[python每日一练]--0012:敏感词过滤 type2
题目链接:https://github.com/Show-Me-the-Code/show-me-the-code
代码github链接:https://github.com/wjsaya/python_spider_learn/tree/master/python_daily
个人博客地址:https://wjsaya.github.io
第 0012 题: 敏感词文本文件 filtered_words.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 替换,例如当用户输入「北京是个好城市」,则变成「*是个好城市」。
思路:
- 从文件解析敏感词、从终端获取用户输入。
- 根据敏感词对用户输入进行过滤。这里过滤需要考虑到输入内容不止一个需要过滤的词,所以稍微麻烦点:
- 读取所有的屏蔽词,放进一个列表
- 获取用户输入
- 遍历屏蔽词列表,用屏蔽词检索用户输入
- 如果有屏蔽词,将其替换为*
- 如果没有,不进行操作
- 返回处理后的用户输入
- 用下一个屏蔽词对处理后的用户输入进行上述操作
- 所有屏蔽词遍历完毕,输出过滤后字符串
敏感词列表(filtered_words.txt)
|
|
代码:
|
|
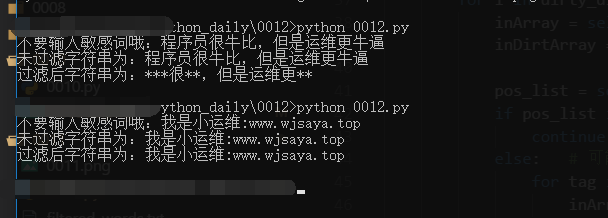
效果图:
[python每日一练]--0012:敏感词过滤 type2的更多相关文章
- DFA和trie特里实现敏感词过滤(python和c语言)
今天的项目是与完成python开展,需要使用做关键词检查,筛选分类,使用前c语言做这种事情.有了线索,非常高效,内存小了,检查快. 到达python在,第一个想法是pip基于外观的c语言python特 ...
- 8.2 前端检索的敏感词过滤的Python实现(针对元搜索)
对于前端的搜索内容进行控制,比如敏感词过滤,同样使用socket,这里使用Python语言做一个demo.这里不得不感叹一句,socket真是太神奇了,可以跨语言把功能封装,为前端提供服务. 下面就是 ...
- Python 每日一练(4)
引言 今天继续是python每日一练的几个专题,主要涵盖简单的敏感词识别以及图片爬虫 敏感词识别 这个敏感词的识别写的感觉比较简单,总的概括之后感觉功能可以简略成if filter_words in ...
- 超强敏感词过滤算法第二版 可以忽略大小写、全半角、简繁体、特殊符号、HTML标签干扰
上一篇 发一个高性能的敏感词过滤算法 可以忽略大小写.全半角.简繁体.特殊符号干扰 改进主要有几点: 用BitArray取代Dictionary用空间换时间 性能进一步提升 大概会增加词库的 6k* ...
- 5分钟构建无服务器敏感词过滤后端系统(基于FunctionGraph)
摘要:开发者通过函数工作流,无需配置和管理服务器,以无服务器的方式构建应用,便能开发出一个弹性高可用的后端系统.托管函数具备以毫秒级弹性伸缩.免运维.高可靠的方式运行,极大地提高了开发和运维效率,减小 ...
- 基于DFA算法、RegExp对象和vee-validate实现前端敏感词过滤
面临敏感词过滤的问题,最简单的方案就是对要检测的文本,遍历所有敏感词,逐个检测输入的文本是否包含指定的敏感词. 很明显上面这种实现方法的检测时间会随着敏感词库数量的增加而线性增加.系统会因此面临性能和 ...
- java实现敏感词过滤(DFA算法)
小Alan在最近的开发中遇到了敏感词过滤,便去网上查阅了很多敏感词过滤的资料,在这里也和大家分享一下自己的理解. 敏感词过滤应该是不用给大家过多的解释吧?讲白了就是你在项目中输入某些字(比如输入xxo ...
- 用php实现一个敏感词过滤功能
周末空余时间撸了一个敏感词过滤功能,下边记录下实现过程. 敏感词,一方面是你懂的,另一方面是我们自己可能也要过滤一些人身攻击或者广告信息等,具体词库可以google下,有很多. 过滤敏感词,使用简单的 ...
- 浅析敏感词过滤算法(C++)
为了提高查找效率,这里将敏感词用树形结构存储,每个节点有一个map成员,其映射关系为一个string对应一个TreeNode. STL::map是按照operator<比较判断元素是否相同,以及 ...
随机推荐
- Office文档WEB端在线浏览(转换成Html)
最近在做了一个项目,要求是对Office文档在线预览.下面给大家分享一下我的方法. 1.第一种方法(不建议使用)我是在网上搜了一个利用COM组件对office文档进行转换,但是此方法必须要装Offic ...
- CodeForces 990B Micro-World(思维、STL)
http://codeforces.com/problemset/problem/990/B 题意: 有n个细菌,每个细菌的尺寸为ai,现在有以常数k,如果细菌i的尺寸ai大于细菌j的尺寸aj,并且a ...
- 当年写的C代码
#ifndef KMIN_H_ #define KMIN_H_ /******************************************************************* ...
- 吴裕雄--天生自然运维技术:LMT
LMT,Local Maintenance Terminal的缩写,意思是本地维护终端.LMT是一个逻辑概念.LMT连接到RNC外网,提供NODE B操作维护的用户界面. LMT也是许可证管理技术Li ...
- Java之常见异常
package com.atguigu.java1; import java.io.File;import java.io.FileInputStream;import java.util.Date; ...
- Ubuntu更改源地址列表
1. 备份源列表 sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup 2.打开源列表 sudo gedit /etc/apt/sour ...
- AtCoder Grand Contest 033
为什么ABC那么多?建议Atcoder多出些ARC/AGC,好不容易才轮到AGC…… A 签到.就是以黑点为源点做多元最短路,由于边长是1直接bfs就好了,求最长路径. #include<bit ...
- [LC] 285. Inorder Successor in BST
Given a binary search tree and a node in it, find the in-order successor of that node in the BST. Th ...
- [APIO2009-C]抢掠计划
题:https://www.cometoj.com/problem/0461 分析:求边双,最后求多汇点最长路 #include<iostream> #include<cstring ...
- npm基本语法
npm -version 查看npm版本 npm install <name> 安装node.js的依赖包 npm install <name> @3.0.6 安装版本为3 ...