如何使用Logstash
一、什么是Logstash
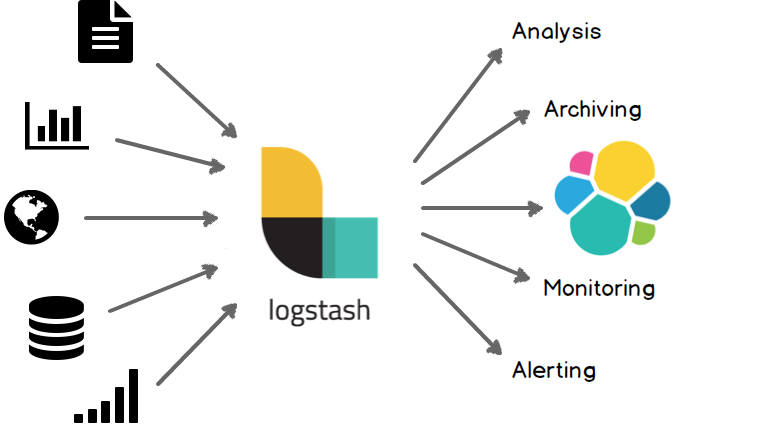
Logstash是一个日志收集器,可以理解为一个管道,或者中间件。
功能是从定义的输入源inputs读取信息,经过filters过滤器处理,输入到定义好的outputs输出源。
输入源可以是stdin、日志文件、数据库等,输出源可以是stdout、elesticsearch、HDFS等。
另外,Logstash不只是一个input | filter | output 的数据流,而是一个 input | decode | filter | encode | output 的数据流!有一个codec插件就是用来 decode、encode 事件的,可以解析我们经常用的json格式,非常的强大,接下来给大家演示一下Logstash的使用,一学就会。
二、如何安装
最简单方式是直接下载安装,另外也可以通过docker安装,
我是直接下载的zip包,解压后如下
三、快速使用
- 直接启动
./bin/logstash -e 'input { stdin { } } output { stdout {} }'

-e 代表可以从命令行读取配置,input { stdin { } } output { stdout {} }'代表从标准stdin读取,从stdout输出,我们输入
chenqionghe
no pain, no gain.
显示如下,logstash把时间等一些信息打印出来了
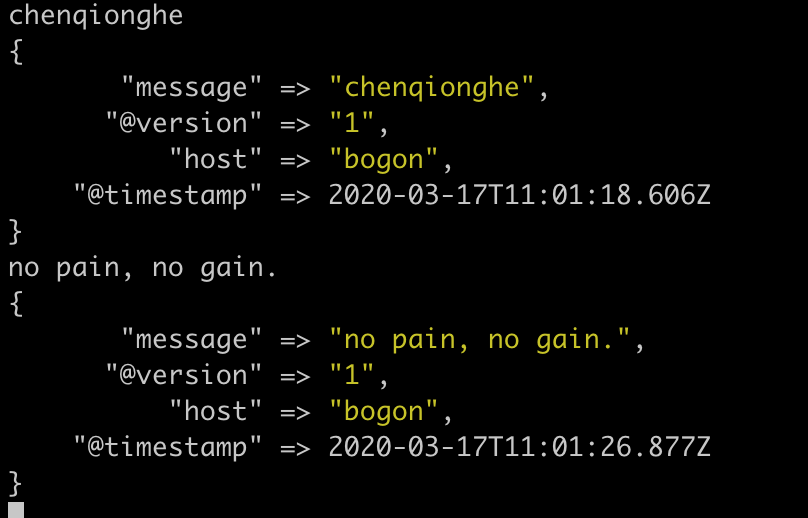
logstash会给事件添加一些额外的信息,最重要的就是 @timestamp,用来标记事件的发生时间。此外,大多数时候还可以见到host、type、tags 等属性
- 使用配置启动
例如我们可以将上面的-e定义成一个chenqionghe.yml
input {
stdin { }
