Coursera公开课笔记: 斯坦福大学机器学习第六课“逻辑回归(Logistic Regression)” 清晰讲解logistic-good!!!!!!
原文:http://52opencourse.com/125/coursera%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%94%E8%AE%B0-%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AC%AC%E5%85%AD%E8%AF%BE-%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92-logistic-regression
斯坦福大学机器学习第六课"逻辑回归“学习笔记,本次课程主要包括7部分:
1) Classification(分类)
2) Hypothesis Representation
3) Decision boundary(决策边界)
4) Cost function(代价函数,成本函数)
5) Simplified cost function and gradient descent(简化版代价函数及梯度下降算法)
6) Advanced optimization(其他优化算法)
7) Multi-class classification: One-vs-all(多类分类问题)
以下是每一部分的详细解读。
1) Classification(分类)
分类问题举例:
- 邮件:垃圾邮件/非垃圾邮件?
- 在线交易:是否欺诈(是/否)?
- 肿瘤:恶性/良性?
以上问题可以称之为二分类问题,可以用如下形式定义:
其中0称之为负例,1称之为正例。
对于多分类问题,可以如下定义因变量y:
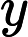
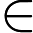
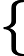
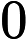
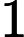
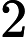
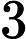

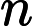
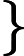
如果分类器用的是回归模型,并且已经训练好了一个模型,可以设置一个阈值:
- 如果
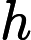
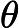
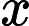
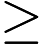
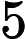 ,则预测y=1,既y属于正例;
,则预测y=1,既y属于正例; - 如果
 ,则预测y=0,既y属于负例;
,则预测y=0,既y属于负例;
如果是线性回归模型,对于肿瘤这个二分类问题,图形表示如下:
但是对于二分类问题来说,线性回归模型的Hypothesis输出值可以大于1也可以小于0。
这个时候我们引出逻辑回归,逻辑回归的Hypothesis输出介于0与1之间,既:
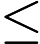
注: 以下引自李航博士《统计学习方法》1.8节关于分类问题的一点描述:
分类是监督学习的一个核心问题,在监督学习中,当输出变量Y取有限个离散值时,预测问题便成为分类问题。这时,输入变量X可以是离散的,也可以是连续的。监督学习从数据中学习一个分类模型或分类决策函数,称为分类器(classifier)。分类器对新的输入进行输出的预测(prediction),称为分类(classification).
2) Hypothesis Representation
逻辑回归模型:
上一节谈到,我们需要将Hypothesis的输出界定在0和1之间,既:
但是线性回归无法做到,这里我们引入一个函数g, 令逻辑回归的Hypothesis表示为:

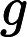
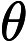
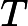
这里g称为Sigmoid function或者Logistic function, 具体表达式为:
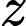

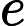

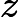
Sigmoid 函数在有个很漂亮的“S"形,如下图所示(引自维基百科):
综合上述两式,我们得到逻辑回归模型的数学表达式:
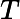
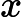
其中是参数。
Hypothesis输出的直观解释:
= 对于给定的输入x,y=1时估计的概率
例如,对于肿瘤(恶性/良性),如果输入变量(特征)是肿瘤的大小:
这里Hypothesis表示的是”病人的肿瘤有70%的可能是恶性的“。
较正式的说法可以如下表示:
给定输入x,参数化的(参数空间), y=1时的概率。
数学上可以如下表示:
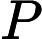
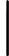
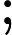
对于因变量y=0或1这样的二分类问题:

3) Decision boundary(决策边界)
如上节所述,逻辑回归模型可以如下表示:
假设给定的阈值是0.5,当时, y = 1;
当时,y = 0;
再次回顾sigmoid function的图形,也就是g(z)的图形:
当时, ;
对于, 则, 此时意味着预估y=1;
反之,当预测y = 0时,;
我们可以认为 = 0是一个决策边界,当它大于0或小于0时,逻辑回归模型分别预测不同的分类结果。例如,
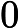
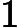
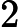
分别取-3, 1, 1,
则当时, y = 1; 则 是一个决策边界,图形表示如下:
是一个决策边界,图形表示如下:
上述只是一个线性的决策边界,当更复杂的时候,我们可以得到非线性的决策边界,例如:
这里当时,y=1,决策边界是一个圆形,如下图所示:
更复杂的例子,请参考官方PPT,这里就不再举例了。
4) Cost function(代价函数,成本函数)
逻辑回归概览:
逻辑回归是一种有监督的学习方法,因此有训练集:
对于这m个训练样本来说,每个样本都包含n+1个特征:
其中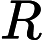

