queryset):
"""
:param request:
:param queryset:这个就是需要批量操作的queryset对象
:return:
"""
print(queryset)
# 第二步,为这个函数对象赋值一个新的属性
test_action.short_description = "测试批量操作的函数"
# 第三步,将函数对象添加到actions这个列表中
actions = [test_action]
list_filter = ["auther","publish"]
重点是这里

最后我们看下页面的效果
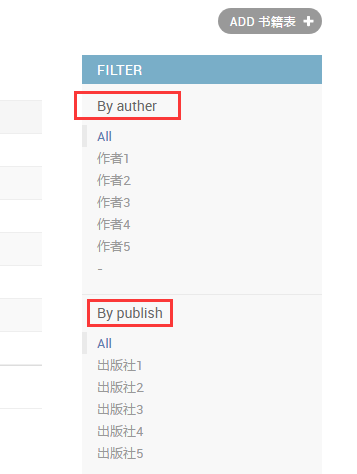
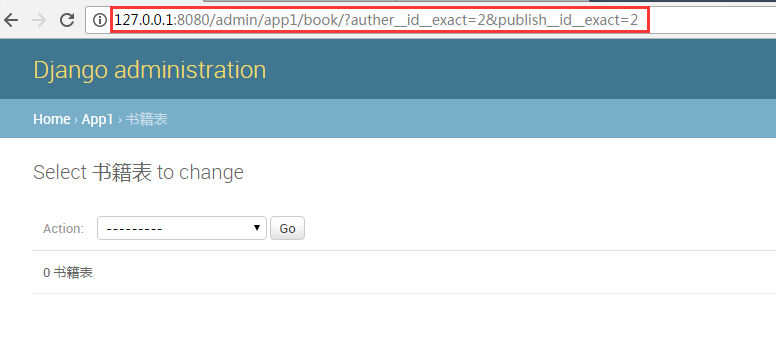
下面我们重点看下点击过滤的元素的url
先点击一下作者2

然后在点击一下出版社2
二、下面在我们自己是如何实现类似Django的admin的过滤操作
1、先把用到的知识点梳理一下
.active{
color: #2b542c!important;
}
如果一个class的属性优先级不够,可以用上面的方式来实现
2、从request.GET中拿到参数,然后把这个参数中的一些数值改一下,然后在渲染回到GET方式在url中传参的样式,用urlencode方法
import copy
parms = copy.deepcopy(self.request.GET)
parms[filter_str] = obj.id
_url = "?{url}".format(url = parms.urlencode())
3、通过字段的字符串去获取对应的字段对象,然后在通过字段对象获取这个字段对象的表对象的方法,这里注意,只有一对多,一对一,外键的字段可以这样操作
filter_obj = self.config.model._meta.get_field(filter_str)
# 通过字符串拿到这个字符串对应的字段对象 # filter_obj
# app1.book.auther <
#
# class 'django.db.models.fields.related.ManyToManyField'>
#
# filter_obj
# app1.book.publish <
#
# class 'django.db.models.fields.related.ForeignKey'>
#
# filter_obj
# app1.book.price <
#
# class 'django.db.models.fields.DecimalField'> data_list = filter_obj.rel.to.objects.all() # <QuerySet [<auther: 作者1>, <auther: 作者2>, <auther: 作者3>, <auther: 作者4>, <auther: 作者5>]>
# < QuerySet[ < publist: 出版社1 >, < publist: 出版社2 >, < publist: 出版社3 >, < publist: 出版社4 >, < publist: 出版社5 >] >
3、判断字典中是否有某个k,这里直接用get方法
if parms.get("p",None):
del parms["p"]
# 这 if parms.get("p",None):
del parms["p"]
# 这里做一个处理,点击过滤,把page的参数干掉里做一个处理,点击过滤,把page的参数干掉
4、判断某个实例是否为某个类的实例,下面这个例子是判断i_obj这个对象是否为一个多对多这个类的实例的,这个类必须要用元组传递进去
from django.db.models.fields.related import ManyToManyField
i_obj = obj._meta.get_field(i)
if isinstance(i_obj,(ManyToManyField,)):
many = getattr(obj, i)
many_query_set = many.all()
temp = ""
for o in many_query_set:
temp = temp + str(o) + "--"
先导入类,然后在判断

下面我们看下我们的过滤是如何实现的
1、先看下页面的效果,右边就是我们实现的效果
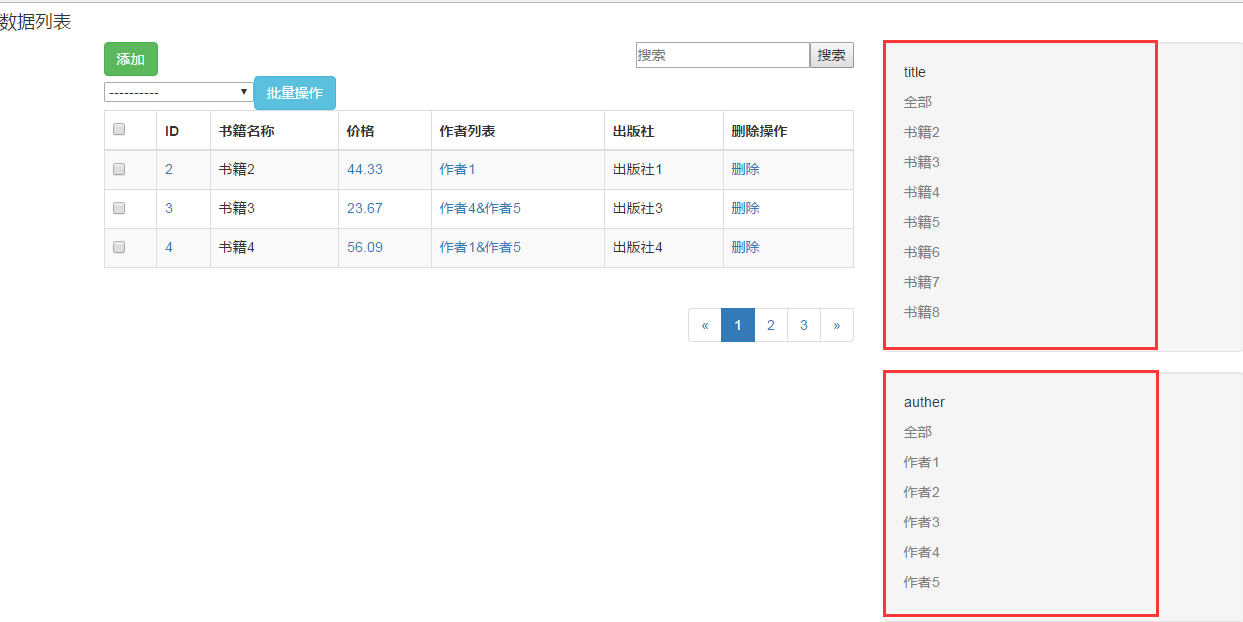
2、首先在模型表的配置类里定了一个我们要支持的过滤的字段
class bookclass(stark.Starkclass):
list_display = ["id","title","price","auther","publish"]
list_display_links = ["id","price","auther"]
search_fields = ["title","price"]
def test_action(self,request,queryset):
print(queryset,)