}
output {
stdout { }
}
运行
./bin/logstash -f chenqionghe.yml
更多配置查看 :configuration
四、input输入插件
用来指定数据来源,可以是标准输入、文件、TCP数据、Syslog、Redis等
- 读取文件
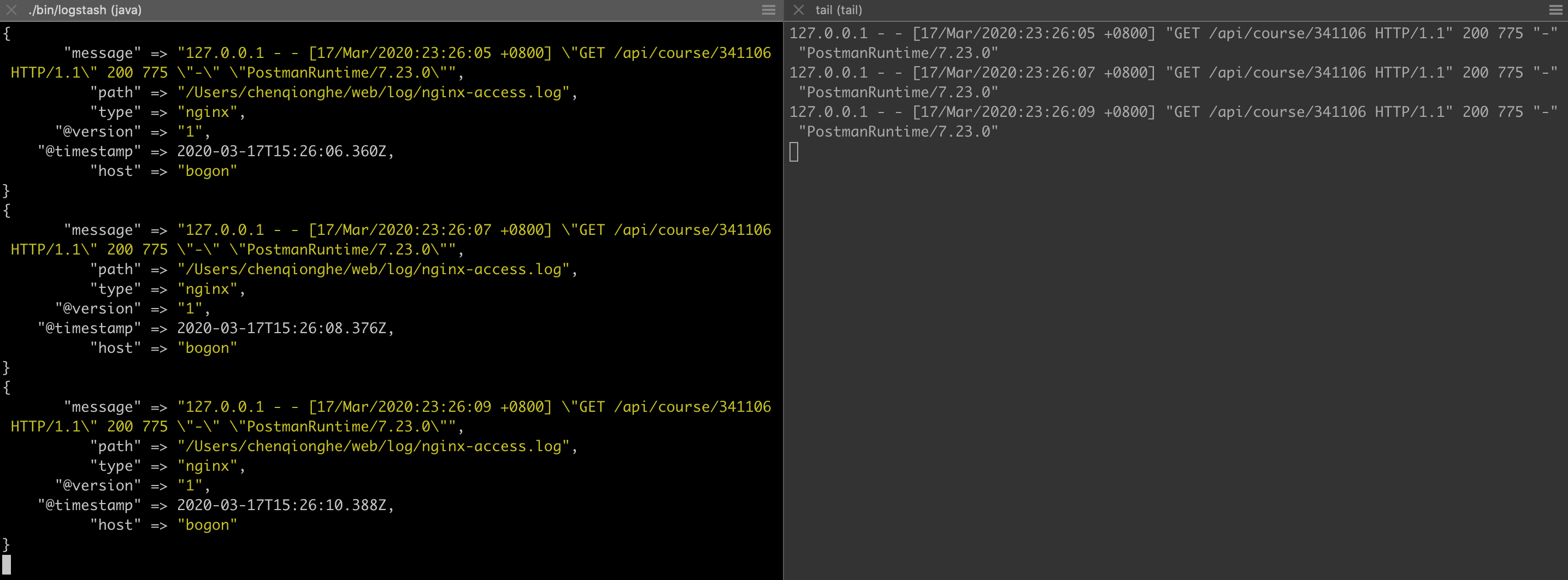
例如,我要收集nginx的访问文件和错误文件,可以这样写
input {
file {
path => ["/Users/chenqionghe/web/log/nginx-access.log","/Users/chenqionghe/web/log/nginx-error.log"]
type => "nginx"
}
}
output {
stdout { codec => rubydebug }
}
output指定了一个rubydebug,简单的理解就是一个调试输出的插件,后面会对output进行说明
结果运行,可以看到收集到了nignx日志
常用配置项
* discover_interval
logstash 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒。
* exclude
不想被监听的文件可以排除出去,这里跟 path 一样支持 glob 展开。
* sincedb_path
如果你不想用默认的 $HOME/.sincedb(Windows 平台上在 C:\Windows\System32\config\systemprofile\.sincedb),可以通过这个配置定义 sincedb 文件到其他位置。
* sincedb_write_interval
logstash 每隔多久写一次 sincedb 文件,默认是 15 秒。
* stat_interval
logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒。
