带你掌握数仓的作业级监控TopSQL
摘要:目前TopSQL功能被用户广泛使用,是性能定位、劣化分析、审计回溯等重要的基石,为用户提供覆盖内存、耗时、IO、网络、空间等多方面的监控能力。
本文分享自华为云社区《GaussDB(DWS)监控工具指南(一)作业级监控TopSQL》,作者:幕后小黑爪 。
1、引言:
监控系统是智能化管理和自动化运维的基石,可以为资源规划,故障排查,性能优化提供至关重要的数据支持。GaussDB(DWS)作为企业级数仓,为用户提供了一整套覆盖实例级、用户级、作业级的资源监控能力,其中,作业级监控(下文统称为TopSQL)主要是对运行作业的监控,包括了实时运行作业的相关信息,历史运行作业的相关信息等。它收集的数据来源于数据库内部,为用户提供了实时监控数据库的能力。
目前TopSQL功能被用户广泛使用,是性能定位、劣化分析、审计回溯等重要的基石,为用户提供覆盖内存、耗时、IO、网络、空间等多方面的监控能力。
本文以数仓813版本作为基线,对TopSQL进行介绍。
2、TopSQL功能介绍
对于用户而言,数据库是个黑盒,输入SQL语句,输出预期结果。在此过程中,用户关心两点:
- 输出结果是否符合预期;
- 语句要多久跑完。
关于第一个问题,用户需要关注下SQL语句写的是否合理。而对于第二个问题,普通用户可以通过explain等手段分析作业的执行计划,然而企业用户的SQL作业耗时久,影响较大,重跑代价较高,无法额外通过explain performance等手段进行分析,此时TopSQL可以帮助用户打开数据库黑盒,查看作业执行的实时情况和历史情况,便于用户分析数据库的情况。
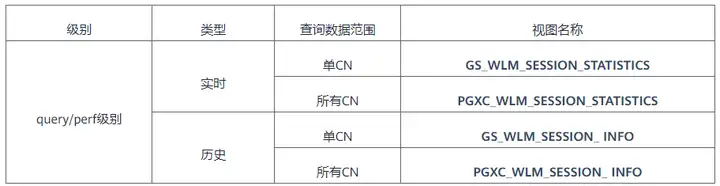
TopSQL功能主要通过视图进行承载,如下表所示,本文以query级别的视图为例进行说明。
使用TopSQL功能需要sysadmin权限。此外,用户需先检查下TopSQL功能是否开启,涉及TopSQL的数据库GUC参数包括:
- ENABLE_RESOURCE_TRACK (ON)
是否开启监控功能,实时TopSQL的总开关,关闭之后实时TopSQL将不再进行记录,更不会在历史TopSQL中出现。
- RESOURCE_TRACK_COST(0)
设置对当前会话的语句进行资源监控的最小执行代价。
- RESOURCE_TRACK_LEVEL(QUERY)
设置当前会话的资源监控的等级,默认为query级别。
- RESOURCE_TRACK_DURATION(60S)
设置实时TopSQL中记录的语句执行结束后进行历史信息转存的最小执行时间。当执行完成的作业,其执行时间不小于此参数值时,作业信息会从实时视图(以STATISTICS为后缀的视图)转存到相应的历史视图
- ENABLE_RESOURCE_RECORD(ON)
设置是否开启资源监控记录归档功能。开启时,对于执行结束的记录,会分别被归档到相应的INFO视图,CN和DN都需要设置上。