actions = [test_action]
# test_action.__name__ = "测试批量操作的函数"
test_action.short_description = "测试批量操作的函数"
modelformclass = mybookmodelform
list_filter = ["title","auther", "publish",]

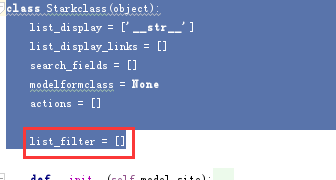
当然我们也需要在父类中定义了一个同样的字段,这个是我们的常规套路
class Starkclass(object):
list_display = ['__str__']
list_display_links = []
search_fields = []
modelformclass = None
actions = [] list_filter = []
3、然后我们看下前端的代码的实现
<div class="col-md-4">
<div class="filter">
{% for k,v in get_filter.items %}
<div class="well">
<p>{{ k }}</p>
{% for tag in v %}
<p>{{ tag|safe }}</p>
{% endfor %}
</div>
{% endfor %}
</div>
这里我们在截图看下前端的效果

这里其实一个面板,我们使用了bootstrap的well的样式,我们后端传递给前端的其实是一个字段,字典的k值是我们的要过滤的字段,字典的v值是我们这个字段对应的所有的值的a标签
4、下面我们看下具体的视图函数,首先因为这个和显示相关,我们还是把主要代码放在showlist这个类中来实现
get_filter = showlist.get_filter_link_tag()
return render(request,"list_view.html",{"data_list":data_list,"title_list":title_list,"page_str":page_str,"search_fields":self.search_fields,"action_str":action_str,
"get_filter":get_filter
})
调用showlist类的get_filter_link_tag这个函数,然后将返回值渲染到前端
5、下面我们看下get_filter_link_tag这个函数的代码
def get_filter_link_tag(self):
link_dict = {}
import copy
for filter_str in self.config.list_filter:
parms = copy.deepcopy(self.request.GET)
# 通过字符串拿到这个字符串对应的字段对象
filter_obj = self.config.model._meta.get_field(filter_str)
print("filter_obj",filter_obj,type(filter_obj)) # filter_obj
# app1.book.auther <
#
# class 'django.db.models.fields.related.ManyToManyField'>
#
# filter_obj
# app1.book.publish <
#
# class 'django.db.models.fields.related.ForeignKey'>
#
# filter_obj
# app1.book.price <
#
# class 'django.db.models.fields.DecimalField'> # 获取当前的参数值,主要是为了吧选中的a标签加一个active的属性
cid = int(self.request.GET.get(filter_str,0)) from django.db.models.fields.related import ManyToManyField
from django.db.models.fields.related import ForeignKey
if isinstance(filter_obj,(ManyToManyField,ForeignKey)):
print(filter_obj.rel.to.objects.all())
# 通过字段对象跨表查询,必须是ManyToManyField或者ForeignKey的字段, # <QuerySet [<auther: 作者1>, <auther: 作者2>, <auther: 作者3>, <auther: 作者4>, <auther: 作者5>]>
# < QuerySet[ < publist: 出版社1 >, < publist: 出版社2 >, < publist: 出版社3 >, < publist: 出版社4 >, < publist: 出版社5 >] >
data_list = filter_obj.rel.to.objects.all()