* start_position
logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 "beginning",logstash 进程就从头开始读取,有点类似 cat,但是读到最后一行不会终止,而是继续变成 tail -F。
- 生成测试数据
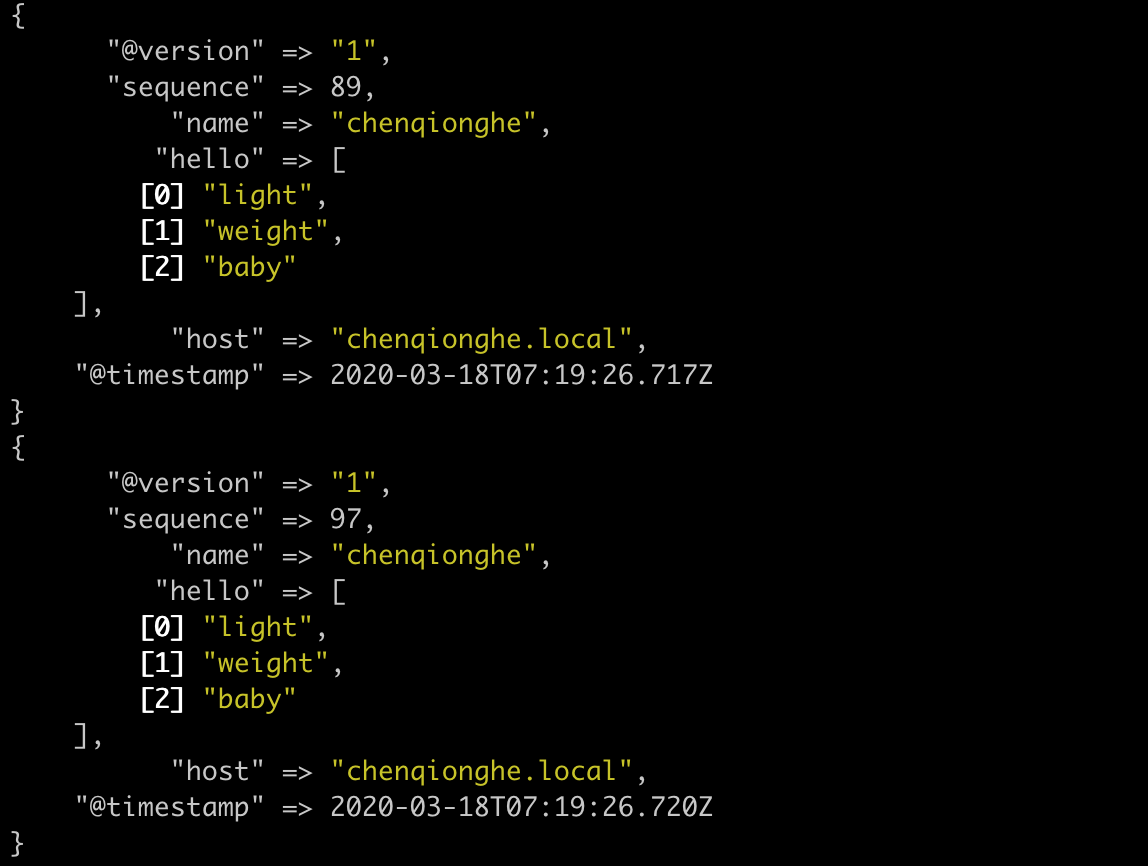
例如可以使用generator来生成测试输入数据,下面的例子相当于循环了100次
input {
generator {
count => 100
message => '{"name":"chenqionghe","hello":["light","weight","baby"]}'
codec => json
}
}
output {
stdout {}
}
运行如下
- 读取TCP
可以使用logstash监听一个tcp端口,我们直接连接这个tcp端口发送数据就可以了
配置如下,监听本机的12345
input {
tcp {
host => "127.0.0.1"
port => "12345"
}
}
output {
stdout{codec => rubydebug}
}
启动后我们用nc命令连接发送一下数据
nc 127.0.0.1 12345
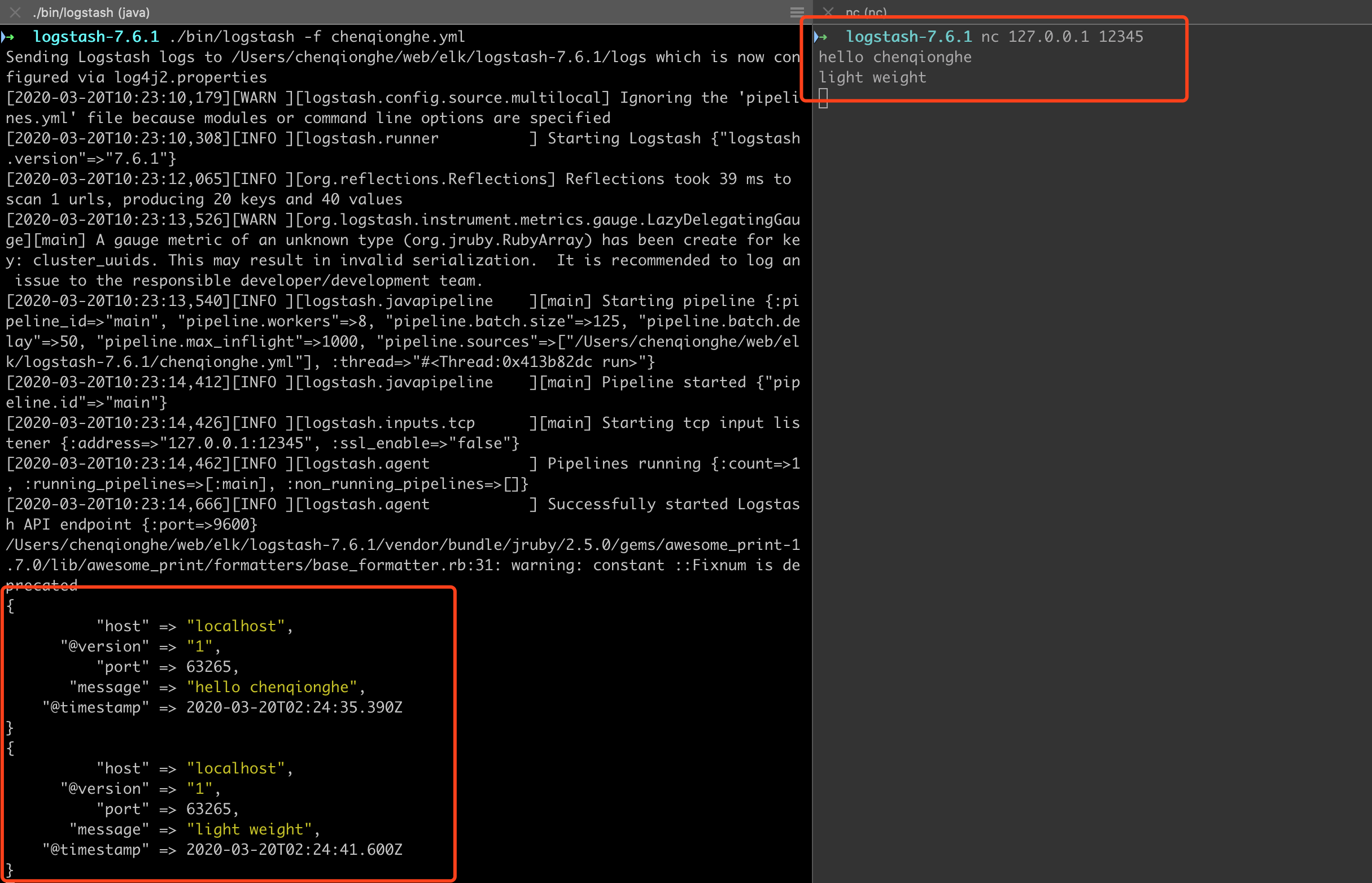
可以看到,已经能接收数据,可以看到logstash的功能相当强大,更多input插件请查看:input-plugins
五、codec编码插件
事实上,我们在上面已经用过 codec 了 ,rubydebug 就是一种 codec,虽然它一般只会用在 stdout 插件中,作为配置测试或者调试的工具。
