locust+python性能测试库
一.简介
locust官网介绍:Locust 是一个用于 HTTP 和其他协议的开源性能/负载测试工具。其对开发人员友好的方法允许您在常规 Python 代码中定义测试。Locust测试可以从命令行运行,也可以使用其基于 Web 的 UI 运行。可以实时查看吞吐量、响应时间和错误和/或导出以供以后分析。
二.环境搭建
1.python 3.7.4
2.Locust 2.17(终端可使用pip安装:pip install locust)
三.基本用法
1.我们先来看下一个简单的实例
from locust import TaskSet, between, task, HttpUser
class api(TaskSet):
@task(1)
def on_one(self):
data = self.client.post(url="https:.......", json={
"username", "",
"password", ""
})
print(data.json())
@task(2)
def index(self):
data = self.client.get("https:..........")
print(data.json())
def on_stop(self):
print("运行结束")
def on_start(self):
print("初始化")
class UserRun(HttpUser):
tasks = [api]
wait_time = between(1, 5) # 默认等待时间0s
1)使用locust导入了四个类
Taskset:上例中api继承了该类,主要编写一些接口请求信息,client.get(),client.post()表get和post请求。
between:设置每个任务直接等待的间隔,单位为s,例:between(1,5)每个任务直接等待1-5s再去运行。出来between,还有constant可设置固定等待时间,例:constant(5)。
task:设置用例权重,数字越大,权重越大,默认为1。
httpuser:定义一个用户的基类,相当于运行类,通过tasks列表来运行我们想要的api。这里写法有两种(例1:tasks=[api1,api2],集合形式,会随机选取一个执行的任务,选取的概率相同。例2:tasks = {api1: 15, api2: 1},字典的形式,数字代表权重,会随机选取一个执行的任务,数字越大,被执行的概率越大)。
class UserRun(HttpUser):
# tasks = [api]
tasks = {api: 15, api_one: 1}
wait_time = between(2, 3)
2)上面可以看到api类中有on_start()和on_stop()两个方法,可用来初始化和结束操作
2.那么前置条件都准备好了,接下来就是如何运行了
1)在终端执行:locust -f python_file_name.py

执行后会得到一个http链接,默认ip应该是0.0.0.0。复制url到浏览器打开,如果无法打开的话,就在venv\Lib\site-packages\locust\argument_parser.py下修改默认ip即可。

再次运行会得到http://127.0.0.1:8089的地址,浏览器就可以正常打开了。
四.web-ui页面
1.通过上面再浏览器输入地址后会打开web-ui界面
Number of users (peak concurrency):总共的用户数
Spawn rate (users started/second):每秒启动的用户数
2.收集界面
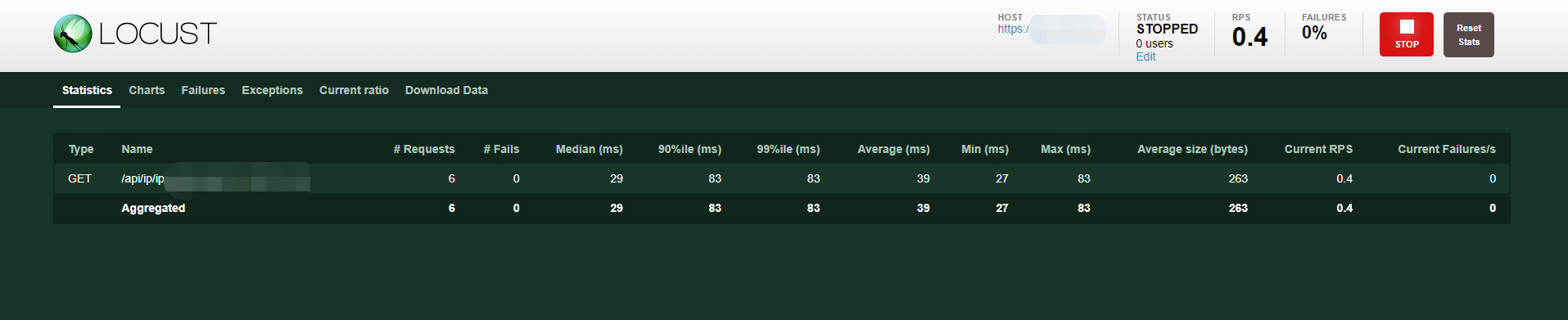
1)功能按钮
stop:停止运行
Reset Stats:重置指标统计
2)tab项
Statistics:收集的各个指标数据
Charts:数据曲线图
Failures:请求失败的数据
Exceptions:异常请求的数据
Current ratio:每个任务的比例
Download Data:下载数据csv格式(各项指标,错误数据,异常数据.....)