else:
data_list = self.config.model.objects.all() temp = [] # 这里要加一个全选的a标签,如果点出版社的是全部,则把参数中的出版社的标签全部去掉,如果点的是作者的全部,则把参数中作者的标签全部去掉
all_dict = copy.deepcopy(parms)
if all_dict:
if all_dict.get(filter_str,None):
del all_dict[filter_str] print(parms,"parms",filter_str)
_url = "?{url}".format(url=all_dict.urlencode())
all_label = "<a href='{url}'>全部</a>".format(url = _url)
temp.append(all_label)
# 处理全部的a标签的的代码
# -------------------------------------------------------------------- for obj in data_list:
parms[filter_str] = obj.id
if parms.get("p",None):
del parms["p"]
# 这里做一个处理,点击过滤,把page的参数干掉 _url = "?{url}".format(url = parms.urlencode())
# print(cid,obj.id,"------------------------------") # 这里做一下判断,如果当前的id和现在循环的id一样,则需要给这个a标签加一个属性,用以区分
if int(cid) == obj.id:
a_str = "<a class='active' href='{url}'>{obj}</a>".format(obj=str(obj), url=_url)
else:
a_str = "<a href='{url}'>{obj}</a>".format(obj=str(obj),url = _url)
temp.append(a_str)
link_dict[filter_str] = temp
return link_dict
首先循环我们定义的过滤的字典,通过字符串拿到这个字符串对应的字段对象

然后拿到GET方式传递过来的参数,这个参数主要是判断当然是否有我这个字段的过滤规则,有的话,则把当前过滤规则对应的a标签用active标记出来
# 获取当前的参数值,主要是为了吧选中的a标签加一个active的属性
cid = int(self.request.GET.get(filter_str,0))
这里主要分别对多对多,一对多和普通字段做过滤,因为多对多字段和一对多可以做跨表查询,而普通字段是不能做跨表查询
from django.db.models.fields.related import ManyToManyField
from django.db.models.fields.related import ForeignKey
if isinstance(filter_obj,(ManyToManyField,ForeignKey)):
print(filter_obj.rel.to.objects.all())
# 通过字段对象跨表查询,必须是ManyToManyField或者ForeignKey的字段, # <QuerySet [<auther: 作者1>, <auther: 作者2>, <auther: 作者3>, <auther: 作者4>, <auther: 作者5>]>
# < QuerySet[ < publist: 出版社1 >, < publist: 出版社2 >, < publist: 出版社3 >, < publist: 出版社4 >, < publist: 出版社5 >] >
data_list = filter_obj.rel.to.objects.all()
else:
data_list = self.config.model.objects.all()
下面这段代码主要是为了处理all标签的,点击一下all,会把自己这个面板的字段对应的过滤参数去掉
# 这里要加一个全选的a标签,如果点出版社的是全部,则把参数中的出版社的标签全部去掉,如果点的是作者的全部,则把参数中作者的标签全部去掉
all_dict = copy.deepcopy(parms)
if all_dict:
if all_dict.get(filter_str,None):
del all_dict[filter_str]
print(parms,"parms",filter_str)
_url = "?{url}".format(url=all_dict.urlencode())
all_label = "<a href='{url}'>全部</a>".format(url = _url)
temp.append(all_label)
这里的代码主要是把参数中的页码相关参数去掉,我们点击一下过滤会有问题
