数仓ETL系统:给强大的“心脏”配上“超级流水线”
摘要:在数据仓库平台建设过程中,数据的加载、卸载,各层数据模型之间的数据流转,业务规则的实现等等数据加工过程都会以ETL任务的方式实现。
一、前言
在数据仓库平台建设过程中,数据的加载、卸载,各层数据模型之间的数据流转,业务规则的实现等等数据加工过程都会以ETL任务的方式实现。 构建ETL子系统是数据仓库系统实施的一个非常重要的环节,在仓库平台建设过程中搭建一个完整、标准的ETL子系统是数据仓库平台建设的基础性目标之一。
ETL是Extraction(数据抽取),Transform(数据转换)和Loading(数据加载)这三个数据处理动作的缩写,也是早期数据仓库建设的数据流转处理顺序,因此形成的专用术语沿用至今。但是随着作为数据仓库核心的数据库引擎技术的不断发展,ETL模式也在不断发展和改变,逐渐形成了E-L-T,E-T-L-T等不同形式。对于GaussDB DWS为代表的MPPDB数据仓库平台,则多以ELT或是ETLT模式为主来构建ETL子系统。
二、ETL子系统逻辑参考架构
ETL子系统的建设目的是将企业中的分散、零乱、标准不统一的异构数据源的业务数据整合到一起,进行必要的清洗和转换,形成高质量的统一的数据模型,或者是便于用户查询,分析和探索的维度模型。
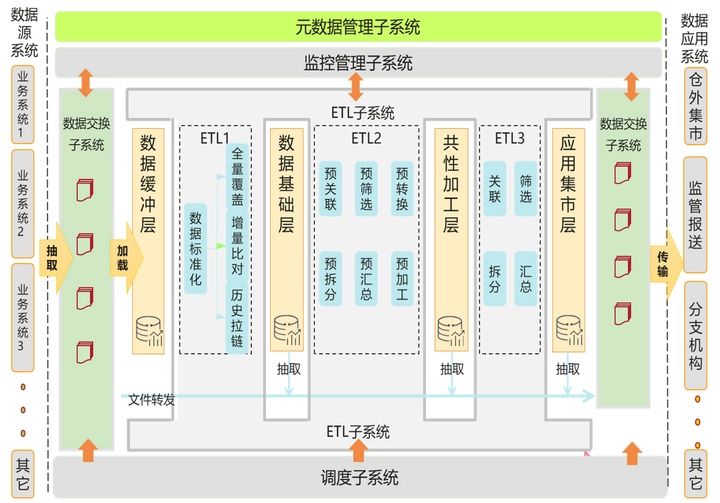
图1 数据仓库子系统参考架构
2.1 数据抽取(Extraction)
数据抽取是从数据仓库的上游系统(通常是核心系统,业务系统或外部系统)进行全量或增量数据抓取的过程。而随着企业内部信息底层架构的完善和数据平台功能的划分,不同平台通常采用松耦合的方式进行关联。传统中下游系统直接到上游系统进行数据抽取的这种方式并不符合当前技术的发展趋势。一方面,下游系统直接到上游系统进行数据抽取操作牵涉到权限的开放管理,增加了上游系统的数据安全风险。另一方面,本身数据抽取操作也应当在业务系统自身正常业务完成后的时间窗口进行,以避免数据抽取时对正常作业流程的资源竞争。因此数据抽取这个环节的操作,通常是上下游系统进行接口协商,由上游系统按照接口规范进行数据卸载操作。或者对于更成熟的企业,会构建统一的数据交换平台来完成企业内部统一的数据抽取/卸载工作。
对于数据仓库平台来说,数据抽取的工作更多的是形成统一的接口规范。
2.2 数据转换(Transform)