- TOPSQL_RETENTION_TIME(30)
设置历史TopSQL中GS_WLM_SESSION_INFO和GS_WLM_OPERATOR_INFO表中数据的保存时间,单位为天。
参数正确设置后,TopSQL会记录用户的SQL语句执行过程中的相关信息,用户可以使用TopSQL的视图筛选出执行时间较长的作业,专注于慢SQL的分析。
TopSQL功能分为实时TopSQL和历史TopSQL,以query级别为例,当需要查看正在运行的作业时,用户可查看实时TopSQL视图GS_WLM_SESSION_STATISTICS和PGXC_WLM_SESSION_STATISTICS,若需要对已经执行完成的作业进行分析,可查询历史TopSQL视图GS_WLM_SESSION_ HISTORY和PGXC_WLM_SESSION_ HISTORY。其中GS_开头的可以查询当前CN节点上正在执行的作业信息,PGXC_开头的可查询所有CN节点上正在执行的作业信息。
实时TopSQL视图为用户记录了作业运行时的相关信息,比如作业下发来源、阻塞时间、执行时长、开始时间、内存消耗、作业下盘量、作业IO、网络、语句类型、语句的执行计划等信息。用户可先通过resource_pool、nodename、username、query等信息定位到自己需要分析的语句,再通过作业运行信息定位问题。又或者用户可通过对查询进行筛选,筛选出当前占用资源较多的作业。
历史TopSQL视图记录了作业运行结束时的资源使用情况(包括内存、下盘、CPU时间等)和运行状态信息(包括报错、终止、异常等)以及性能告警信息。用户可通过对历史语句运行数据的分析,筛选出执行时长较大的语句,看语句执行计划是否有优化的空间,是否需要对表做一些analyze或者vacuum之类的操作。又比如对于内存报错的情况,可分析内存占用高的语句是否合理,从执行计划上分析是否有优化空间。
文末附TopSQL实践:常见问题现象及对应原因。
3、TopSQL的原理解析
3.1 TopSQL原理简介:
TopSQL的数据来源于数据库内核,当语句执行时,TopSQL会实时记录语句执行的相关信息。实时TopSQL数据会保存在内存的临时表中,当语句执行结束后,数据会转存到对应实体表GS_WLM_SESSION_INFO中,在实际使用中,由于下发作业繁多,历史TopSQL记录的作业数也不断增长,这样会导致INFO表中的数据量逐渐庞大,为了确保数仓整体性能不受影响,支持通过TOPSQL_RETENTION_TIME来设置INFO表中数据的保存时间(单位为天)。当数据存留时长超过这个时限,会对实体表GS_WLM_SESSION_INFO进行数据老化删除处理。

图 3-1 TopSQL数据流通图
如图3-1所示,各项GUC参数决定了TopSQL生成的记录信息,具体的参数说明详见第2节使用TopSQL前的检验。
3.2 性能分析:
对于企业用户而言,性能问题是Top级问题,对于TopSQL功能,我们进行了性能压测,在4TB的场景下,进行TPCC基准性能测试,进行了2000的并发压测,TPMC下降了约有2%,属于可接受的范围。
3.3 相关指标
语句属性列说明:
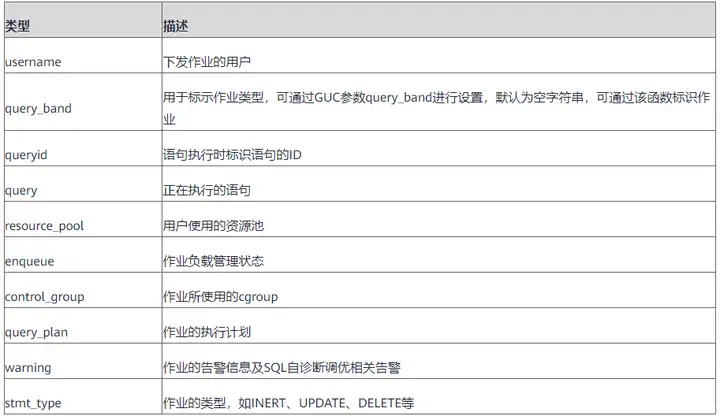
语句的执行信息属性列,斜体代表可更换前缀/后缀式的指标,类似前缀后缀有(min_,max_,total_,average_,_skew_percent)
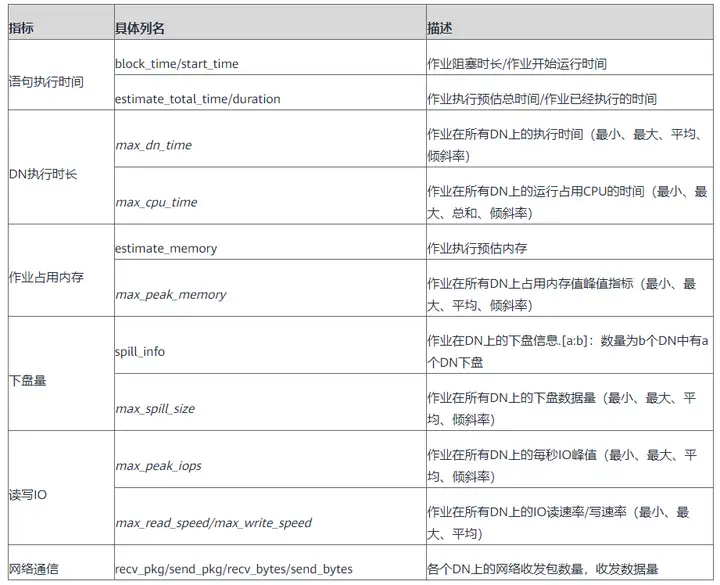
3.4 特殊情况说明:
TopSQL由于自身限制,存在一些记录异常的情况,此处对8.1.3版本的TopSQL语句记录情况进行说明:
- 不记录特殊数据定义语句,如:SET、RESET、SHOW、ALTER SESSION SET、SET CONSTRAINTS语句;
- 记录数据定义语句,例如:执行CREATE、ALTER、DROP、GRANT、REVOKE和VACUUM语句;
- 记录数据操作语句,例如:
- 执行SELECT、INSERT、UPDATE和DELETE语句。
- 执行explain analyze和explain performance场景。
- 执行查询query级别/perf级别视图
- ODBC下发作业,由于多语句原因,会记录事务的BEGIN和end语句;
- JDBC下发作业,随机性多记录一条JDBC的内部语句
- 解析错误和语法报错的异常不记录
- 用户手动CANCEL作业,显示的监控数据可能为0;
- 当子语句开关打开后,只会记录下发到DN上执行的子语句;
- 游标语句,当游标并非从缓存中读取数据,而确实触发语句下发到DN上执行的条件下,该游标语句会被记录,并且会进行语句、执行计划增强,但当游标从缓存中读取数据时,不进行记录;当游标语句在匿名块或者函数中使用时,当游标从DN上读取较多数据但不完全使用时,无法记录该游标在DN上的监控信息。
- JDBC执行的带占位符语句,通常会补齐参数内容,但如果参数和原语句合起来长度超过64KB,则不记录参数,或者如果是轻量化语句,直接下发到DN上执行,不记录参数。
4、TopSQL扩展及应用
TopSQL功能是GaussDB(DWS)支持性能问题定位、语句劣化分析、审计回溯等重要功能的基石。在此基础上,内核也拓展出了异常规则等一些高阶用法,在日常使用中,用户也对TopSQL提出了更高的要求,比如记录子语句、记录语句类型、提升算子级别语句监控准确性等诸多建议。为此,GaussDB(DWS)团队会在此基础上继续演进,更好的服务用户,提升用户满意度。
5、TopSQL实践:常见问题定位
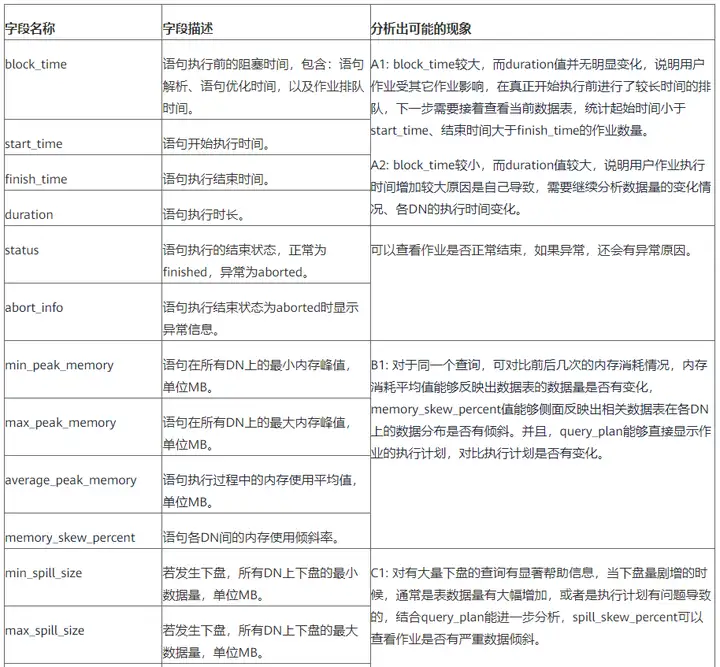
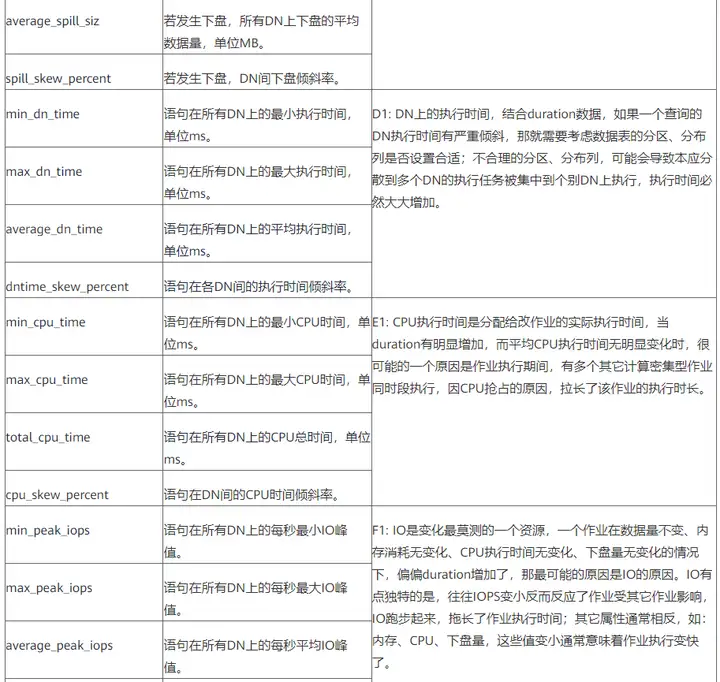

总结一下:
- 因数据量变化,导致作业执行时间增加,可以分析A2/B1/D1/G1,进而确认作业查询的数据表是否有明显的数据量增加;