3)Statistics下各指标
type:请求类型
name:请求url
requests:实际请求数
fails:失败数
median(ms):响应时间的中间值
90%ile(ms):90%响应时间
99%ile(ms):99%响应时间
average(ms):平均响应时间
min(ms):最小响应时间
max(ms):最大响应时间
average size(bytes):平均请求的大小
current rps:当前每秒处理事务的次数
current failures/s:当前每秒的失败数
4)Charts数据标
Total Requests per Second曲线图:
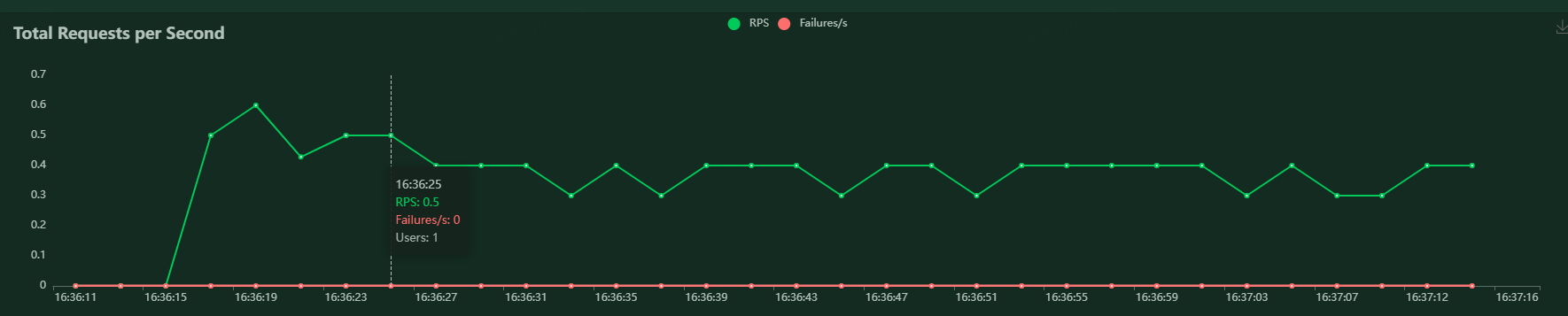
RPS:每秒请求的次数
Pailures/s:每秒失败次数
Response Times(ms)曲线图:
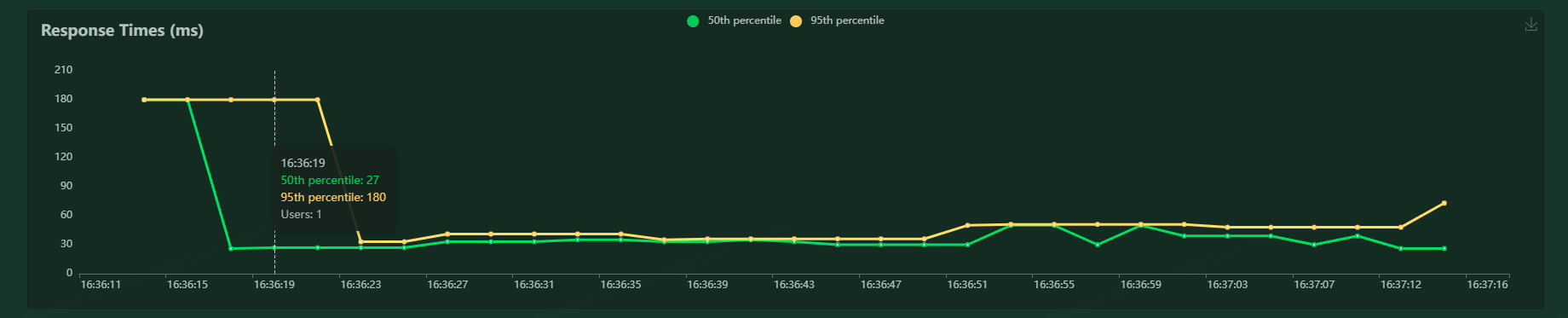
50th percentile:50%响应时间
95th percentile:95%响应时间
Number of Users曲线图:

当前时间请求的用户数
五.无ui模式
1)终端直接输入指令
locust -f python_file_name.py --headless --users 1 --spawn-rate 1 --host https://......