codec 使得 logstash 可以更好更方便的与其他有自定义数据格式的运维产品共存,比如 graphite、fluent、netflow、collectd,以及使用 msgpack、json、edn 等通用数据格式的其他产品等。
- JSON编码
直接输入预定义好的 JSON 数据,以nginx的配置为例,添加如下配置,让nginx输出json
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"host":"$server_addr",'
'"client":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"domain":"$host",'
'"url":"$uri",'
'"status":"$status"}';
access_log /Users/chenqionghe/web/log/nginx-access.log json;
在logstash中配置
input {
file {
path => "/Users/chenqionghe/web/log/nginx-access.log"
codec => "json"
}
}
output {
stdout { codec => rubydebug }
}
启动请求如下
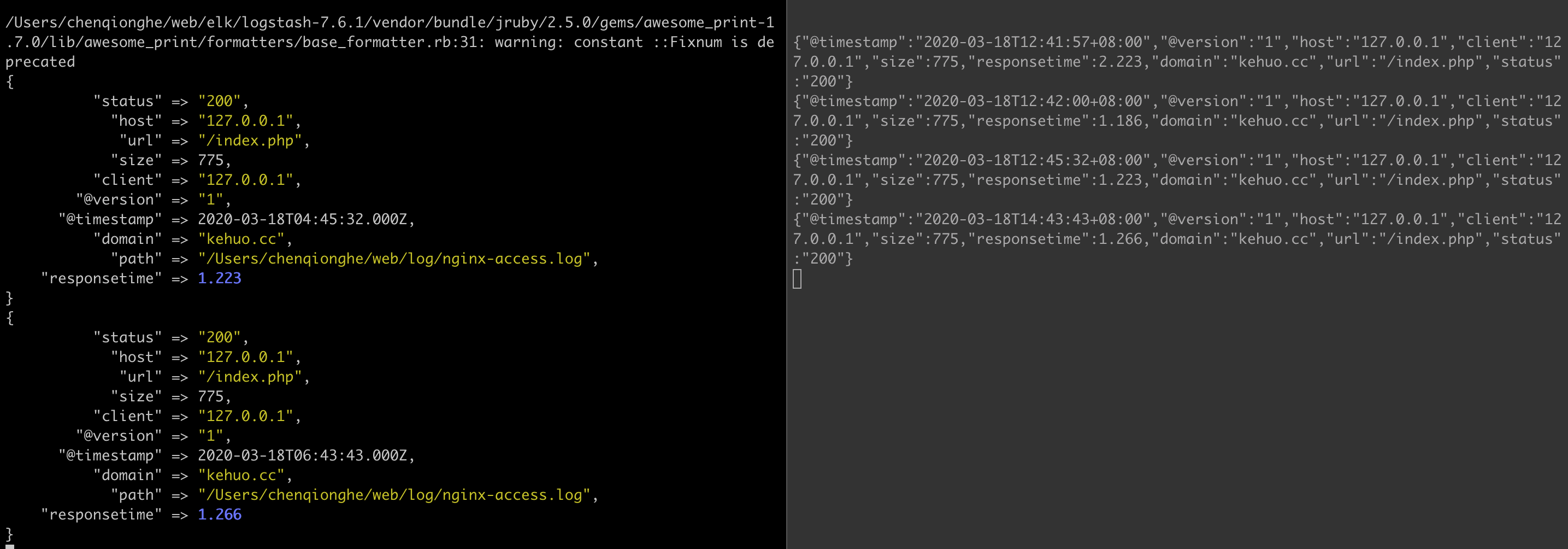
- 合并多行数据
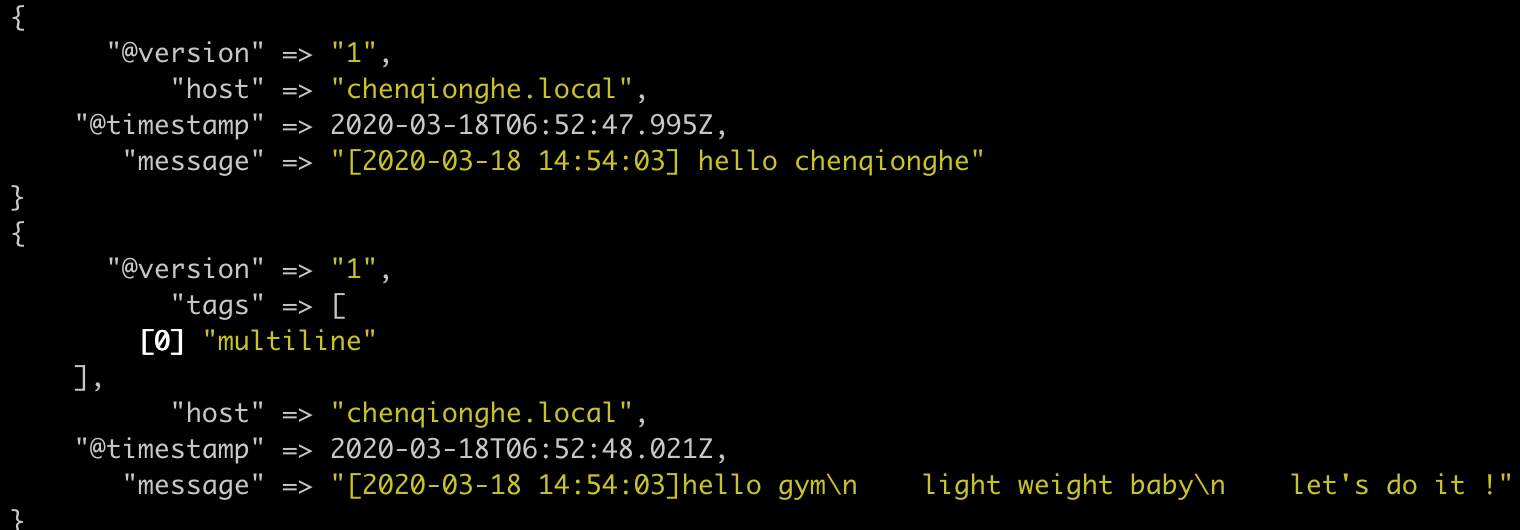
multiline 插件可以收集多行数据,用于用于其他类似的堆栈式信息
示例如下
input {
stdin {
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
}
}
输入
[2020-03-18 14:54:03] hello chenqionghe
[2020-03-18 14:54:03]hello gym
light weight baby
let's do it !
