云计算课程实验之安装Hadoop及配置伪分布式模式的Hadoop
一.实验目的
1. 掌握Linux虚拟机的安装方法。
2. 掌握Hadoop的伪分布式安装方法。
二.实验内容
(一)Linux基本操作命令
Linux常用基本命令包括:
ls,cd,mkdir,rm,man,cat,ssh,yum,vim,vi等。
(二)安装JDK
Hadoop是Java实现的,运行在Java虚拟机上,安装JDK并设置JAVA环境变量。
(三)配置各节点间无密码验证
Hadoop集群的启动需要通过SSH启动各从节点,需要配置各节点之间SSH无密码验证。
(四)配置和启动Hadoop分布式集群
Hadoop有三种配置:单击模式、伪分布式模式(单台节点模拟分布式)和分布式模式,本实验是配置伪分布式模式的Hadoop。
三.实验环境
VMWare15 Pro、Ubuntu16.04、Hadoop3.2.1。
四.实验步骤和完成情况
1. VMware 15安装Ubuntu 16.04并配置环境
https://www.cnblogs.com/caoer/p/12669183.html
2. 创建hadoop用户
1)创建hadoop用户,并使用/bin/bash作为shell: sudo useradd -m hadoop -s /bin/bash
2) 为hadoop用户设置密码,之后需要连续输入两次密码: sudo passwd hadoop
3) 为hadoop用户增加管理员权限:sudo adduser hadoop sudo
4) 切换当前用户为用户hadoop: su – hadoop
5) 更新hadoop用户的apt: sudo apt-get update
3. JDK安装和Java环境变量配置
(1)安装 JDK 1.7
hadoop用户登陆,下载JDK安装包, 个人电脑系统选择对应版本,我选的是jzxvf jdk-7u80-linux-x64.tar.gz,输入命令:
$ mkdir /usr/lib/jvm #创建jvm文件夹
$ sudo tar zxvf jdk-7u80-linux-x64.tar.gz -C /usr/lib/jvm #/ 解压到/usr/lib/jvm目录下
$ cd /usr/lib/jvm #进入该目录
$ mv jdk1.7.0_80 java #重命名为java
$ vi ~/.bashrc #给JDK配置环境变量
其中如果权限不够,无法在相关目录下创建jvm文件夹,那么可以使用 $ sudo -i 语句进入root账户来创建文件夹。
(2)Java环境变量配置
root用户登陆,命令行中执行命令”vi /etc/profile”,按I并加入以下内容,配置环境变量(注意/etc/profile这个文件很重要,后面Hadoop的配置还会用到)。
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存并退出,执行以下命令使配置生效
$ source ~/.bashrc
$ java -version #检测是否安装成功,查看java版本
4. 配置所有节点之间SSH无密码验证
以节点A和B两个节点为例,节点A要实现无密码公钥认证连接到节点B上时,节点A是客户端,节点B是服务端,需要在客户端A上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到服务端B上。当客户端A通过ssh连接服务端B时,服务端B就会生成一个随机数并用客户端A的公钥对随机数进行加密,并发送给客户端A。客户端A收到加密数之后再用私钥进行解密,并将解密数回传给B,B确认解密数无误之后就允许A进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程是将客户端A公钥复制到B上。
因此如果要实现所有节点之间无密码公钥认证,则需要将所有节点的公钥都复制到所有节点上。
(1)安装ssh: sudo apt-get install openssh-server
登录ssh:ssh localhost
退出登录的ssh localhost:exit
(2)进入ssh目录:cd ~/.ssh/
(a)节点用hadoop用户登陆,并执行以下命令,生成rsa密钥对:
ssh-keygen -t rsa (回车后敲击三次回车)
这将在/home/hadoop/.ssh/目录下生成一个私钥id_rsa和一个公钥id_rsa.pub。

(c)加入授权:cat ./id_rsa.pub >> ./authorized_keys
这样配置过后SSH无密码登陆,可以通过命令“ssh localhost”来验证。
5. Hadoop集群配置
使用hadoop用户登陆,下载hadoop-3.2.1.tar.gz,将其解压到/usr/local/hadoop目录下: sudo tar -zxvf hadoop-2.6.0.tar.gz -C /usr/local,进入目录:cd /usr/local,重命名为hadoop: sudo mv hadoop-3.2.1 hadoop,修改文件权限:sudo chown -R hadoop ./hadoop。
给hadoop配置环境变量:
(1)打开bashrc文件:vi ~/.bashrc
(2)加入以下代码:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(3)保存更改并生效:source ~/.bashrc。
$hadoop version 查看hadoop是否安装成功。
6. Hadoop集群启动
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
a) 首先将jdk1.8的路径添(export JAVA_HOME=/usr/lib/jvm/java )加到hadoop-env.sh文件。
$ cd /usr/local/hadoop/etc/hadoop/
$ vim hadoop-env.sh
b) 修改core-site.xml:vim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
c) 修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
d) 配置完成后,执行 NameNode 的格式化
$ cd /usr/local/hadoop/
$ ./bin/hdfs namenode -format
e) 启动namenode和datanode进程,并查看启动结果
$ ./sbin/start-dfs.sh
$ jps

f) 成功启动后,可以访问 Web 界面 http://localhost:9870 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
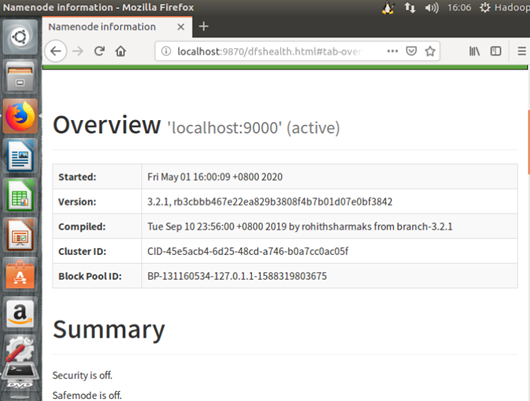
至此Hadoop安装就结束啦,以上为个人大数据学习成长历程~
云计算课程实验之安装Hadoop及配置伪分布式模式的Hadoop的更多相关文章
- 使用docker搭建hadoop环境,并配置伪分布式模式
docker 1.下载docker镜像 docker pull registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop:latest 注:此镜像为阿里云个人上传镜 ...