--headless:表示无ui模式
--users:总共用户数
--spawn-rate:表示每秒有多少个用户请求
--host:收集接口性能的域名
2)收集结果(终端会持续收集,ctrl+c结束)

六.各个参数介绍
| -h | 查看帮助 |
| -f | 指定运行文件 |
| -h | 指定域名 |
| -u | 并发用户数,和--headless一起用 |
| -r | 每秒增加多少个用户请求,和--headless一起用 |
| -t | 设置运行的时间,不填默认永久 |
| -l | 显示可能的用户类列表并退出 |
| --web-host | 将 Web 界面绑定到的主机。默认为“*” |
| --web-port | 端口,默认8089 |
| --headless | 无ui模式 |
| --autostart | 立即开始测试(如 --headless,但不禁用 Web UI) |
| --autoquit | 在运行 X 秒后完全退出。仅与 --autostart 一起使用 |
| --web-auth | Web 界面启用基本身份验证。应该是以下格式提供:用户名:密码 |
| --master | 将 locust 设置为在分布式模式下运行,并使用此进程作为主进程 |
| --worker | 将 locust 设置为在分布式模式下运行,并使用此 进程作为工作线程 |
| --master-host | 分布式locust的主机或IP地址负载测试。仅在使用 --worker 运行时使用。 默认值为 127.0.0.1。 |
| -T | 要包含在测试中的标记列表,因此仅包含任务与任何匹配的标签将被执行 |
| -E | 要从测试中排除的标签列表,因此仅任务没有匹配的标签将被执行 |
| --skip-log-setup | 禁用 Locust 的日志记录设置。取而代之的是,配置由 Locust 测试或 Python 提供 |
| --loglevel |
日志等级,在 DEBUG/INFO/WARNING/ERROR/CRITICAL 之间进行选择。默认值为 INFO。 |
| --logfile |
日志文件的路径。如果未设置,日志将转到 stderr |
| --show-task-ratio | 打印用户类的任务执行比率表。如果某些类定义非零fixed_count属性。 |
| --version | 查看版本 |
| --exit-code-on-error |
设置测试结果时要使用的进程退出代码包含任何故障或错误 |
| ----config | 配置文件路径 |
七.分布式运行
1.单台电脑运行(cpu核数)
1)单台电脑主要使用cpu核数来实现分布式运行的,打开任务管理器》性能》CPU》内核 查看
2)分布式运行存在主从关系,即:master》主,slave》从。
3)编辑好脚本后再终端运行主机(主机主要负责分发任务,具体执行还是从机)
locust -f Locusted.py --master
4)再开多个终端运行从机(运行的从机个数要小于等于cpu内核数)
locust -f Locusted.py --worker

5)运行问多个从机后,再回到主机的终端,可以看见启动的cpu内核数

6)此时浏览器访问http://127.0.0.1:8089可以看见启动的从机数

2.多台电脑
若一台设备不注意满足条件时,可以多台设置同时模拟请求,方法和上面的大致相同,先启动主机
locust -f Locusted.py --master
再在其它设置上运行从机(从机环境和主机一致)
locust -f Locusted.py --worker --master-host=ip地址
八.负载测试
1.自定义时间生成负载峰值或上升和下降
LoadTestShape自定义荷载形状的基类,做负载,首先先继承该类。
from locust import TaskSet, between, task, HttpUser, LoadTestShape, constant
class api_one(TaskSet):
@task
def on_one(self):
data = self.client.post(url="/api/teladress?mobile=15161581519", name="测试")
print(data.json())
class MyCustomShape(LoadTestShape):
