stacking过程
图解stacking原理:
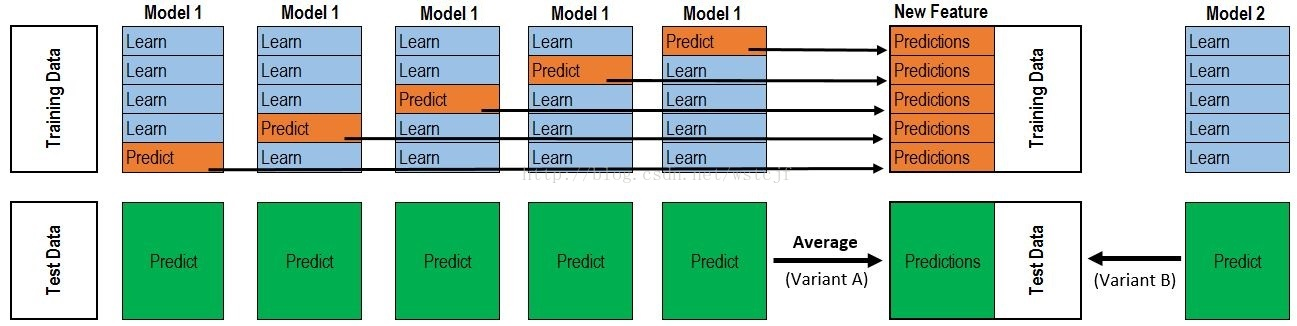
上半部分是用一个基础模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证就是先拿出四折作为training data,另外一折作为testing data。注意:在stacking中此部分数据会用到整个traing set。如:假设我们整个training set包含10000行数据,testing set包含2500行数据,那么每一次交叉验证其实就是对training set进行划分,在每一次的交叉验证中training data将会是8000行,testing data是2000行。
每一次的交叉验证包含两个过程,1. 基于training data训练模型;2. 基于training data训练生成的模型对testing data进行预测。在整个第一次的交叉验证完成之后我们将会得到关于当前testing data的预测值,这将会是一个一维2000行的数据,记为a1。注意!在这部分操作完成后,我们还要对数据集原来的整个testing set进行预测,这个过程会生成2500个预测值,这部分预测值将会作为下一层模型testing data的一部分,记为b1。因为我们进行的是5折交叉验证,所以以上提及的过程将会进行五次,最终会生成针对testing set数据预测的5列2000行的数据a1,a2,a3,a4,a5,对testing set的预测会是5列2500行数据b1,b2,b3,b4,b5。
在完成对Model1的整个步骤之后,我们可以发现a1,a2,a3,a4,a5其实就是对原来整个training set的预测值,将他们拼凑起来,会形成一个10000行一列的矩阵,记为A1。而对于b1,b2,b3,b4,b5这部分数据,我们将各部分相加取平均值,得到一个2500行一列的矩阵,记为B1。
以上就是stacking中一个模型的完整流程,stacking中同一层通常包含多个模型,假设还有Model2: LR,Model3:RF,Model4: GBDT,Model5:SVM,对于这四个模型,我们可以重复以上的步骤,在整个流程结束之后,我们可以得到新的A2,A3,A4,A5,B2,B3,B4,B5矩阵。
在此之后,我们把A1,A2,A3,A4,A5并列合并得到一个10000行五列的矩阵作为training data,B1,B2,B3,B4,B5并列合并得到一个2500行五列的矩阵作为testing data。让下一层的模型,基于他们进一步训练。
如何实现?
1.写代码自己实现
2.如果嫌麻烦可以调用API
code1:
from vecstack import stacking # 输入数据 # 初始化第一层评估器
models = [LinearRegression(),
Ridge(random_state=0)] # 把 stack特征排成一列
S_train, S_test = stacking(models, X_train, y_train, X_test, regression=True, verbose=2) # 如果觉得效果可以在提升,我们可以使用第一层提取的stack特征输入到模型中
code2:
from vecstack import StackingTransformer
estimators = [('lr', LinearRegression()),
('ridge', Ridge(random_state=0))]
stack = StackingTransformer(estimators, regression=True, verbose=2)
stack = stack.fit(X_train, y_train)
S_train = stack.transform(X_train)
S_test = stack.transform(X_test)
# 使用stack特征作为第二层模型的输入数据
stacking过程的更多相关文章
- 弱分类器的进化--Bagging、Boosting、Stacking
一般来说集成学习可以分为三大类: 用于减少方差的bagging 用于减少偏差的boosting 用于提升预测结果的stacking 一.Bagging(1996) 1.随机森林(1996) RF = ...