[2020-03-18 14:54:03] finished
效果如下
另外,codec还可以编解码protobuf、fluent、nmap等,可以参考:codec-plugins
六、filter过滤器插件
logstash 威力强大的最重要的就是因为有丰富的过滤器插件。
- Grok 正则捕获
Grok 是 Logstash 最重要的插件,预定义了非常多的正则变量,使用时可以直接通过%引用,另外,还可以在 grok 自定义命名正则表达式,在之后(grok参数或者其他正则表达式里)引用它,示例
input {stdin{}}
filter {
grok {
match => {
"message" => "\s+(?<request_time>\d+(?:\.\d+)?)\s+"
}
}
}
output {stdout{}}
启动后输入
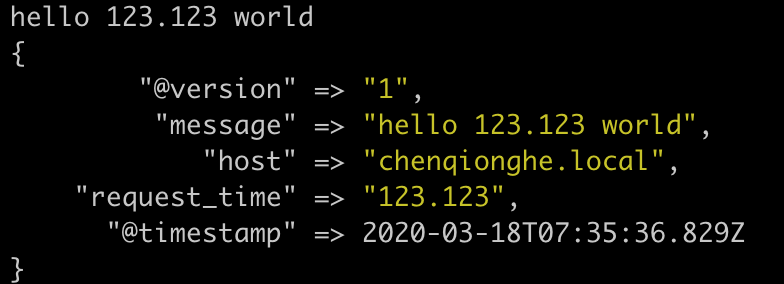
hello 123.123 world
可以,看到配置到了我们自定义的变量request_time
- 时间处理
filters/date 插件可以用来转换你的日志记录中的时间字符串,变成 LogStash::Timestamp 对象,然后转存到 @timestamp 字段里。支持ISO8601、UNIX、UNIX_MS、TAI64N、Joda-Time 等格式
示例
input {stdin{}}
filter{
date{
match => ["message","yyyyMMdd"]
}
}
output {stdout{}}
如下

- 数据修改