- 06_Hadoop配置伪分布式模式详解
查看IP地址,设为手动模式: 配置hadoop用户sudo权限 su切换到root身份,配置vim /etc/sudoers文件,加入 hadoop ALL=(root)NOPASSWD:ALL ...
- cdh版本的hadoop安装及配置(伪分布式模式) MapReduce配置 yarn配置
安装hadoop需要jdk依赖,我这里是用jdk8 jdk版本:jdk1.8.0_151 hadoop版本:hadoop-2.5.0-cdh5.3.6 hadoop下载地址:链接:https://pa ...
- 【Hadoop】配置全分布式模式
分布式原理 配置 详细过程 假设有三台虚拟机,1台master主机namenode,2台slave奴隶机datanode 所有机器都要配好jdk.Java环境变量.hadoop_env.sh里java ...
- hadoop 2.4 伪分布式模式
1.core-site.xml 在<configuration></configuration>中插入 <property> <name>fs.defa ...
- Hadoop Single Node Setup(hadoop本地模式和伪分布式模式安装-官方文档翻译 2.7.3)
Purpose(目标) This document describes how to set up and configure a single-node Hadoop installation so ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
- Hadoop安装教程_单机/伪分布式配置
环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS).如果用的是 Ubuntu 系统,请查看相应的 Ubuntu安装Hadoo ...
随机推荐
- ActiveMQ 笔记(一)概述与安装
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.消息中间件的产生背景 1.前言:考虑消息中间件的使用场景? 在何种场景下需要使用消息中间件 为什么要 ...
- Java实现 蓝桥杯 算法训练 多阶乘计算
试题 算法训练 多阶乘计算 问题描述 我们知道,阶乘n!表示n*(n-1)(n-2)-21, 类似的,可以定义多阶乘计算,例如:5!!=531,依次可以有n!..!(k个'!',可以简单表示为n(k) ...
- Java实现 LeetCode 146 LRU缓存机制
146. LRU缓存机制 运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制.它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - ...
- java实现BellmanFord算法
1 问题描述 何为BellmanFord算法? BellmanFord算法功能:给定一个加权连通图,选取一个顶点,称为起点,求取起点到其它所有顶点之间的最短距离,其显著特点是可以求取含负权图的单源最短 ...
- java实现顺时针螺旋填入
从键盘输入一个整数(1~20) 则以该数字为矩阵的大小,把 1,2,3-n*n 的数字按照顺时针螺旋的形式填入其中.例如: 输入数字 2,则程序输出: 1 2 4 3 输入数字 3,则程序输出: 1 ...
- java实现第九届蓝桥杯三角形面积
三角形面积 小明最近在玩一款游戏.对游戏中的防御力很感兴趣. 我们认为直接影响防御的参数为"防御性能",记作d,而面板上有两个防御值A和B,与d成对数关系,A=2^d,B=3^d( ...
- Spring Data Jpa Specification 调用Oracle 函数/方法
开发框架用的Jpa,数据库是 Oracle. 在开发中难免会遇到需要数据库字段是字符串格式,但是又需要对其进行范围查询(数据库设计问题,后续应避免).那么问题来了, Jpa Specification ...
- vue的第一个commit分析
为什么写这篇vue的分析文章? 对于天资愚钝的前端(我)来说,阅读源码是件不容易的事情,毕竟有时候看源码分析的文章都看不懂.每次看到大佬们用了1-2年的vue就能掌握原理,甚至精通源码,再看看自己用了 ...
- iOS-UIViewController创建的几种方法和UIWindow的介绍
在上一篇笔记中<iOS-程序启动原理和UIApplication>,http://blog.csdn.net/yang198907/article/details/49735531 在程序 ...
- 时间序列神器之争:prophet VS lstm
一.需求背景 我们福禄网络致力于为广大用户提供智能化充值服务,包括各类通信充值卡(比如移动.联通.电信的话费及流量充值).游戏类充值卡(比如王者荣耀.吃鸡类点券.AppleStore充值.Q币.斗鱼币 ...