 , .
, .
Hypothesis可表示为:


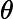
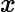
与线性回归相似,我们的问题是如何选择合适的参数?
Cost Function:
线性回归的Cost Function定义为:
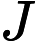
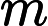
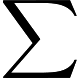
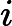

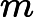
这里可以把简写为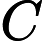

 ,更简化的表达式为:
,更简化的表达式为:
如果和线性回归相似,这里取 ,会存在一个问题,也就是逻辑回归的Cost Function是“非凸”的,如下图所示:
我们知道,线性回归的Cost Function是凸函数,具有碗状的形状,而凸函数具有良好的性质:对于凸函数来说局部最小值点即为全局最小值点,因此只要能求得这类函数的一个最小值点,该点一定为全局最小值点。
因此,上述的Cost Function对于逻辑回归是不可行的,我们需要其他形式的Cost Function来保证逻辑回归的成本函数是凸函数。
这里补充一段李航博士《统计学习方法》里关于Cost Function或者损失函数(loss function)的说明,大家就可以理解Cost Function不限于一种方式,而是有多种方式可选,以下摘自书中的1.3.2小节:
监督学习问题是在假设空间F中选取模型f作为决策函数,对于给定的输入X,由f(X)给出相应的输出Y,这个输出的预测值f(X)与真实值Y可能一致也可能不一致,用一个损失函数(loss function)或代价函数(cost function)来度量预测错误的程度。损失函数是f(X)和Y的非负实值函数,记作L(Y, f(X)).
统计学习中常用的损失函数有以下几种:
(1) 0-1损失函数(0-1 loss function):
(2) 平方损失函数(quadratic loss function)
(3) 绝对损失函数(absolute loss function)
(4) 对数损失函数(logarithmic loss function) 或对数似然损失函数(log-likelihood loss function)
损失函数越小,模型就越好。

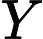
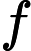
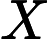

