洛谷P4180【Beijing2010组队】次小生成树Tree
题目描述:
小C最近学了很多最小生成树的算法,Prim算法、Kurskal算法、消圈算法等等。正当小C洋洋得意之时,小P又来泼小C冷水了。小P说,让小C求出一个无向图的次小生成树,而且这个次小生成树还得是严格次小的,也就是说:如果最小生成树选择的边集是$E_M$,严格次小生成树选择的边集是$E_S$,那么需要满足:($value(e)$表示边e的权值)
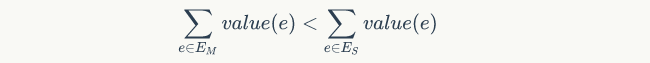
这下小 C 蒙了,他找到了你,希望你帮他解决这个问题。
输入输出格式:
输入格式:
第一行包含两个整数N和M,表示无向图的点数与边数。接下来M行,每行3个数 x y z 表示,点x和点y之间有一条边,边的权值为z。
输出格式:
包含一行,仅一个数,表示严格次小生成树的边权和。(数据保证必定存在严格次小生成树)
输入输出样例:
输入样例:
1 |
5 6 |
输出样例:
1 |
11 |
说明:
数据中无向图无自环
50%的数据$N≤2000,;M≤3000$
80%的数据$N≤50000,;M≤100000$
100%的数据$N≤100000,;M≤300000$, 边权值非负且不超过$10^9$。
SOL:
首先求出最小生成树,然后将最小生成树的边依次断开,换成指定的一条边,
求出这个环中最长的一条边,换掉即可。
Code:
1 |
#include<bits/stdc++.h> |
洛谷P4180【Beijing2010组队】次小生成树Tree的更多相关文章
- 洛谷P4180 [Beijing2010组队]次小生成树Tree(最小生成树,LCT,主席树,倍增LCA,倍增,树链剖分)
洛谷题目传送门 %%%TPLY巨佬和ysner巨佬%%% 他们的题解 思路分析 具体思路都在各位巨佬的题解中.这题做法挺多的,我就不对每个都详细讲了,泛泛而谈吧. 大多数算法都要用kruskal把最小 ...
- 洛谷P4180 [Beijing2010组队]次小生成树Tree
题目描述 小C最近学了很多最小生成树的算法,Prim算法.Kurskal算法.消圈算法等等.正当小C洋洋得意之时,小P又来泼小C冷水了.小P说,让小C求出一个无向图的次小生成树,而且这个次小生成树还得 ...
- BZOJ 1977: [BeiJing2010组队]次小生成树 Tree( MST + 树链剖分 + RMQ )
做一次MST, 枚举不在最小生成树上的每一条边(u,v), 然后加上这条边, 删掉(u,v)上的最大边(或严格次大边), 更新答案. 树链剖分然后ST维护最大值和严格次大值..倍增也是可以的... - ...
- 1977: [BeiJing2010组队]次小生成树 Tree
1977: [BeiJing2010组队]次小生成树 Tree https://lydsy.com/JudgeOnline/problem.php?id=1977 题意: 求严格次小生成树,即边权和不 ...
- 【BZOJ1977】[BeiJing2010组队]次小生成树 Tree 最小生成树+倍增
[BZOJ1977][BeiJing2010组队]次小生成树 Tree Description 小 C 最近学了很多最小生成树的算法,Prim 算法.Kurskal 算法.消圈算法等等. 正当小 C ...
- [BeiJing2010组队]次小生成树 Tree
1977: [BeiJing2010组队]次小生成树 Tree Time Limit: 10 Sec Memory Limit: 512 MBSubmit: 5168 Solved: 1668[S ...
- 【题解】洛谷P4180 [BJWC2010] 严格次小生成树(最小生成树+倍增求LCA)
洛谷P4180:https://www.luogu.org/problemnew/show/P4180 前言 这可以说是本蒟蒻打过最长的代码了 思路 先求出此图中的最小生成树 权值为tot 我们称这棵 ...
- 【洛谷P4180】严格次小生成树
题目大意:给定一个 N 个顶点,M 条边的带权无向图,求该无向图的一个严格次小生成树. 引理:有至少一个严格次小生成树,和最小生成树之间只有一条边的差异. 题解: 通过引理可以想到一个暴力,即:先求出 ...
- 【次小生成树】bzoj1977 [BeiJing2010组队]次小生成树 Tree
Description 小 C 最近学了很多最小生成树的算法,Prim 算法.Kurskal 算法.消圈算法等等. 正当小 C 洋洋得意之时,小 P 又来泼小 C 冷水了.小 P 说,让小 C 求出一 ...
- (luogu4180) [Beijing2010组队]次小生成树Tree
严格次小生成树 首先看看如果不严格我们怎么办. 非严格次小生成树怎么做 由此,我们发现一个结论,求非严格次小生成树,只需要先用kruskal算法求得最小生成树,然后暴力枚举非树边,替换路径最大边即可. ...
随机推荐
- iOS 一个新方法:- (void)makeObjectsPerformSelector:(SEL)aSelector;
NSArray 里面的一个方法, - (void)makeObjectsPerformSelector:(SEL)aSelector: 这是一个类似于执行for循环的方法,可以这样用,当需要删除一个v ...
- JAVA8 函数式接口
一.什么是函数式接口 1.只包含一个抽象方法的接口,称为函数式接口. 2.你可以通过Lambda表达式来创建该接口的对象.(若Lambda表达式抛出一个受检异常,那么该异常需要在目标接口的抽象方法上进 ...
- Spring4.3.25版本使用的积累性总结(不定期更新)
Spring4.3.25版本使用的积累性总结 Spring4.x所有Maven依赖 Spring基于XML配置方式注入bean对象和@Resource注解的使用 详解Spring3.x 升级至 Spr ...
- [思路笔记]WEB安全之漏洞挖掘
记录自己在实际渗透测试以及漏洞挖掘中会用到的思路和方法.不断完善,尽量以系统的方式展现程序化式的漏洞挖掘.由于各种原因,不便公开. 通用策略 1.信息搜集 : 数据挖掘.业务挖掘 数据: 邮箱.手机号 ...
- RDD(六)——分区器
RDD的分区器 Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数.RDD中每条数据经过Shuffle过 ...
- log4j中%5p的含义
因为日志级别分别有error,warn,info,debug,fatal5种,有些是5个字母的,有些是4个字母的,如果直接写%p就会对不齐,%-5p的意思是日志级别输出左对齐,右边以空格填充,%5p的 ...
- 能够伪装为 win 10 的 kali 体验与中文设置
前言 作为习惯性捣鼓各类操作系统,时长也会使用 Kali 系统,之前看到有新的版本发行 传闻这个版本和之前的版本在系统界面和壁纸上都做了更新,还能一键设置 win 10 的系统界面 对此决定下载体验一 ...
- 三十、sersync高级同步工具实时数据同步架构
一.项目介绍 Sersync项目利用inotity与rsync技术实现对服务器数据实时同步的解决方案,其中inotity用于监控sersync所在服务器上的文件变化. Sersync项目的优点: 1. ...
- 吴裕雄--天生自然 JAVA开发学习:文档注释
/*** 这个类绘制一个条形图 * @author runoob * @version 1.2 */ import java.io.*; /** * 这个类演示了文档注释 * @author Ayan ...
- Linux修改主机名称方法
碰到这个问题的时候,是在安装Zookeeper集群的时候,碰到如下问题 java.net.UnknownHostException: XXXX Name or service not knownjav ...