for obj in data_list:
parms[filter_str] = obj.id
if parms.get("p",None):
del parms["p"]
# 这里做一个处理,点击过滤,把page的参数干掉 _url = "?{url}".format(url = parms.urlencode())
下面的代码就是返回一个a标签了的字典,也就是渲染在前端的字典
# 这里做一下判断,如果当前的id和现在循环的id一样,则需要给这个a标签加一个属性,用以区分
if int(cid) == obj.id:
a_str = "<a class='active' href='{url}'>{obj}</a>".format(obj=str(obj), url=_url)
else:
a_str = "<a href='{url}'>{obj}</a>".format(obj=str(obj),url = _url)
temp.append(a_str)
link_dict[filter_str] = temp
return link_dict
还有一个就是显示数据相关,我们页面显示的数据应该是过滤后的数据
q_obj = self.get_search(request)
q_filter_obj = self.get_filter(request) if q_obj and q_filter_obj:
new_data_list = self.model.objects.all().filter(q_obj).filter(q_filter_obj)
elif q_obj and not q_filter_obj:
new_data_list = self.model.objects.all().filter(q_obj)
elif not q_obj and q_filter_obj:
new_data_list = self.model.objects.all().filter(q_filter_obj)
else:
new_data_list = self.model.objects.all()
我们看到这里把获取过滤字段重新写在一个函数中了
下面我们看下这个函数,这里同样用到了Q对象,不过这里的Q对象是and的关系,之前我们做的search是or的关系
def get_filter(self,request):
from django.db.models import Q
q_filter_obj = Q()
q_filter_obj.connector = "and"
for k in self.list_filter:
if request.GET.get(k,None):
temp = (k,request.GET.get(k))
q_filter_obj.children.append(temp)
print(q_filter_obj,"q_filter_obj")
return q_filter_obj
最后我们把filter相关的所有的代码粘贴来,供大家学习
def get_filter_link_tag(self):
link_dict = {}
import copy
for filter_str in self.config.list_filter:
parms = copy.deepcopy(self.request.GET)
# 通过字符串拿到这个字符串对应的字段对象
filter_obj = self.config.model._meta.get_field(filter_str)
print("filter_obj",filter_obj,type(filter_obj)) # filter_obj
# app1.book.auther <
#
# class 'django.db.models.fields.related.ManyToManyField'>
#
# filter_obj
# app1.book.publish <
#
# class 'django.db.models.fields.related.ForeignKey'>
#
# filter_obj
# app1.book.price <
#
# class 'django.db.models.fields.DecimalField'> # 获取当前的参数值,主要是为了吧选中的a标签加一个active的属性
cid = int(self.request.GET.get(filter_str,0)) from django.db.models.fields.related import ManyToManyField
from django.db.models.fields.related import ForeignKey
if isinstance(filter_obj,(ManyToManyField,ForeignKey)):
print(filter_obj.rel.to.objects.all())