filters/mutate 提供了丰富的基础类型数据处理能力,包括类型转换,字符串处理和字段处理等。
转换类型,支持integer、float和string。
filter {
mutate {
convert => ["request_time", "float"]
}
}
- 字符串处理
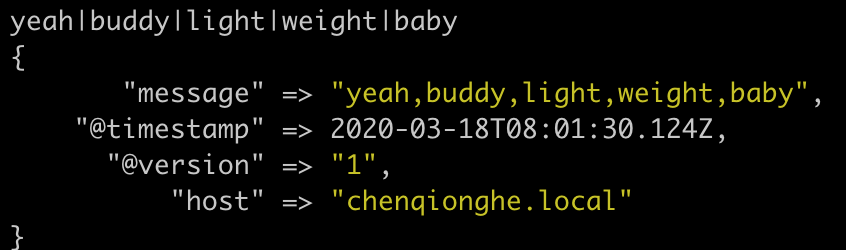
可以对字符串进行split、join、merge、strip、rename、replace等操作
input {stdin{}}
filter {
mutate {
split => ["message", "|"]
}
mutate {
join => ["message", ","]
}
}
output {stdout{}}
先用|分割成数组,再通过,合成字符串
- 拆分事件
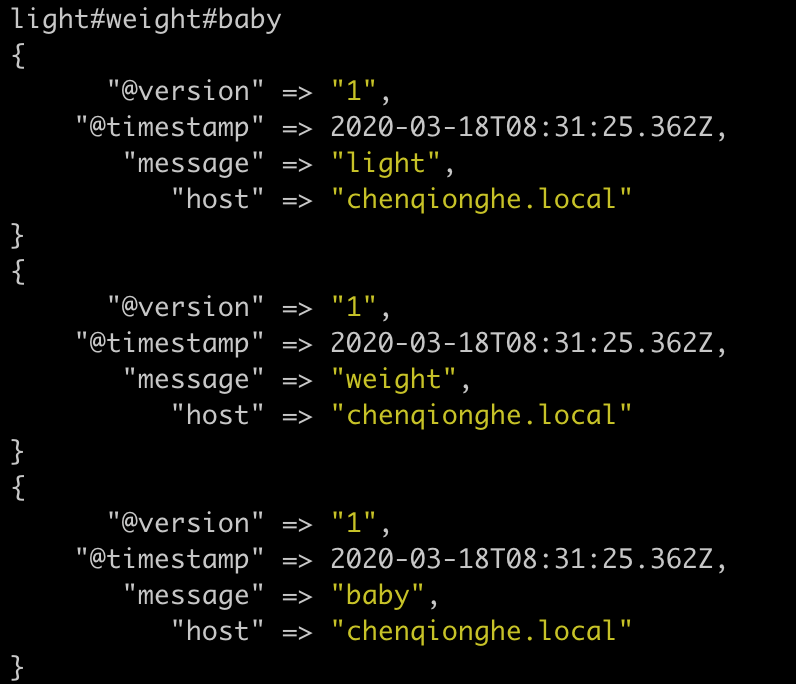
split插件可以把一行数据,拆分成多个事件
input {stdin{}}
filter {
split {
field => "message"
terminator => "#"
}
}
output {stdout{}}
另外,还有JSON编解码、USerAgent匹配归类、Key-Value切分、自定义Ruby处理等插件,更多可以查看:filter-plugins
七、output输出插件
- 标准输出
和 inputs/stdin 插件一样,outputs/stdout 插件是最基础和简单的输出插件,如下
output {
stdout {
codec => rubydebug
}
}
代表输出到stdout,使用rubydebug格式化
