Python 爬虫-Scrapy框架基本使用
2017-08-01 22:39:50
一、Scrapy爬虫的基本命令
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行。
- Scrapy命令行格式
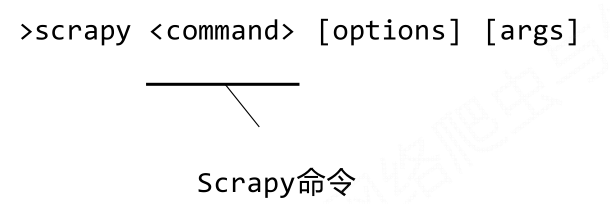
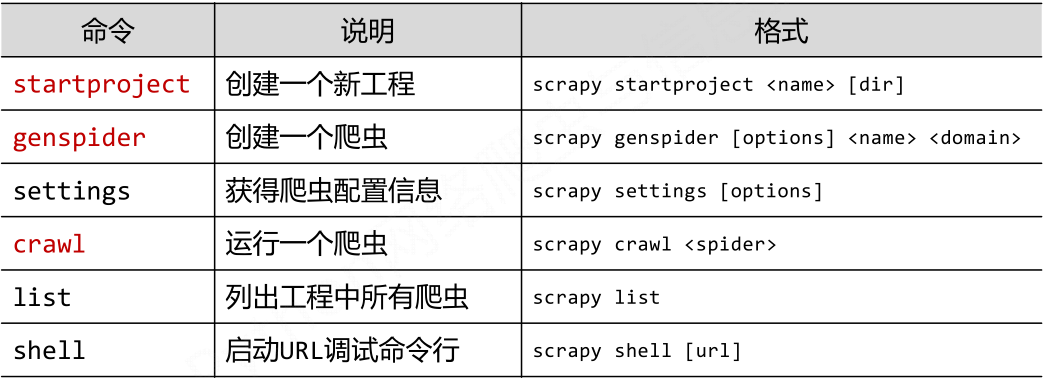
- Scrapy常用命令
- 采用命令行的原因
命令行(不是图形界面)更容易自动化,适合脚本控制本质上,Scrapy是给程序员用的,功能(而不是界面)更重要。
二、Scrapy爬虫的一个基本例子
演示HTML页面地址:http://python123.io/ws/demo.html
步骤一:建立一个Scrapy爬虫
选取一个文件夹,例如E:\python,然后执行如下命令。

此时在python文件夹下就会生成一个名为Python123demo的工程,该工程的文件结构为:


步骤二:在工程中产生一个Scrapy爬虫
使用cd进入E:\python\python123demo文件夹,然后执行如下命令。

该命令作用:
(1)生成一个名称为demo的spider
(2)在spiders目录下增加代码文件demo.py
该命令仅用于生成demo.py,该文件也可以手工生成
步骤三:配置产生的spider爬虫

demo文件是使用genspider命令产生的一个spider。
- 继承于scrapy.Spider
- name='demo'说明爬虫的名字是demo
- allowed_domains指爬取网站时只能爬取该域名下的网站链接
- star_urls是指爬取的一个或多个起始的爬取url
- parse()用于处理响应并发现新的url爬取请求
配置:(1)初始URL地址 (2)获取页面后的解析方式

步骤四:运行爬虫,获取网页
执行如下代码:

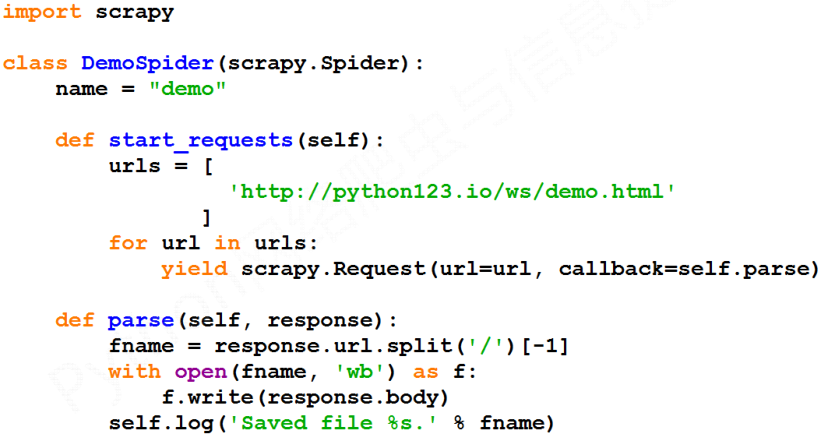
demo爬虫被执行,捕获页面存储在demo.html
还有一种等价的表达方式:
三、Scrapy爬虫的基本使用
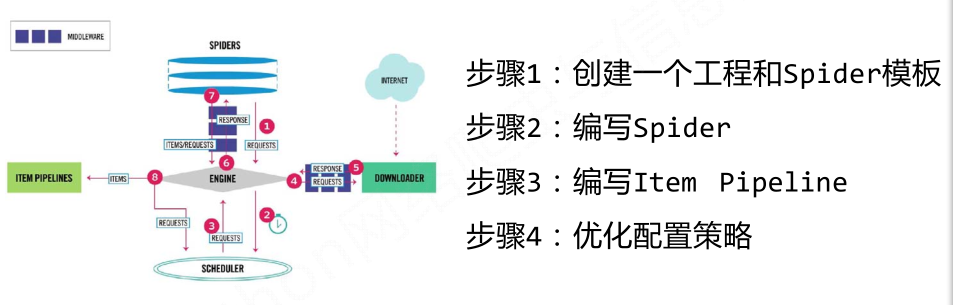
这四个步骤会涉及到三个类:Request类、Response类、Item类;
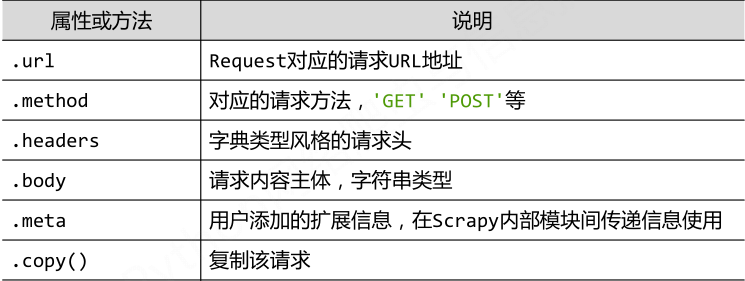
- Request类
class scrapy.http.Request():Request对象表示一个HTTP请求,由Spider生成,由Downloader执行。
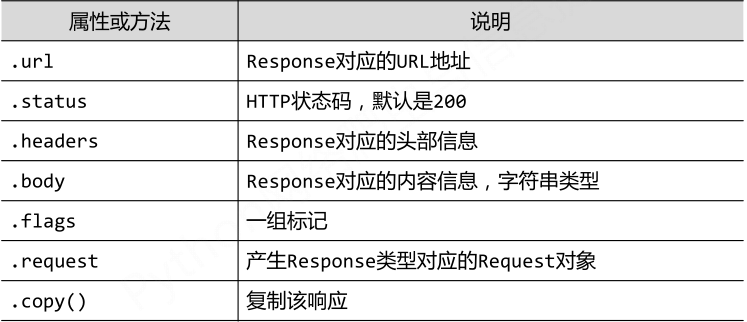
- Response类
class scrapy.http.Response():Response对象表示一个HTTP响应;由Downloader生成,由Spider处理。
- Item类
class scrapy.item.Item():Item对象表示一个从HTML页面中提取的信息内容;由Spider生成,由Item Pipeline处理;Item类似字典类型,可以按照字典类型操作。
Python 爬虫-Scrapy框架基本使用的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- python爬虫----scrapy框架简介和基础应用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
随机推荐
- PhoneGap+Cordova+SenchaTouch-01-环境搭建
转http://my.oschina.net/zhongwenhao/blog/369465 环境搭建基于 windows ,mac系统可以借鉴 1.安装NodeJS 和ruby http://no ...
- EditPlus 4.3.2499 中文版已经发布(11月21日更新)
新的版本修复了如下问题: 文本库的日期快捷方式“^@”失效. 列选模式下“减少缩进量”命令无法执行. 在某些情况下突出显示匹配括号导致程序崩溃.(这个问题是我发现的,电邮告诉作者后,一天之内就修复了) ...
- 错误源:.net SqlClient data provider
下午在做毕业设计的时候,想删除数据库的一条数据,结果发现删除的时候老是出现 ======错误源:.net SqlClient data provider==== 这样的错误:本来以为是我还在运行着项目 ...
- JavaScript实现功能全集
JavaScript就这么回事1:基础知识 1 创建脚本块 <script language="JavaScript">JavaScript code goes her ...
- Python: attrgetter()函数: 排序不支持原生比较的对象
问题: 想排序类型相同的对象,但是他们不支持原生的比较操作. answer: 内置的sorted()函数有一个关键字参数key,可传入一个callable对象给它 这个callabel对象对每个传入的 ...
- 了解SpringBoot
一.SpringBoot是什么? Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发 ...
- python 有道翻译
import requests import time import random import hashlib i = str(int(time.time()*1000)+random.randin ...
- (一)MySQL登录与退出
mysql登陆: win+r输入cmd按enter进入命令行界面: > mysql -uroot -p -P3306 -h127.0.0.1 > 输入密码后按回车 mysql退出: mys ...
- Python入门之Python引用模块和查找模块路径
#这篇文章主要介绍了Python引用模块和Python查找模块路径的相关资料,需要的朋友可以参考下 模块间相互独立相互引用是任何一种编程语言的基础能力.对于“模块”这个词在各种编程语言中或许是不同的, ...
- c++学习之map基本操作
map作为最常用的数据结构之一,用的好可以大幅度的提升性能. // java_cpp_perftest.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h& ...