广义上的数据转换包括数据清洗,数据关联加工,数据标准化处理,数据汇总聚合等操作。大部分基于业务规则和数据模型的数据转换操作在MPPDB数据库内实现比在数据库外的ETL服务器上进行实现效率更高。而这种转换操作在数据库内通过SQL实现T过程,也比通过ETL工具实现T过程更具有标准化和开放性,适合业务人员参与T过程的开发,校验。
2.3 数据加载(Loading)
对于数据仓库而言,不仅仅是数据加载,还包括数据卸载,也就是Loading和Unloading过程。典型的场景就是在数据到达的高峰期进行大量的文件加载入库的操作。而库内数据加工完成后,及时地进行数据卸载操作,形成接口文件推送给下游系统。所以高效地批量数据加载和卸载操作是数据仓库ETL系统要面对的主要挑战之一。而随着客户对实时数据仓库的需求越来越普遍,数据库和消息队列,数据流组件之间的实时数据加载和卸载的技术则是当前ETL系统构建时面临的又一个技术挑战。
三、ETL子系统的两种实现架构
依托GaussDB(DWS)数据库构建ETL系统一般有两种实现方式:重ETL Server方案和MPPDB方案。如下图
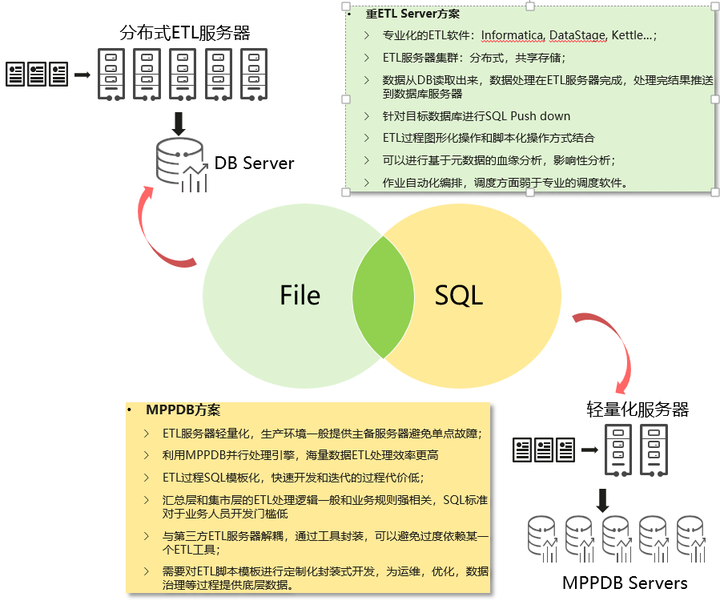
图2 两种架构示意图
3.1 重ETL Server方案
这种方案借助专业化的ETL软件:Informatica, DataStage, Kettle等软件,采用分布式的/基于共享存储的ETL服务器集群方式部署ETL软件。在执行ETL任务的时候,数据从MPPDB读取出来,数据处理过程在ETL服务器完成,处理完结果再推送到数据库服务器,其中有些操作可以通过SQL Push down在数据库内完成。
这种方案的特点在于整个ETL开发和部署过程图形化操作和脚本化操作方式结合,基于工具过程的开发也可以对ETL过程进行基于元数据的血缘分析,影响性分析;作业自动化编排,调度方面ETL工具的功能弱于专业的调度软件。
基于ETL工具方案对于ETL开发过程来说需要专业的开发人员,要对ETL工具本身有很深入的了解,从这方面来说,过于专业化的工具门槛不利于企业内部的业务专家和分析人员介入ETL开发过程。而ETL方面对于软硬件的投入成本也是需要纳入考量的一个问题。
3.2 MPPDB方案
- 本方案中ETL服务器轻量化,生产环境一般提供主备服务器避免单点故障即可。主要特点如下:
- 利用MPPDB并行处理引擎,海量数据ETL处理效率更高。
- ETL过程SQL模板化,快速开发和迭代的过程代价低;
- 汇总层和集市层的ETL处理逻辑一般和业务规则强相关,SQL标准对于业务人员开发门槛低