- 保存文件
input {stdin{}}
output {
file {
path => "/Users/chenqionghe/web/log/test.log"
}
}
可以看到,已经写入test.log文件

- 输出到ElasticSearch
output {
elasticsearch {
host => "127.0.0.1"
protocol => "http"
index => "logstash-%{type}-%{+YYYY.MM.dd}"
index_type => "%{type}"
workers => 5
template_overwrite => true
}
}
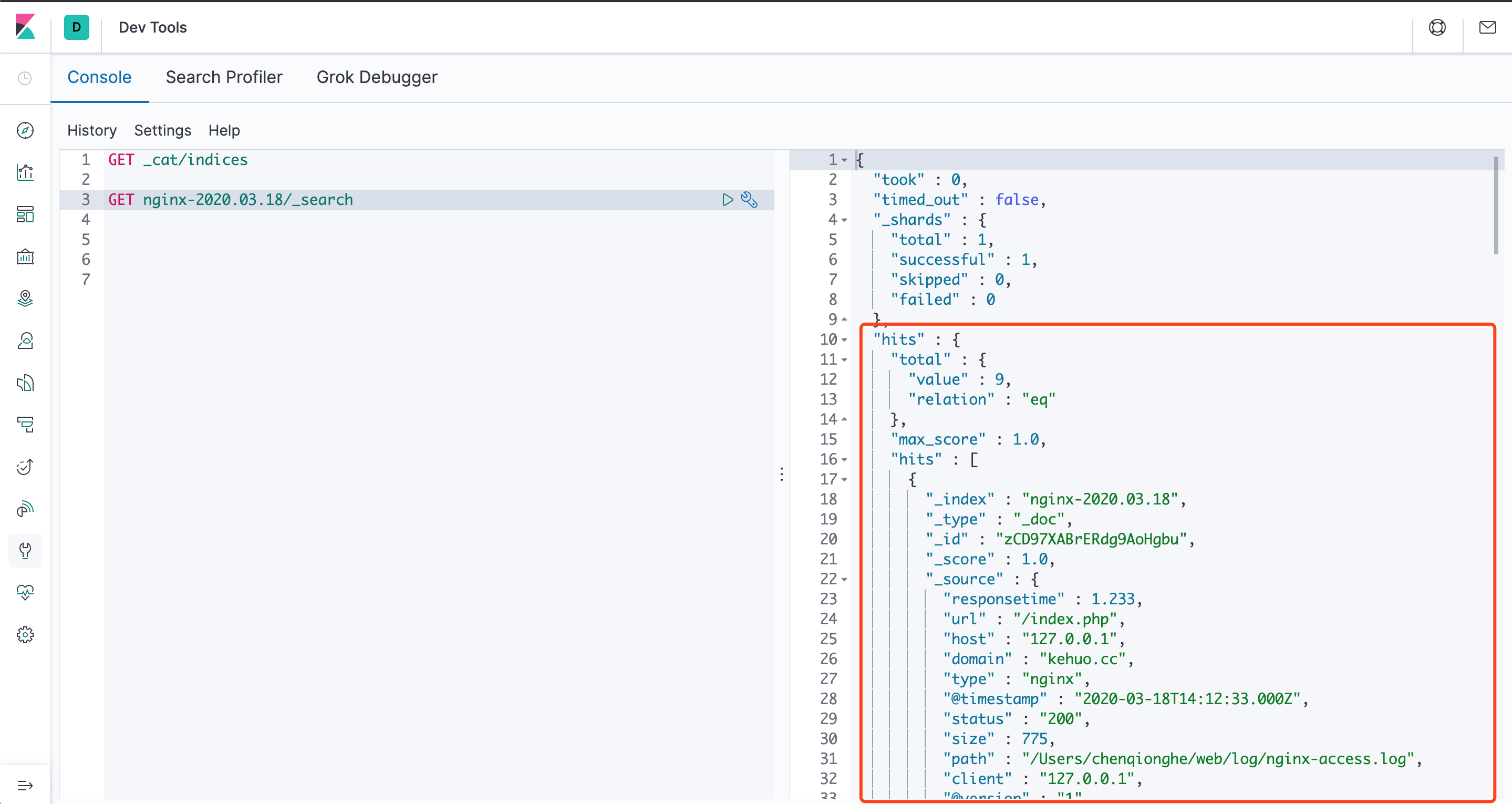
启动后,请求nginx后日志如下
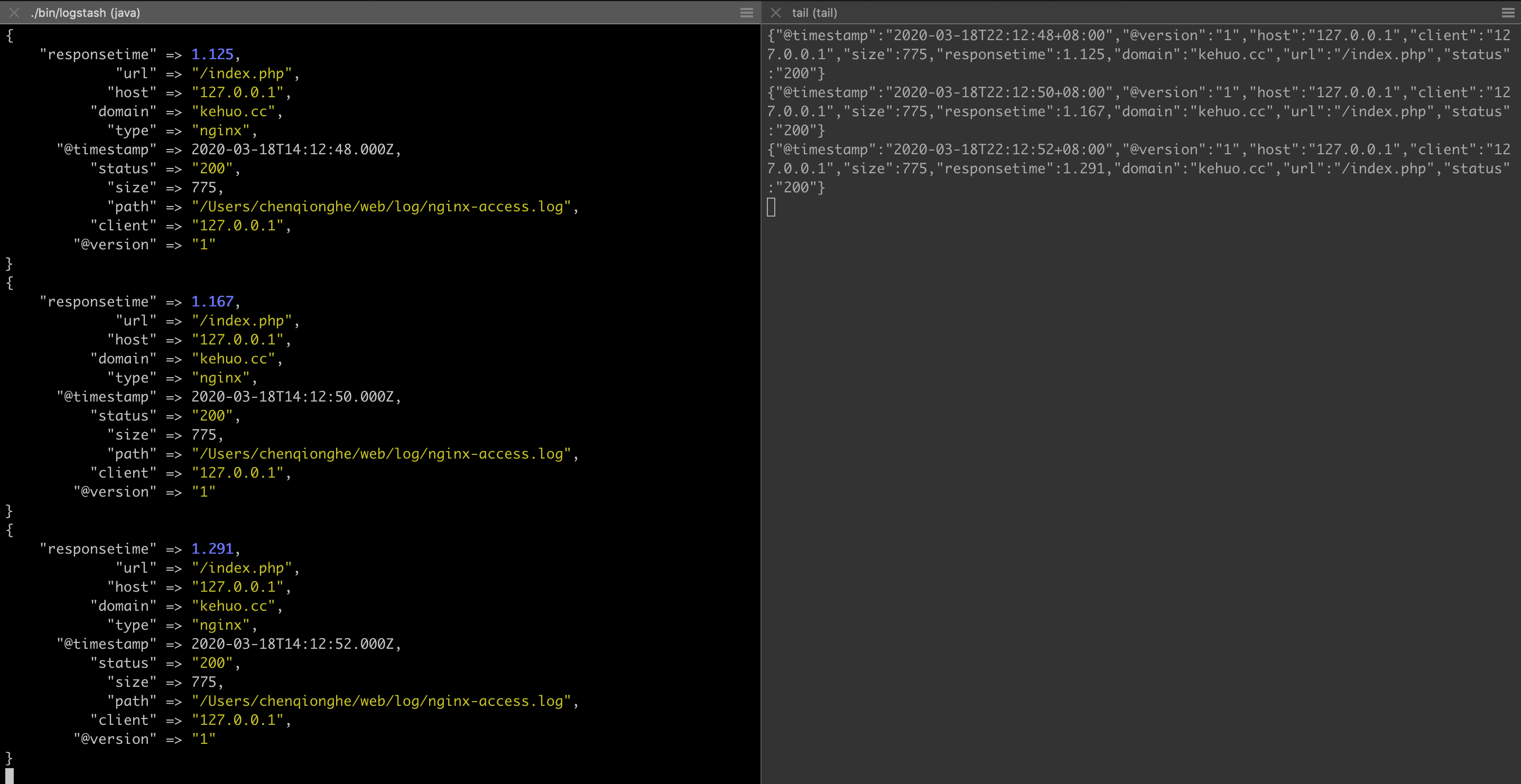
可以看到已经打印出来了,我们去使用kibana控制台查询es,可以看到索引和数据都已经有了
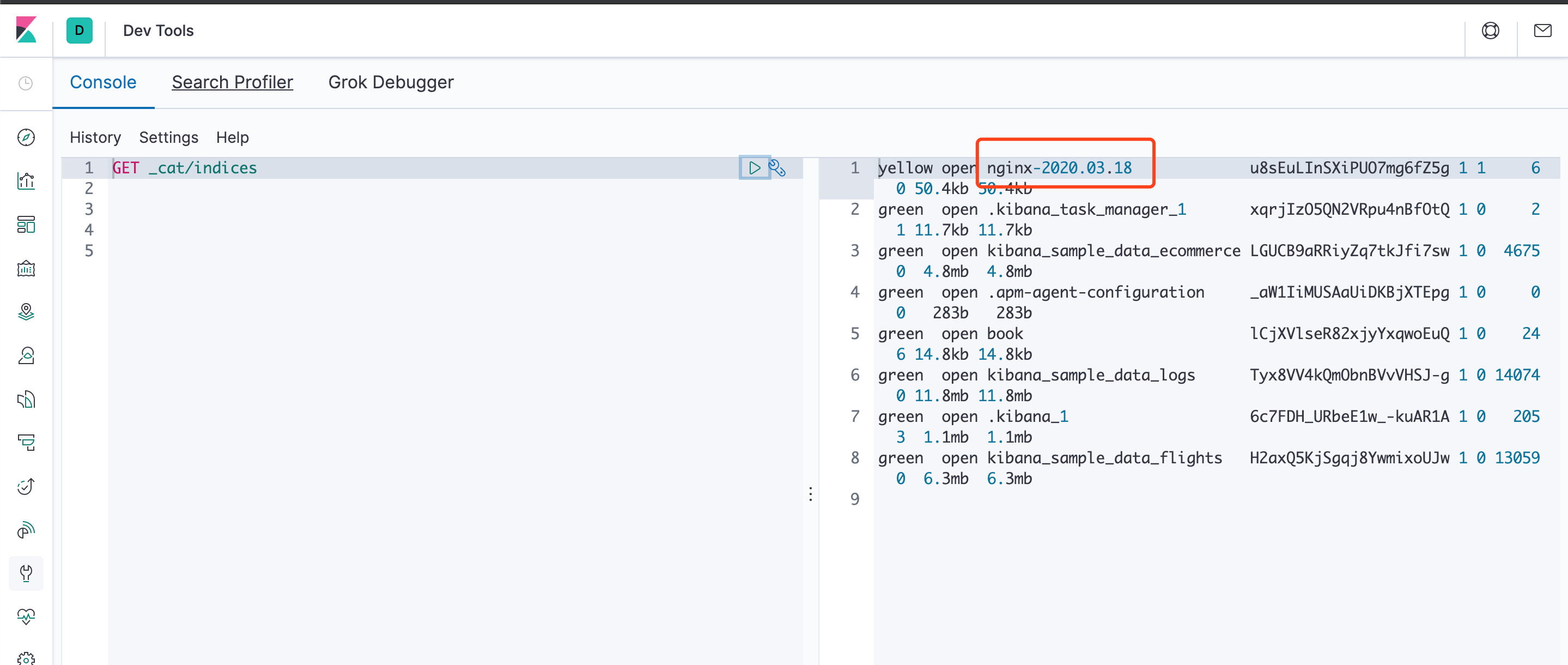
另外,output还可以设置输出到Redis、发送邮件、执行命令等,更多可以查看output-plugins
八、总结
简单地说,logstash最主要的功能是从input获取数据,通过filter处理,再输出到指定的地方。
一般我们收集日志都是在后台运行,建议使用nohup、screen或者supervisor这样的方式启动。
是不是觉得logstash超简单,意不意外,开不开心,yeah buddy! light weight baby!