time_limit = 60 # 设置负载总运行时长
spawn_rate = 2 # 更改用户数时每秒启动/停止的用户数
def tick(self):
run_time = self.get_run_time() # 负载测试的运行时间
if run_time < self.time_limit:
user_count = round(run_time, -1) # 当前共增加的用户(当前用户总数)
return (user_count, self.spawn_rate)
return None
class UserRun(HttpUser):
tasks = [api_one]
host = "https://api.oioweb.cn"
# tasks = {api: 15, api_one: 1}
wait_time = constant(1)
以上负载测试总共运行60s,每10s增加10个用户,10个用户再5s内增加完成。这里直接介绍tick()方法了,Locust 大约每秒调用一次 tick() 方法。user_count = round(run_time, -1),run_time为当前负载的测试时间,-1表示将run_time四舍五入到最接近的十位数,round(run_time, -1)的取值规则即:0-4.999为0,5-14.999为10,15-24.999为20,依次类推,每十秒增加10个用户。若-1改成-2,即四舍五入到最接近的百位数,每100s增加100个用户。
2.某时间段设置负载峰值上升或下降
from locust import TaskSet, between, task, HttpUser, LoadTestShape, constant
class api_one(TaskSet):
@task
def on_one(self):
data = self.client.post(url="/api/teladress?mobile=15161581519", name="测试")
print(data.json())
class StagesShapeWithCustomUsers(LoadTestShape): # 自定义荷载形状的基类。
# duration:负载的时长,users:用户总数,spawn_rate:每秒启动的用户数
# 0-10s,1s启动10个用户。10-20s,5s启动50个用户,依次类推
stages = [
{"duration": 10, "users": 10, "spawn_rate": 10},
{"duration": 20, "users": 50, "spawn_rate": 10},
{"duration": 30, "users": 100, "spawn_rate": 10},
{"duration": 40, "users": 50, "spawn_rate": 10},
{"duration": 60, "users": 10, "spawn_rate": 10},
]
def tick(self):
run_time = self.get_run_time() # 获取负载当前时间
for stage in self.stages:
if run_time < stage["duration"]:
tick_data = (stage["users"], stage["spawn_rate"])
return None
class UserRun(HttpUser):
tasks = [api_one]
host = "https://api.oioweb.cn"
# tasks = {api: 15, api_one: 1}
wait_time = constant(1)
运行结果如下
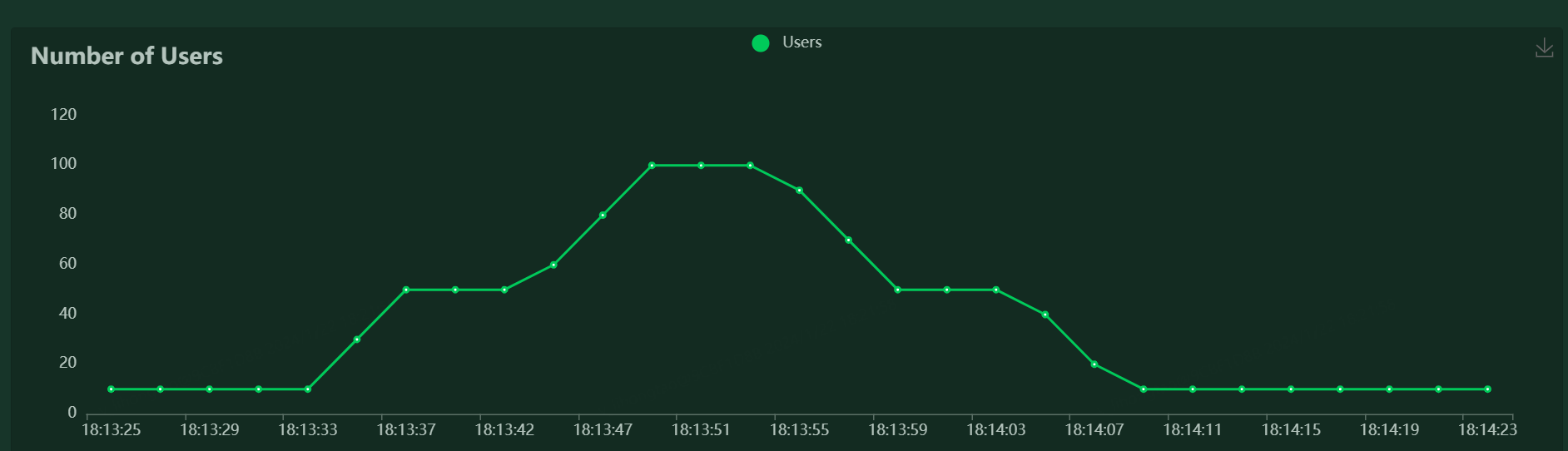
九.其它
具体api使用可参考官网:https://docs.locust.io/en/stable/api.html
文章来源:https://www.cnblogs.com/lihongtaoya/ ,请勿转载
locust+python性能测试库的更多相关文章
- python常用库
本文由 伯乐在线 - 艾凌风 翻译,Namco 校稿.未经许可,禁止转载!英文出处:vinta.欢迎加入翻译组. Awesome Python ,这又是一个 Awesome XXX 系列的资源整理,由 ...
