python爬虫(九) requests库之post请求
1、方法:
response=requests.post("https://www.baidu.com/s",data=data)
2、拉勾网职位信息获取
因为拉勾网设置了反爬虫机制,在拉勾网中,一些页面的信息获取方法是post,所以就用到了post方法

在拉勾网中,我们搜索与python相关的职业,如果我们爬取这一页的信息,是没有职业的信息的,因为职业的信息在另外的jsp页面上,所以我们需要在这个界面上爬取到职业的信息,选择一个城市+学生身份
同样,在页面右击,选择查看元素,找到网络,刷新,选择跟职位相关的
然后右侧的网址为url:
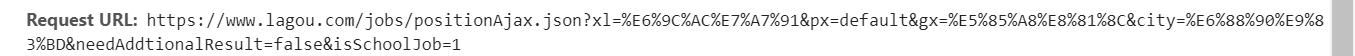
这个页面上面的网址为urls:

可以看到他的获取方法是post,所以我们要获取职位的信息,需要post函数
这时我们需要用到data参数
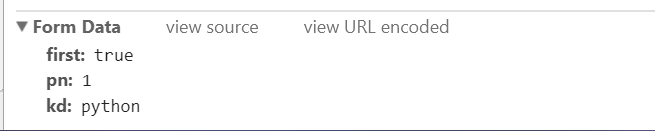
以及请求头:


代码如下:
import requests url='https://www.lagou.com/jobs/positionAjax.json?xl=%E6%9C%AC%E7%A7%91&px=default&gx=%E5%85%A8%E8%81%8C&city=%E6%88%90%E9%83%BD&needAddtionalResult=false&isSchoolJob=1'
data ={
'first':"true",
'pn':1,
'kd':"python"
}
headers={
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
'Referer':"https://www.lagou.com/jobs/list_python/p-city_252?px=default&gx=%E5%85%A8%E8%81%8C&gj=&xl=%E6%9C%AC%E7%A7%91&isSchoolJob=1",
'Accept':'application/json, text/javascript, */*; q=0.01'
}
urls='https://www.lagou.com/jobs/list_python/p-city_252?px=default&gx=%E5%85%A8%E8%81%8C&gj=&xl=%E6%9C%AC%E7%A7%91&isSchoolJob=1#filterBox'
s = requests.Session()
s.get(urls, headers=headers, timeout=3)
cookie = s.cookies
response = s.post('https://www.lagou.com/jobs/positionAjax.json?xl=%E6%9C%AC%E7%A7%91&px=default&gx=%E5%85%A8%E8%81%8C&city=%E6%88%90%E9%83%BD&needAddtionalResult=false&isSchoolJob=1',data=data,headers=headers, cookies=cookie,timeout=5) print(response.text)
with open('py.html', 'w') as file:
file.write(response.text)
中间出现错误:您操作太频繁,请稍后再访问,解决方法参考网址:http://www.freesion.com/article/140098505/
python爬虫(九) requests库之post请求的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用reque ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- 【Python爬虫】Requests库的基本使用
Requests库的基本使用 阅读目录 基本的GET请求 带参数的GET请求 解析Json 获取二进制数据 添加headers 基本的POST请求 response属性 文件上传 获取cookie 会 ...
- python爬虫(1)requests库
在pycharm中安装requests库的一种方法 首先找到设置 搜索然后安装,蓝色代表已经安装 requests库中的get请求 与HTTP协议相对应,requests库也有七种请求方式. 获取ur ...
- python爬虫之requests库介绍(二)
一.requests基于cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们 ...
- Python爬虫之Requests库的基本使用
import requests response = requests.get('http://www.baidu.com/') print(type(response)) print(respons ...
- Python爬虫系列-Requests库详解
Requests基于urllib,比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 实例引入 import requests response = requests.get( ...
- python 爬虫 基于requests模块的get请求
需求:爬取搜狗首页的页面数据 import requests # 1.指定url url = 'https://www.sogou.com/' # 2.发起get请求:get方法会返回请求成功的响应对 ...
随机推荐
- Delphi XE FireDac 连接池
在开发Datasnap三层中,使用FireDac 连接 MSSQL数据库. 实现过程如下: 1.在ServerMethods 单元中放入 FDManager.FDPhysMSSQLDriverLin ...
- 设置textarea不可拉伸
默认情况下,我们将鼠标移动到textarea的右下角时发现文本域是可以通过拖动的方式改变其大小的,这会影响我们原本的页面布局.若想设置其不可拖动,可为其添加如下属性: style="resi ...
- Scrapy - response.css()
选择文本 response.css('span::text') 选择href response.css('a::attr(href)')
- rar文件简单分析
1.rar文件也是由许多特定的块组成 注1:CRC为CRC32的低2个字节(MARK_HEAD的CRC 为固定的0x5261,非计算出来的值) 注2: HEAD_TYPE=0x72 标记块 HEAD_ ...
- 攻防世界 xff_referer
xff_referer [原理] X-Forwarded-For:简称XFF头,它代表客户端,也就是HTTP的请求端真实的IP,只有在通过了HTTP 代理或者负载均衡服务器时才会添加该项 HTTP R ...
- 用vscode写c/c++
用vscode写c/c++ 1. 安装wsl windows下安装linux(ubuntu) 2. 打开设置 3. 输入run code 随便找一个地方粘贴,会出现一大段代码 4. 把c对应的代码修改 ...
- MAC平台基于Python的Appium环境搭建
前言 最近笔者要为python+appium课程做准备,mac在2019年重新安装了一次系统,这次重新在mac下搭建appium环境,刚好顺带写个文稿给大家分享分享搭建过程. 一.环境和所需软件概述 ...
- jdk 9 10 11 12 13 新特性
jdk 9 新特性 1.集合加强 jdk9 为所有集合(List/Set/Map)都增加了 of 和 copyOf 方法,用来创建不可变集合,即一旦创建就无法再执行添加.删除.替换.排序等操作,否则将 ...
- MySQL常用系统表大全
MySQL5.7 默认的模式有:information_schema, 具有 61个表: m ysqL, 具有31个表: performance_schema,具有87个表; sys, 具有1个表, ...
- SQL 查询每组的第一条记录
CREATE TABLE [dbo].[test1]( [program_id] [int] NULL, [person_id] [int] NULL ) ON [PRIMARY] /*查询每组分组中 ...