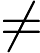
逻辑回归的Cost Function:
基于上节的描述和补充,这里我们选择对数似然损失函数作为逻辑回归的Cost Function:
直观的来解释这个Cost Function,首先看当y=1的情况:
直观来看, 如果y = 1, ,则Cost = 0,也就是预测的值和真实的值完全相等的时候Cost =0;
但是,当 时,
时, 
直观来看,由于预测的结果南辕北辙:
如果, 也就是预测,也就是y=1的概率是0,但是实际上y = 1
因此对于这个学习算法给予一个很大的Cost的惩罚。
同理对于y=0的情况也适用:
5) Simplified cost function and gradient descent(简化版代价函数及梯度下降算法)
逻辑回归的Cost Function可以表示为:
由于y 只能等于0或1,所以可以将逻辑回归中的Cost function的两个公式合并,具体推导如下:
故逻辑回归的Cost function可简化为:
对于这个公式,这里稍微补充一点,注意中括号中的公式正是对逻辑回归进行最大似然估计中的最大似然函数,对于最大似然函数求最大值,从而得到参数(\theta\)的估计值。反过来,这里为了求一个合适的参数,需要最小化Cost function,也就是:
而对于新的变量x来说,就是根据的公式输出结果:
与线性回归相似,这里我们采用梯度下降算法来学习参数,对于:
目标是最小化,则梯度下降算法的如下:
对求导后,梯度下降算法如下:
注意,这个算法和线性回归里的梯度下降算法几乎是一致的,除了的表示不同。
6) Advanced optimization(其他优化算法)
优化算法:
给定参数,我们可以写成代码来计算:
优化算法除了梯度下降算法外,还包括:
- Conjugate gradient method(共轭梯度法)
- Quasi-Newton method(拟牛顿法)
- BFGS method
- L-BFGS(Limited-memory BFGS)
后二者由拟牛顿法引申出来,与梯度下降算法相比,这些算法的优点是:
第一,不需要手动的选择步长;
第二,通常比梯度下降算法快;
但是缺点是更复杂-更复杂也是缺点吗?其实也算不上,关于这些优化算法,推荐有兴趣的同学看看52nlp上这个系列的文章:无约束最优化,作者是我的师兄,更深入的了解可以参考这篇文章中推荐的两本书:
用于解无约束优化算法的Quasi-Newton Method中的LBFGS算法到这里总算初步介绍完了,不过这里笔者要承认的是这篇文档省略了许多内容,包括算法收敛性的证明以及收敛速度证明等许多内容。因此读者若希望对这一块有一个更深入的认识可以参考以下两本书:
1) Numerical Methods for Unconstrained Optimization and Nonlinear Equations(J.E. Dennis Jr. Robert B. Schnabel)
2) Numerical Optimization(Jorge Nocedal Stephen J. Wright)
7) Multi-class classification: One-vs-all(多类分类问题)
多类分类问题举例:
电子邮件分类/标注: 工作邮件,朋友邮件,家庭邮件,爱好邮件
医疗图表(medical diagrams): 没有生病,着凉,流感
天气:晴天,多云,雨,雪
二类分类问题如下图所示:
多类分类问题如下所示:
One-vs-all(one-vs-rest):
对于多类分类问题,可以将其看做成二类分类问题:保留其中的一类,剩下的作为另一类。例如,对于下面这个例子:
可以分别计算其中一类相对于其他类的概率:
总结-One-vs-all方法框架:
对于每一个类 i 训练一个逻辑回归模型的分类器,并且预测 y = i时的概率;
对于一个新的输入变量x, 分别对每一个类进行预测,取概率最大的那个类作为分类结果:
参考资料:
李航博士《统计学习方法》
http://en.wikipedia.org/wiki/Sigmoid_function
http://en.wikipedia.org/wiki/Logistic_function
http://en.wikipedia.org/wiki/Loss_function
http://en.wikipedia.org/wiki/Conjugate_gradient_method
http://en.wikipedia.org/wiki/Quasi-Newton_method
时间: 2012年 5月 16日 分类:机器学习 作者: 52nlp (3,210 基本)
编辑 2012年 5月 20日 作者:52nlp
Coursera公开课笔记: 斯坦福大学机器学习第六课“逻辑回归(Logistic Regression)” 清晰讲解logistic-good!!!!!!的更多相关文章
- LR 算法总结--斯坦福大学机器学习公开课学习笔记
在有监督学习里面有几个逻辑上的重要组成部件[3],初略地分可以分为:模型,参数 和 目标函数.(此部分转自 XGBoost 与 Boosted Tree) 一.模型和参数 模型指给定输入xi如何去 ...
- 斯坦福ML公开课笔记15—隐含语义索引、神秘值分解、独立成分分析