- Python常用库大全
环境管理 管理 Python 版本和环境的工具 p – 非常简单的交互式 python 版本管理工具. pyenv – 简单的 Python 版本管理工具. Vex – 可以在虚拟环境中执行命令. v ...
- python的库小全
环境管理 管理 Python 版本和环境的工具 p – 非常简单的交互式 python 版本管理工具. pyenv – 简单的 Python 版本管理工具. Vex – 可以在虚拟环境中执行命令. v ...
- python 三方库
---------------- 这又是一个 Awesome XXX 系列的资源整理,由 vinta 发起和维护.内容包括:Web框架.网络爬虫.网络内容提取.模板引擎.数据库.数据可视化.图片处理. ...
- python第三方库,你要的这里都有
Python的第三方库多的超出我的想象. python 第三方模块 转 https://github.com/masterpy/zwpy_lst Chardet,字符编码探测器,可以自动检测文本. ...
- Python常用库大全,看看有没有你需要的
作者:史豹链接:https://www.zhihu.com/question/20501628/answer/223340838来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- python常用库(转)
转自http://www.west999.com/info/html/wangluobiancheng/qita/20180729/4410114.html Python常用的库简单介绍一下 fuzz ...
- Python第三方库资源
[转载]Python第三方库资源 转自:https://weibo.com/ttarticle/p/show?id=2309404129469920071093 参考:https://github ...
- 【转载】Python第三方库资源
转自:https://weibo.com/ttarticle/p/show?id=2309404129469920071093 参考:https://github.com/jobbole/awesom ...
- Python全部库整理
库名称简介 Chardet字符编码探测器,可以自动检测文本.网页.xml的编码. colorama主要用来给文本添加各种颜色,并且非常简单易用. Prettytable主要用于在终端或浏览器端构建格式 ...
随机推荐
- 应对全场景AI框架部署挑战,MindSpore“四招”让你躺平
摘要:所谓全场景AI,是指可以将深度学习技术快速应用在云边端不同场景下的硬件设备上,包括云服务器.移动终端以及IoT设备等等,高效运行并能有效协同. 本文分享自华为云社区<AI框架的挑战与Min ...
- 不知如何优选达人?火山引擎 VeDI 零售行业解决方案一键解决!
技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 "人-货匹配"这句营销老话,在直播电商兴起的这几年,似乎不再专指消费者与商品之间的关系. 过去 ...
- Java 17 从 Solon 开始入手,v1.10.0
相对于 Spring Boot 和 Spring Cloud 的项目: 启动快 5 - 10 倍. (更快) qps 高 2- 3 倍. (更高) 运行时内存节省 1/3 ~ 1/2. (更少) 打包 ...
- 接口文档 token发展史 jwt介绍和原理 drf-jwt快速使用
目录 昨日回顾 认证 权限 频率 全局异常处理 接口文档 接口文档编写 drf自动生成接口文档 cookies-session-token发展史 jwt介绍和原理 jwt的构成 base64的编码和解 ...
- Function--jdk8用法
Lambda表达式.首先是参数部分,接着是->,可以视为产出,->之后的内容都是方法体. 当只有一个参数时,可以不需要括号(): 正常情况使用()包裹参数,为了保持一致性,也可以使用括号( ...
- ios-class-guard - iOS代码混淆与加固实践
目录 ios-class-guard - iOS代码混淆与加固实践 摘要 引言 一.class-dump 二.ios-class-guard 混淆原理 三.ios-class-guard 混淆结果 ...
- 4、SpringBoot连接数据库引入druid
系列导航 springBoot项目打jar包 1.springboot工程新建(单模块) 2.springboot创建多模块工程 3.springboot连接数据库 4.SpringBoot连接数据库 ...
- vue axiox网络请求
一.首先安装axios ,vue-axios 前提:搭建一个vue3的项目 项目搭建参考:https://www.cnblogs.com/yclh/p/15356171.html 使用npm安装axi ...
- scrollIntoView页面滑动特效
点击左侧的菜单,页面平滑滚动:
- windows10/liunx创建空大文件
1.windows10创建空大文件打开cmd命令,进入需要创建文件的目录,使用以下命令创建 fsutil file createnew test001.txt 1073741824 最后的数字代表文件 ...