- 因其它并发作业抢占,导致作业排队,从而导致作业执行时间增加,可以分析A1/B1/D1,进而查看作业执行的同时期是否有大量并发作业在执行;
- 因其它作业而产生的CPU抢占,导致作业执行时间增加,可以分析A2/D1/E1,进而查看作业执行的同时期是否有大量并发作业在执行;
- 因其它作业而产生的IO抢占,导致作业执行时间增加,可以分析A2/F1,进而查看作业执行的同时期是否有大量并发作业在执行;
- I1中有结果情况,可通过提示的信息进行分析,或者进行SQL自适应诊断相关告警处理,SQL自适应诊断处理方法见:https://support.huaweicloud.com/performance-dws/dws_10_0013.html
- 对于enqueue异常排队的情况H1,用户可参考:GaussDB(DWS)资源管理排队原理与问题定位-云社区-华为云 (huaweicloud.com),进行问题排查分析。
值得注意的是,发生资源争抢时,可能会出现并发症,即CPU、IO抢占,作业排队现象都会发生,针对并发症问题,可以逐步分析解决,比如:
第一步,调整作业执行顺序,减少并发作业数量,减少阻塞时间;
第二步,定位出同时段执行的典型计算密集型、存储密集型作业,先移动到其它时间段执行,减少对本作业的影响;
第三步,在无其他作业明显干预的情况下,做进一步分析,
6、参考文献:
- GaussDB for DWS 负载管理核心技术解密二: 白话历史资源监视-云社区-华为云 (huaweicloud.com)
- GaussDB(DWS)资源管理排队原理与问题定位-云社区-华为云 (huaweicloud.com)
带你掌握数仓的作业级监控TopSQL的更多相关文章
- 【云+社区极客说】新一代大数据技术:构建PB级云端数仓实践
本文来自腾讯云技术沙龙,本次沙龙主题为构建PB级云端数仓实践 在现代社会中,随着4G和光纤网络的普及.智能终端更清晰的摄像头和更灵敏的传感器.物联网设备入网等等而产生的数据,导致了PB级储存的需求加大 ...
- HAWQ取代传统数仓实践(十九)——OLAP
一.OLAP简介 1. 概念 OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理.此概念最早由关系数据库之父E.F.Codd于1993年提出.OLAP允 ...
- 看SparkSql如何支撑企业数仓
企业级数仓架构设计与选型的时候需要从开发的便利性.生态.解耦程度.性能. 安全这几个纬度思考.本文作者:惊帆 来自于数据平台 EMR 团队 前言 Apache Hive 经过多年的发展,目前基本已经成 ...
- HAWQ取代传统数仓实践(十六)——事实表技术之迟到的事实
一.迟到的事实简介 数据仓库通常建立于一种理想的假设情况下,这就是数据仓库的度量(事实记录)与度量的环境(维度记录)同时出现在数据仓库中.当同时拥有事实记录和正确的当前维度行时,就能够从容地首先维护维 ...