斯坦福ML公开课笔记15 我们在上一篇笔记中讲到了PCA(主成分分析). PCA是一种直接的降维方法.通过求解特征值与特征向量,并选取特征值较大的一些特征向量来达到降维的效果. 本文继续PCA的话题, ...
- 机器学习公开课笔记(5):神经网络(Neural Network)——学习
这一章可能是Andrew Ng讲得最不清楚的一章,为什么这么说呢?这一章主要讲后向传播(Backpropagration, BP)算法,Ng花了一大半的时间在讲如何计算误差项$\delta$,如何计算 ...
- 机器学习公开课笔记(8):k-means聚类和PCA降维
K-Means算法 非监督式学习对一组无标签的数据试图发现其内在的结构,主要用途包括: 市场划分(Market Segmentation) 社交网络分析(Social Network Analysis ...
- 机器学习公开课笔记(4):神经网络(Neural Network)——表示
动机(Motivation) 对于非线性分类问题,如果用多元线性回归进行分类,需要构造许多高次项,导致特征特多学习参数过多,从而复杂度太高. 神经网络(Neural Network) 一个简单的神经网 ...
- 机器学习公开课笔记(3):Logistic回归
Logistic 回归 通常是二元分类器(也可以用于多元分类),例如以下的分类问题 Email: spam / not spam Tumor: Malignant / benign 假设 (Hypot ...
- 人工智能头条(公开课笔记)+AI科技大本营——一拨微信公众号文章
不错的 Tutorial: 从零到一学习计算机视觉:朋友圈爆款背后的计算机视觉技术与应用 | 公开课笔记 分享人 | 叶聪(腾讯云 AI 和大数据中心高级研发工程师) 整 理 | Leo 出 ...
- 斯坦福大学机器学习,EM算法求解高斯混合模型
斯坦福大学机器学习,EM算法求解高斯混合模型.一种高斯混合模型算法的改进方法---将聚类算法与传统高斯混合模型结合起来的建模方法, 并同时提出的运用距离加权的矢量量化方法获取初始值,并采用衡量相似度的 ...
- CS229 斯坦福大学机器学习复习材料(数学基础) - 线性代数
CS229 斯坦福大学机器学习复习材料(数学基础) - 线性代数 线性代数回顾与参考 1 基本概念和符号 1.1 基本符号 2 矩阵乘法 2.1 向量-向量乘法 2.2 矩阵-向量乘法 2.3 矩阵- ...
随机推荐
- Revit API判断是不是柱族模板
OwnerFamily即族模板.获取类别的方法:Document.Settings.Categories.get_Item(BuiltInCategory.OST_Columns); //判断是不是柱 ...
- delphi 服务程序
http://www.delphifans.com/InfoView/Article_662.html 用Delphi创建服务程序 Windows 2000/XP和2003等支持一种叫做"服 ...
- AngularJS中Directive间交互实现合成
假设需要烹饪一道菜肴,有3种原料,可以同时使用所有的3种原料,可以使用其中2种,也可以使用其中1种. 如果以Directive的写法,大致是:<bread material1 material2 ...
- 查询EBS系统在线人数
/* Formatted on 2018/3/14 23:25:51 (QP5 v5.256.13226.35538) */ SELECT U.USER_NAME , APP.APPLICATION_ ...
- Android中的Audio播放:竞争Audio之Audio Focus的应用
from://http://blog.csdn.net/thl789/article/details/7422931 Android是多任务系统,Audio系统是竞争资源.Android2.2之前,没 ...
- python测试开发django-42.auth模块登陆认证
前言 在开发一个网站时,经常会用到用户的注册和登陆相关的账号管理功能,auth模块是Django提供的标准权限管理系统,可以提供用户身份认证, 用户组和权限管理. 像用户注册.用户登录.用户认证.注销 ...
- python测试开发django-13.操作数据库(增删改查)
前言 django的models模块里面可以新增一张表和字段,通常页面上的数据操作都来源于数据库的增删改查,django如何对msyql数据库增删改查操作呢? 本篇详细讲解django操作mysql数 ...
- C++ 继承体系中的名称覆盖
首先一个简单的样例: int x; int f() { double x; cin >> x; return x; } 在上述代码中.函数f的局部变量x掩盖了全局变量x.这得从 " ...
- java过滤特殊字符的正则表达式
// 过滤特殊字符 public staticString StringFilter(String str) throws PatternSyntaxException { // 只允许字母和数字 / ...
- Objective-C 入门笔记
简介 建立在C语言之上,可以混编C/C++代码,编写一个类需要二个文件: .h的头文件 .m的实现文件(如果是C/C++混编文件,文件后缀为.mm) 既然有头文件,所以很多人会拿它与C++进行类比,它 ...