- 深度学习在CTR预估中的应用
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由鹅厂优文发表于云+社区专栏 一.前言 二.深度学习模型 1. Factorization-machine(FM) FM = LR+ e ...
- 一小部分机器学习算法小结: 优化算法、逻辑回归、支持向量机、决策树、集成算法、Word2Vec等
优化算法 先导知识:泰勒公式 \[ f(x)=\sum_{n=0}^{\infty}\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n \] 一阶泰勒展开: \[ f(x)\approx ...
- c++ primer plus 第6版 部分二 5- 8章
---恢复内容开始--- c++ primer plus 第6版 部分二 5- 章 第五章 计算机除了存储外 还可以对数据进行分析.合并.重组.抽取.修改.推断.合成.以及其他操作 1.for ...
- UVA 103 Stacking Boxes (dp + DAG上的最长路径 + 记忆化搜索)
Stacking Boxes Background Some concepts in Mathematics and Computer Science are simple in one or t ...
- Ensemble Learning: Bootstrap aggregating (Bagging) & Boosting & Stacked generalization (Stacking)
Booststrap aggregating (有些地方译作:引导聚集),也就是通常为大家所熟知的bagging.在维基上被定义为一种提升机器学习算法稳定性和准确性的元算法,常用于统计分类和回归中. ...
- Dream team: Stacking for combining classifiers梦之队:组合分类器
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 集成学习总结 & Stacking方法详解
http://blog.csdn.net/willduan1/article/details/73618677 集成学习主要分为 bagging, boosting 和 stacking方法.本文主要 ...
- 模型融合策略voting、averaging、stacking
原文:https://zhuanlan.zhihu.com/p/25836678 1.voting 对于分类问题,采用多个基础模型,采用投票策略选择投票最多的为最终的分类. 2.averaging 对 ...
随机推荐
- MongoDB之增删改查
MongoDB的默认端口为:27017 show dbs 查看所有的数据库 MySQL和MongoDB的对应关系 MySQL MongoDB DB DB 数据库 table Collection ...
- Android 性能测试之CPU
接上一篇 CPU跟内存一样,存在一些测试子项,如下清单所示 1.空闲状态下的应用CPU消耗情况 2.中等规格状态下的应用CPU消耗情况 3.满规格状态下的应用CPU消耗情况 4.应用CPU峰值情况 C ...
- c# tcp协议发送数据
private void tcp_send(string data)//tcp协议转发数据 { TcpClient tcpClient = new TcpClient(); tcpClient.Con ...
- android和js互相调用
import android.app.Activity; import android.content.Intent; import android.net.Uri; import android.o ...
- 微信小程序之 ----API接口
1. wx.request 接口 可在文件 wxs中操作,连接服务器处理数据 参数 ① url ② data ③ header ④ method ⑤ dataType 回调 ...
- 12.Mysql存储过程和函数
12.存储过程和函数12.1 什么是存储过程和函数存储过程和函数是事先经过编译并存储在数据库中的一段SQL语句的集合,调用存储过程和函数简化应用开发人员的工作,减少数据在数据库和应用服务器之间的传输, ...
- (转)JavaScript的压缩
JavaScript的压缩 (转自)http://blog.csdn.net/ybygjy/article/details/6995435 简述 如果非常着急,这块可以跳过直接从约束条件开始也行. J ...
- XiaoKL学Python(C)__future__
__future__ in Python 1. from __future__ import xxxx 这是为了在低版本的python中使用可能在某个高版本python中成为语言标准的特性,从而 在将 ...
- 文档根元素 "mapper" 必须匹配 DOCTYPE 根 "configuration"
该问题是因为xml的头部写错了,一个是configuration,一个是mapper,不能直接复制. 参考链接:http://blog.csdn.net/testcs_dn/article/detai ...
- 显示实现接口的好处c#比java好的地方
所谓Go语言式的接口,就是不用显示声明类型T实现了接口I,只要类型T的公开方法完全满足接口I的要求,就可以把类型T的对象用在需要接口I的地方.这种做法的学名叫做Structural Typing,有人 ...