- 与第三方ETL服务器解耦,通过工具封装,可以避免过度依赖某一个ETL工具;
- 需要对ETL脚本模板进行定制化封装式开发,为运维,优化,数据治理等过程提供底层数据。
3.3简单对比
重ETL Server方案适合基于文件的数据清洗类ETL工作:对于字符集的转换处理;按照接口规范对接口数据的预处理(判断文件大小,记录行数等文件信息和属性方面的数据质量检查);文件的分组,拆分,压缩,解压缩等;以及延伸出去的文件监控和传输功能。
MPPDB方案实际上就是基于SQL的实现方案,适合数据规范化处理:如业务编码转换,业务逻辑主键生成,符合业务规范的数据转换处理;数据转换处理:汇总,聚合,过滤,关联,拆分,转换等。
四、GaussDB(DWS)ETL系统实现要点
对于GaussDB(DWS)而言,大多数场合下推荐采用MPPDB方案。实现这种方案实际上要实现ETL SQL模板的封装,把ETL开发过程与外部ETL调度系统的结合进行分层处理。通过模板方式实现与调度软件,和操作系统的接口封装,把SQL实现业务的模块封装在GSQL工具中,开放给业务人员和开发人员,令其聚焦在业务实现本身,而不用在意外部环境对于ETL过程操作的影响。
4.1 基于MPPDB的ETL环境逻辑视图
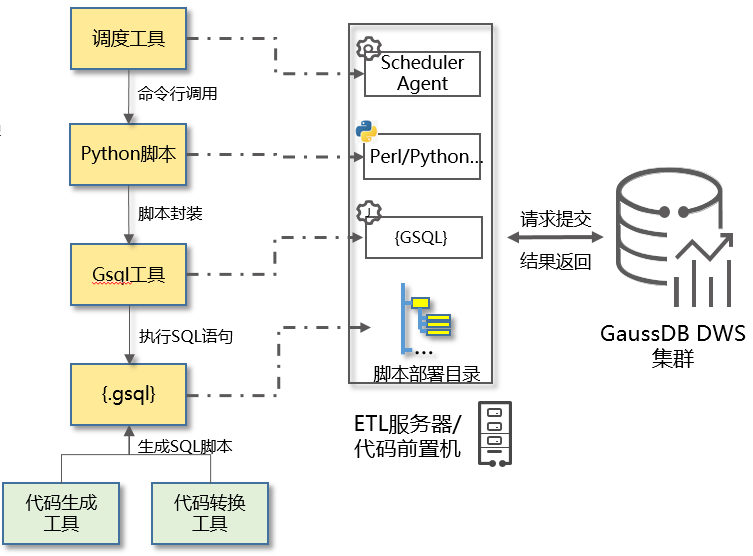
图3 逻辑视图
- ETL调度
数据仓库平台的ETL作业系统是一种后台非交互方式运行的批量数据处理系统。ETL作业调度是将数据仓库系统中运行的各种后台作业自动化,并监视和控制作业的运行。使用调度软件实现作业调度。作业可以分布在多个服务器平台上,能够设定作业定义、依赖关系、顺序关系、工作组关系等,方便地对作业进行自动调度、运行和管理。
调度监管平台可以图形方式动态监视和控制作业的运行,对作业执行中出现的错误/警告提供详细的信息。
- ETL脚本封装
GSQL是执行SQL的工具,但是与调度软件之间的结合还有一定的功能缺失,如参数解析,日志解析,异常处理等,所以需要对GSQL进行必要的封装,提高和调度软件之间的契合度。
- gsql模板
对加工处理的etl过程进行抽象,总结,形成算法模板。
指定必要的输入参数,设定会话启动的公共参数,为后续的优化和跟踪埋点打桩。
- 调用形式
调度工具->Python或其他脚本工具模板->GSQL->{.gsql}
4.2 GSQL封装
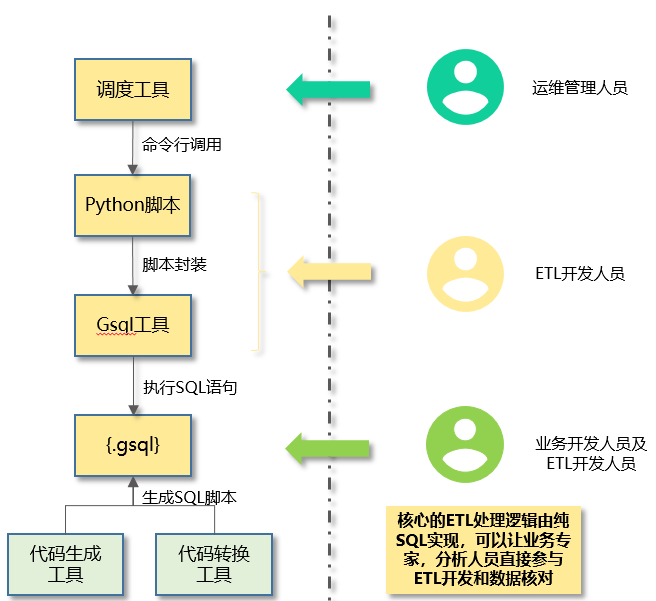
图4 GSQL封装示意图
增加封装的必要性:
GSQL和调度软件解耦:调度软件都具备调用Python/Perl/Shell脚本的能力,通过脚本封装,把GSQL和调度软件解耦,降低GSQL和调度软件的适配兼容性风险;
封装模板需要考量的功能点:
- 调度命令到GSQL运行命令的转换:
调度命令相对简单,和业务逻辑相关:如业务子系统代码,算法模板代码,数据日期等;
GSQL的运行参数不需要或不应当暴露在调度系统接口下:如登录密码,verbose参数等级等与业务无关的或者为了便于运维,性能跟踪的额外参数;
- 登录密码加密解密:
GSQL登录密码不允许明文存储,需要密文方式保存在ETL服务器上,执行时候也需要避免出现在后台命令行中被ps指令查看到;
- 异常处理:
GSQL脚本运行出错后的异常处理功能:如重跑,告警通知等;
- 运行日志解析:
GSQL的运行日志解析:针对GSQL脚本中不同语句,不同事务的执行时间解析跟踪,错误,告警代码的解析跟踪,为性能分析提供最详细的底层数据;
五、小结
本文对数据仓库构建ETL子系统进行了初步介绍,说明了当前较为主流的两种ETL子系统实现架构,比对MPPDB数据库的ETL架构进行了对比说明。最后对GaussDB(DWS)下的ETL子系统的实现要点进行了梳理,重点对etl实现的逻辑视图以及GSQL封装的功能要点进行了阐述。在今后的篇章,作者会对gsql的具体封装实现的最佳实践做个更为详细的介绍。
本文分享自华为云社区《给强大的“心脏”配上“超级流水线”- GaussDB(DWS)数据仓库平台ETL系统建设方案》,原文作者: babu1801 。
数仓ETL系统:给强大的“心脏”配上“超级流水线”的更多相关文章
- 吉特仓库管理系统-.NET4.0环境安装不上问题解决
在给客户实施软件的过程中要,要安装.NET 4.0 环境,而且是在XP的系统上. 目前的客户中仍然有大量使用XP的机器,而且极为不稳定,在安装吉特仓库管理系统客户端的时候出现了如下问题: 产品: Mi ...
- 设计和开发ETL系统(一)——ETL过程综述
在这部分将按照设计和实现ETL系统的流程展开,将上一个部分的那些子系统按照提取数据.清洗和一致化.向呈现服务器提交以及管理ETL环境等四个方面进行了分类.(是不是说对ETL主要就是掌握这四个方面的内容 ...
- ETL数仓测试
前言 datalake架构 离线数据 ODS -> DW -> DM https://www.jianshu.com/p/72e395d8cb33 https://www.cnblogs. ...