# 通过字段对象跨表查询,必须是ManyToManyField或者ForeignKey的字段, # <QuerySet [<auther: 作者1>, <auther: 作者2>, <auther: 作者3>, <auther: 作者4>, <auther: 作者5>]>
# < QuerySet[ < publist: 出版社1 >, < publist: 出版社2 >, < publist: 出版社3 >, < publist: 出版社4 >, < publist: 出版社5 >] >
data_list = filter_obj.rel.to.objects.all()
else:
data_list = self.config.model.objects.all() temp = [] # 这里要加一个全选的a标签,如果点出版社的是全部,则把参数中的出版社的标签全部去掉,如果点的是作者的全部,则把参数中作者的标签全部去掉
all_dict = copy.deepcopy(parms)
if all_dict:
if all_dict.get(filter_str,None):
del all_dict[filter_str] print(parms,"parms",filter_str)
_url = "?{url}".format(url=all_dict.urlencode())
all_label = "<a href='{url}'>全部</a>".format(url = _url)
temp.append(all_label)
# 处理全部的a标签的的代码
# -------------------------------------------------------------------- for obj in data_list:
parms[filter_str] = obj.id
if parms.get("p",None):
del parms["p"]
# 这里做一个处理,点击过滤,把page的参数干掉 _url = "?{url}".format(url = parms.urlencode())
# print(cid,obj.id,"------------------------------") # 这里做一下判断,如果当前的id和现在循环的id一样,则需要给这个a标签加一个属性,用以区分
if int(cid) == obj.id:
a_str = "<a class='active' href='{url}'>{obj}</a>".format(obj=str(obj), url=_url)
else:
a_str = "<a href='{url}'>{obj}</a>".format(obj=str(obj),url = _url)
temp.append(a_str)
link_dict[filter_str] = temp
return link_dict
q_filter_obj = self.get_filter(request)
if q_obj and q_filter_obj:
new_data_list = self.model.objects.all().filter(q_obj).filter(q_filter_obj)
elif q_obj and not q_filter_obj:
new_data_list = self.model.objects.all().filter(q_obj)
elif not q_obj and q_filter_obj:
new_data_list = self.model.objects.all().filter(q_filter_obj)
else:
new_data_list = self.model.objects.all()
def get_filter(self,request):
from django.db.models import Q
q_filter_obj = Q()
q_filter_obj.connector = "and"
for k in self.list_filter:
if request.GET.get(k,None):
temp = (k,request.GET.get(k))
q_filter_obj.children.append(temp)
print(q_filter_obj,"q_filter_obj")
return q_filter_obj
stark组件之过滤操作【模仿Django的admin】的更多相关文章
- stark组件之批量操作【模仿Django的admin】
一.先看下django的admin是如何实现批量操作 首先在配置类中定义一个函数 然后我们为这个函数对象设置一个属性,这个属性主要用来显示在select标签中显示的文本内容 最后把函数对象放到一个ac ...
- stark组件之搜索【模仿Django的admin】
一.先看下django的admin是如何做搜索功能的 配置一个search_fields的列表就可以实现搜索的功能 class testbook(admin.ModelAdmin): # 第一步,定义 ...