如何使用Logstash的更多相关文章
- Logstash实践: 分布式系统的日志监控
文/赵杰 2015.11.04 1. 前言 服务端日志你有多重视? 我们没有日志 有日志,但基本不去控制需要输出的内容 经常微调日志,只输出我们想看和有用的 经常监控日志,一方面帮助日志微调,一方面及 ...
- logstash file输入,无输出原因与解决办法
1.现象 很多同学在用logstash input 为file的时候,经常会出现如下问题:配置文件无误,logstash有时一直停留在等待输入的界面 2.解释 logstash作为日志分析的管道,在实 ...
- logstash服务启动脚本
logstash服务启动脚本 最近在弄ELK,发现logstash没有sysv类型的服务启动脚本,于是按照网上一个老外提供的模板自己进行修改 #添加用户 useradd logstash -M -s ...
- Logstash时区、时间转换,message重组
适用场景 获取日志本身时间 日志时间转Unix时间 重组message 示例日志: hellow@,@world@,@2011-11-01 18:46:43 logstash 配置文件: input{ ...
- logstash日志分析的配置和使用
logstash是一个数据分析软件,主要目的是分析log日志.整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是v ...
- logstash+elasticsearch+kibana管理日志(安装)
logstash1.先安装jdk2.wget https://download.elastic.co/logstash/logstash/logstash-2.4.0.tar.gz tar -xzvf ...
- 使用Logstash进行日志分析
LogStash主要用于数据收集和分析方面,配合Elasticsearch,Kibana用起来很方便,安装教程google出来很多. 推荐阅读 Elasticsearch 权威指南 精通 Elasti ...
- LogStash filter介绍(九)
LogStash plugins-filters-grok介绍 官方文档:https://www.elastic.co/guide/en/logstash/current/plugins-filter ...
- kafka(logstash) + elasticsearch 构建日志分析处理系统
第一版:logstash + es 第二版:kafka 替换 logstash的方案
- 海量日志分析方案--logstash+kibnana+kafka
下图为唯品会在qcon上面公开的日志处理平台架构图.听后觉得有些意思,好像也可以很容易的copy一个,就动手尝试了一下. 目前只对flume===>kafka===>elacsticSea ...
随机推荐
- 发现个很有意思的angularjs +grunt 复习项目
最近作运维工作 docker 接触到一个开源webui dockerui 原项目地址 https://github.com/crosbymichael/dockerui 用angular框架实现,项目 ...
- eclipse 设置字体与自动提示
1.设置字体与字体大小 至此,字体与大小设置完毕. 2.设置自动提示 在输入框中输入 1-9 a-z A-Z .点击“Apply”保存. 开启JavaScript 自动提示 灰色未激活,先点击复选框激 ...
- Docker的网络类型
四种网络类型: None:不为容器配置任何网络功能,--net=noneContainer:与另一个运行中的容器共享Network Namespace,--net=container:containe ...
- tf.estimator
estimator同keras是tensorflow的高级API.在tensorflow1.13以上,estimator已经作为一个单独的package从tensorflow分离出来了.estimat ...
- 实战:CentOS 7.2 / Zabbix3.4安装graphtrees
众所周知的 Zabbix图形显示问题,决定使用graphtrees 插件. 环境:CentOS7.2 + Zabbix 3.4 1)首先切换到root用户以获得足够的权限将资源下载到 /usr/sha ...
- Spring中@Resorce和@Autowired的区别
@Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入,而@Resource默认按 byName自动注入罢了.@Resource有两个属性是比较重要的,分 ...
- 语言发展与python
编程语言的发展史(机械语言.汇编语言.高级语言) 机械语言:直接使用二进制与计算机沟通,直接操作硬件,执行效率高,开发效率低. 汇编语言:用简单的英文代替二进制,直接操作硬件,执行效率较机械语言低,开 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- IPC thread写法太晦涩
主要用到TLS,首次进入gHaveTLS为false,锁保护说明此函数很多其他函数在调用.通过if (pthread_key_create(&gTLS, threadDestructor) ! ...
- SpringBoot入门系列(一)如何快速创建SpringBoot项目
这段时间也没什么事情,所以就重新学习整理了Spring Boot的相关内容.今天开始整理更新Spring Boot学习笔记,感兴趣的朋友可以关注我的博客:https://www.cnblogs.com ...