- 传统 BI 如何转大数据数仓
前几天建了一个数据仓库方向的小群,收集了大家的一些问题,其中有个问题,一哥很想去谈一谈--现在做传统数仓,如何快速转到大数据数据呢?其实一哥知道的很多同事都是从传统数据仓库转到大数据的,今天就结合身边 ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
- HAWQ取代传统数仓实践(十九)——OLAP
一.OLAP简介 1. 概念 OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理.此概念最早由关系数据库之父E.F.Codd于1993年提出.OLAP允 ...
- HAWQ取代传统数仓实践(十六)——事实表技术之迟到的事实
一.迟到的事实简介 数据仓库通常建立于一种理想的假设情况下,这就是数据仓库的度量(事实记录)与度量的环境(维度记录)同时出现在数据仓库中.当同时拥有事实记录和正确的当前维度行时,就能够从容地首先维护维 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Hive篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Spark篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- 数仓day01
1. 该项目适用哪些行业? 主营业务在线上进行的一些公司,比如外卖公司,各类app(比如:下厨房,头条,安居客,斗鱼,每日优鲜,淘宝网等等) 这类公司通常要针对用户的线上访问行为.消费行为.业务操作行 ...
随机推荐
- Linux下的网络输入输出流量的带宽控制(2015-11-23更新)
Linux下的网络输入输出流量的带宽控制 整理者:赤子玄心 QQ:280604597 Email:280604597@qq.com 大家有什么不明白的地方,或者想要详细了解的地方可以联系我,我会认真回 ...
- C、C++函数和类库详解(GCC版)(2014-4-23更新)
C.C++函数和类库详解(GCC版)(未完成) 整理者:高压锅 QQ:280604597 Email:280604597@qq.com 大家有什么不明白的地方,或者想要详细了解的地方可以联系我,我会认 ...
- ACL 与NAT
ACL 概述 acl是由一系列permit或deny语句组成.有序规则的列表. ACL是一个匹配工具,能够对报文进行匹配和区分. 应用 匹配流量 在traffic-filter中备调用 在NAT中被调 ...
- 联想think服务器centos系统安装
一.前言 本以为安装服务器是一件轻松顺利的事,没想到一安就是两天- 二.错误列表 1.硬件系统不兼容低版本centos 刚开始安装centos6.8的操作系统总是无法找到配置好的raid阵列导致无法安 ...
- 解决使用mitmprox抓包可以访问网页,但是使用python request 调用该网站接口报错问题
可能有几种原因导致这种情况.以下是一些常见的问题和可能的解决方法: 证书验证问题: 当你使用mitmproxy抓包时,它通常会生成自签名的SSL证书,以便进行中间人攻击检查.但在Python中使用re ...
- Java 基础学习第一弹
1. equels和==的区别 equals方法用于比较对象的内容是否相等,可以根据自定义的逻辑来定义相等的条件,而==操作符用于比较对象的引用是否相等,即它们是否指向同一块内存地址.equals方法 ...
- 浅析SpringBoot加载配置的6种方式
从配置文件中获取属性应该是SpringBoot开发中最为常用的功能之一,但就是这么常用的功能,仍然有很多开发者抓狂-今天带大家简单回顾一下这六种的使用方式: 说明 Environment对象 Envi ...
- 在VM虚拟机中安装FTP服务
自用的话,建议先关掉防火墙 systemctl stop firewalld #关闭防火墙 systemctl disable firewalld.service #设置开机禁用防火墙 systemc ...
- java读取照片Exif信息到实体类
前言 1.总共读出来了228个参数信息,但是我挑选了36个我认为比较有价值的参数,弄成了实体类 (其实是因为很多参数我看不明白是啥意思) 2.为了方便,所以实体类里我直接用中文字段了 效果图 导入依赖 ...
- 仅需三行代码! C# 快速实现PDF转PPT
一般在会议.教学或培训活动中,我们都会选择PPT文档来进行内容展示.与PDF文档相比,PPT文档具有较强的可编辑性,可以随时增删元素,并且还可以设置丰富多样的动画效果来吸引观众注意.那么如何通过C#将 ...