- stark组件之注册【模仿Django的admin】
一.先看下django的admin是如何实现注册功能 首先导入admin这个对象和我们的model模块 from django.contrib import admin # Register your ...
- stark组件之分页【模仿Django的admin】
我们的stark组件用的我们的分页组件,没有重新写 下面直接看下分页的代码 class page_helper(): def __init__(self, count, current_page, p ...
- stark组件之启动【模仿Django的admin】
首先需要在settings注册app INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib ...
- stark组件之路由分发【模仿Django的admin】
一.先看下django的admin是如何进行路由分发的 1.先看下django的admin的url路径有哪些 其实很简单,假如有一个书籍表,那么每张表对应四个url,增.删.改.查 查看的url ht ...
- stark组件之pop操作【模仿Django的admin】
一.先看下什么django的admin的pop到底是个什么东西 其实就是这么一个东西, a.在添加页面,在一对多和多对多的项后加了一个+号 b.点击这个加号,会弹出对应的添加 页面,在新的添加 c.添 ...
- crm项目之stark组件前戏(二)
stark组件的设计主要来源于django中admin的功能,在django admin中只需要将模型表进行注册,就可以在页面对该表进行curd的动作,那么django admin是如何做的呢? 在d ...
- 【django之stark组件】
一.需求 仿照django的admin,开发自己的stark组件.实现类似数据库客户端的功能,对数据进行增删改查. 二.实现 1.在settings配置中分别注册这三个app # Applicatio ...
随机推荐
- tomcat7修改tomcat-users.xml文件,但服务器重启后又自动还原了。
tomcat7配置用户管理权限,修改tomcat-users.xml文件 在%tomcat%目录中找到/conf/tomcat-users.xml,修改 <tomcat-users> ...
- CAS无锁技术
前言:关于同步,很多人都知道synchronized,Reentrantlock等加锁技术,这种方式也很好理解,是在线程访问的临界区资源上建立一个阻塞机制,需要线程等待 其它线程释放了锁,它才能运行. ...
- UNITY 多个子MESH与贴图的对应关系
多个贴图时,与子MESH一一对应,如果多了 ...还待研究如何对应
- python的解构
今天学习python看到python的解构,觉得很有用就写下来,防止自己忘了 首先定义个列表 然后我们来解构 字典呢?字典需要两个*号才能解构 这样调用不明显 来个明显点的 上面错误是,你定义了一个形 ...
- RabbitMQ系列教程之六:远程过程调用(RPC)(转载)
RabbitMQ系列教程之六:远程过程调用(RPC) 远程过程调用(Remote Proceddure call[RPC]) (本实例都是使用的Net的客户端,使用C#编写) 在第二个教程中,我们学习 ...
- 分页插件 PageHelper
一步:pom 依赖 二步:controller层 三步:id调用了三个包,org.n3r.idworker的包,这是一体的不用修改,调用即可生成,电商,腾讯都会用这个 , 前三位是年日 四步:serv ...
- FMS Dev Guide学习笔记
翻译一下其中或许对游戏开发有用的一个章节 一.开发交互式的媒体应用程序 1.共享对象(Shared objects) ----关于共享对象 使用共享对象可以同步用户和存储数据.共享对象 ...
- ubuntu16.04获取root权限并用root用户登录
写在全面:如果根据以下教程涉及到只读文件需要更改文件权限才能需修改文件内容,参考我的另一篇博客:https://www.cnblogs.com/masbay/p/10744900.html中的第2条. ...
- 获取镜像tag
# curl -k https://k8s.gcr.io/v2/fluentd-elasticsearch/tags/list|jq .tags % Total % Received % Xferd ...
- 1.3.8、CDH 搭建Hadoop在安装之前(端口---Apache Flume和Apache Solr使用的端口)
Apache Flume和Apache Solr使用的端口 Apache Flume用于与Apache Solr通信的端口可能会有所不同,具体取决于您的配置以及是否使用安全性(例如,SSL).使用Fl ...