Python 爬虫-Scrapy框架基本使用
2017-08-01 22:39:50
一、Scrapy爬虫的基本命令
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行。
- Scrapy命令行格式
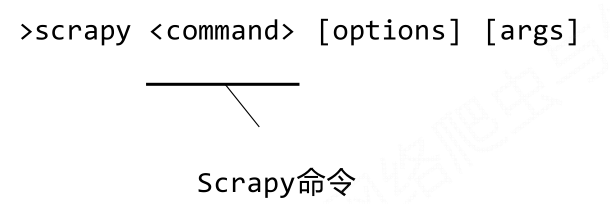
- Scrapy常用命令
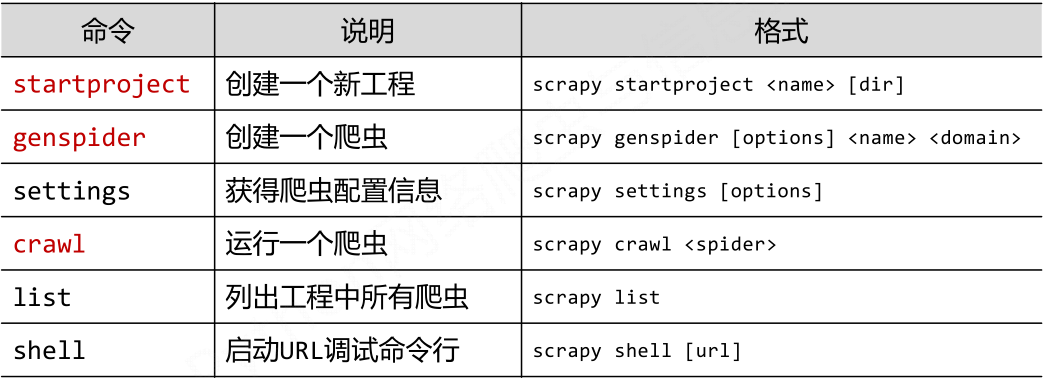
- 采用命令行的原因
命令行(不是图形界面)更容易自动化,适合脚本控制本质上,Scrapy是给程序员用的,功能(而不是界面)更重要。
二、Scrapy爬虫的一个基本例子
演示HTML页面地址:http://python123.io/ws/demo.html
步骤一:建立一个Scrapy爬虫
选取一个文件夹,例如E:\python,然后执行如下命令。

此时在python文件夹下就会生成一个名为Python123demo的工程,该工程的文件结构为:


步骤二:在工程中产生一个Scrapy爬虫
使用cd进入E:\python\python123demo文件夹,然后执行如下命令。

该命令作用:
(1)生成一个名称为demo的spider
(2)在spiders目录下增加代码文件demo.py
该命令仅用于生成demo.py,该文件也可以手工生成
步骤三:配置产生的spider爬虫

demo文件是使用genspider命令产生的一个spider。
- 继承于scrapy.Spider
- name='demo'说明爬虫的名字是demo
- allowed_domains指爬取网站时只能爬取该域名下的网站链接
- star_urls是指爬取的一个或多个起始的爬取url
- parse()用于处理响应并发现新的url爬取请求
配置:(1)初始URL地址 (2)获取页面后的解析方式

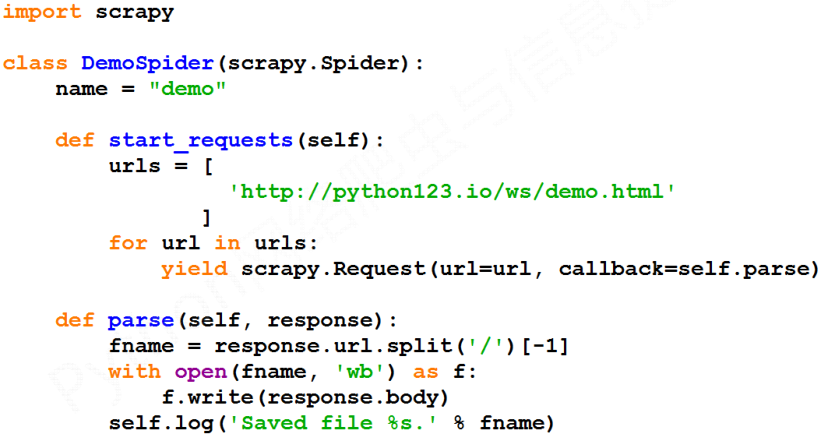
步骤四:运行爬虫,获取网页
执行如下代码:

demo爬虫被执行,捕获页面存储在demo.html
还有一种等价的表达方式:
三、Scrapy爬虫的基本使用
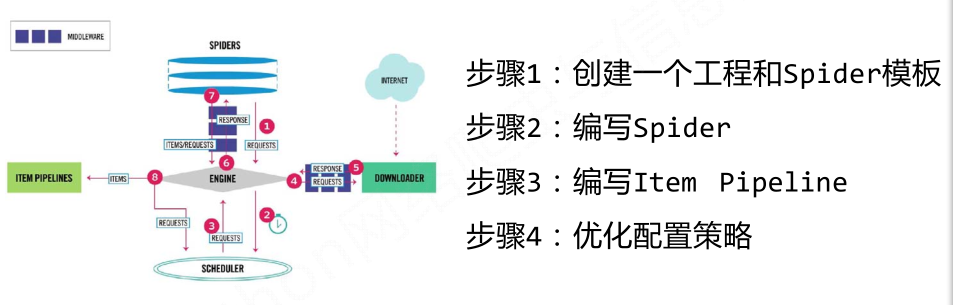
这四个步骤会涉及到三个类:Request类、Response类、Item类;
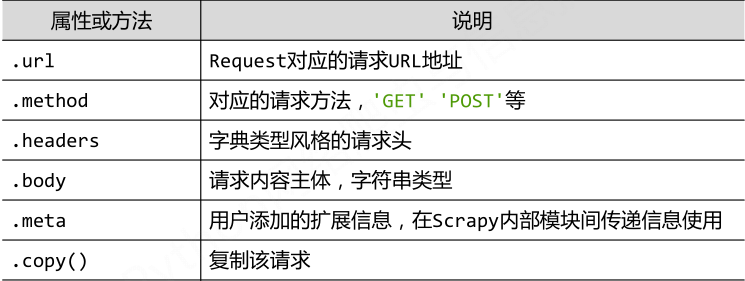
- Request类
class scrapy.http.Request():Request对象表示一个HTTP请求,由Spider生成,由Downloader执行。
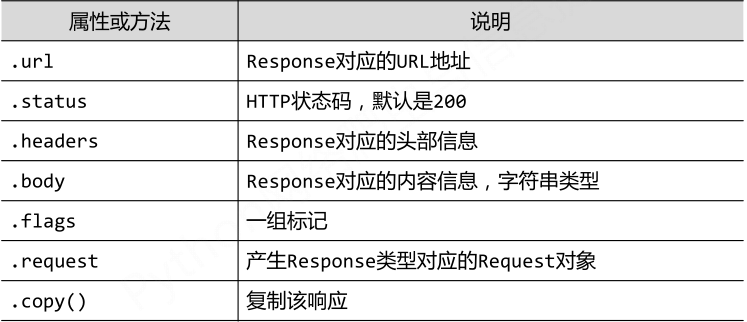
- Response类
class scrapy.http.Response():Response对象表示一个HTTP响应;由Downloader生成,由Spider处理。
- Item类
class scrapy.item.Item():Item对象表示一个从HTML页面中提取的信息内容;由Spider生成,由Item Pipeline处理;Item类似字典类型,可以按照字典类型操作。
Python 爬虫-Scrapy框架基本使用的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- python爬虫----scrapy框架简介和基础应用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
随机推荐
- VMWARE安装centos6 http://www.centoscn.com/image-text/setup/2013/0816/1263.html
http://www.centoscn.com/image-text/setup/2013/0816/1263.html
- redis环境搭建与配置
通过初始化脚本启动redis 1.将redis源码的utils文件夹下面有的redis_init_script复制到/etc/init.d/redis_端口号下面. 带密码的实例 REQUIRED_P ...
- zw版【转发·台湾nvp系列Delphi例程】HALCON HistoToThresh1
zw版[转发·台湾nvp系列Delphi例程]HALCON HistoToThresh1 procedure TForm1.Button1Click(Sender: TObject);var imag ...
- Impala shell详解
不多说,直接上干货! 查看帮助文档 impala-shell -h 刷新整个云数据 impala-shell -ruse impala;show tables; 去格式化,查询大数据量时可以提高性能 ...
- 《Hadoop权威指南》(Hadoop:The Definitive Guide) 气象数据集下载脚本
已过时,无法使用 从网上找到一个脚本,修改了一下 #!/bin/bash CURRENT_DIR=$(cd `dirname $0`; pwd) [ -e $CURRENT_DIR/ncdc ] || ...
- centos7源码编译安装Subversion 1.9.5
svn是Subversion的简称,是一个开放源代码的版本控制系统.svn有两种运行方式:1.独立服务器(svn://xxx.xxx/xxx) 2.借助apache(http://svn.xxx.xx ...
- Linux基础命令---lsattr
lsattr 显示指定文件或者目录的属性. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.SUSE.openSUSE.Fedora. 1.语法 lsattr [选项 ...
- 关于hibernate中的session与数据库连接关系以及getCurrentSession 与 openSession() 的区别
1.session与connection,是多对一关系,每个session都有一个与之对应的connection,一个connection不同时刻可以供多个session使用. 2.多个sessi ...
- 20145216史婧瑶《网络对抗》Web安全基础实践
20145216史婧瑶<网络对抗>Web安全基础实践 实验问题回答 (1)SQL注入攻击原理,如何防御 攻击原理: SQL注入攻击指的是通过构建特殊的输入作为参数传入web应用程序,而这些 ...
- CAN/J1850/
(1)CAN:(差分信号)有信号CANH=3.5V,CANL=1.5V, 没有信号CANH=2.5V,CANL=2.5V 速率:CAN系统又分为高速和低速,高速CAN系统采用硬线是动力型,速度:500 ...