- HAWQ取代传统数仓实践(十三)——事实表技术之周期快照
一.周期快照简介 周期快照事实表中的每行汇总了发生在某一标准周期,如一天.一周或一月的多个度量.其粒度是周期性的时间段,而不是单个事务.周期快照事实表通常包含许多数据的总计,因为任何与事实表时间范围一 ...
- CarbonData:大数据融合数仓新一代引擎
[摘要] CarbonData将存储和计算逻辑分离,通过索引技术让存储和计算物理上更接近,提升CPU和IO效率,实现超高性能的大数据分析.以CarbonData为融合数仓的大数据解决方案,为金融转型打 ...
- 基于Hive进行数仓建设的资源元数据信息统计:Hive篇
在数据仓库建设中,元数据管理是非常重要的环节之一.根据Kimball的数据仓库理论,可以将元数据分为这三类: 技术元数据,如表的存储结构结构.文件的路径 业务元数据,如血缘关系.业务的归属 过程元数据 ...
- 传统 BI 如何转大数据数仓
前几天建了一个数据仓库方向的小群,收集了大家的一些问题,其中有个问题,一哥很想去谈一谈--现在做传统数仓,如何快速转到大数据数据呢?其实一哥知道的很多同事都是从传统数据仓库转到大数据的,今天就结合身边 ...
- ETL数仓测试
前言 datalake架构 离线数据 ODS -> DW -> DM https://www.jianshu.com/p/72e395d8cb33 https://www.cnblogs. ...
- 数仓day02
1. 什么是ETL,ETL都是怎么实现的? ETL中文全称为:抽取.转换.加载 extract transform load ETL是传数仓开发中的一个重要环节.它指的是,ETL负责将分布的. ...
随机推荐
- gson如何序列化子类
需求 目前有一个需求,不同对象有一些公共属性,分别也有一些不同的属性.对方传过来的json字符串中,把这些对象组成了一个数组返回过来的.这样该如何反序列化呢? 举例 定义Person类.Student ...
- Godot引擎的一些踩坑记录(不断更新中)
版本号 Godot 3.1.2 文件夹名称使用小写.编译\导出时有的tscn文件的引用路径, 有可能会变成小写路径(怀疑是bug),导致启动失败. ttc字体(文泉驿微米黑)导出时需要手动设置包含*. ...
- 数据结构-线性表-双向链表(c++)
与单循环链表类似,但析构函数需要注意 析构函数: 因为while循环的条件是p->next!=front,所以不能直接delete front: template<class T> ...
- InfiniBand 的前世今生
今年,以 ChatGPT 为代表的 AI 大模型强势崛起,而 ChatGPT 所使用的网络,正是 InfiniBand,这也让 InfiniBand 大火了起来.那么,到底什么是 InfiniBand ...
- 栈与队列应用:逆波兰计算器(逆波兰表达式;后缀表达式)把运算符放到运算量后边 && 中缀表达式转化为后缀表达式
1 //1.实现对逆波兰输入的表达式进行计算如(2-1)*(2+3)= 5 就输入2 1 - 2 3 + * //先把2 1 压栈 遇到-弹栈 再把2 3压进去 遇到+弹栈 最后遇到*弹栈 2 //2 ...
- LabVIEW基于机器视觉的实验室设备管理系统(5)
目录 行动计划 设备借用 判断设备ID是否正确.设备是否在库 判断是否为已注册用户.电话是否正确 借出设备 设备归还 信息查询 判断ID是否正确.选择设备状态 效果演示 今天这一期,我们就来完成实验 ...
- H.264 和 H.265对比
前言 H.264标准正式发布于2003年3月,距今已经20多年了,但它仍然是当下最流行的视频编解码标准. H.265正式发布于2013年4月.虽然H.265标准是围绕着H.264进行制定的,也保留了原 ...
- 神经网络入门篇:详解随机初始化(Random+Initialization)
当训练神经网络时,权重随机初始化是很重要的.对于逻辑回归,把权重初始化为0当然也是可以的.但是对于一个神经网络,如果把权重或者参数都初始化为0,那么梯度下降将不会起作用. 来看看这是为什么. 有两个输 ...
- linux-ELK安装配置
前言: ELK 是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch.Logstash 和 Kibana. • Elasticsearch 是一个搜索和分析引擎. ...
- uniapp---wap2app去掉系统自带的导航栏
在用uniapp进行将wap站转化为app的时候,默认打包后的文件,带有系统的导航栏,下面是去除的办法: 第一步:找到 sitemap.json 设置 titleNView为false: 第二步:在 ...