总结篇4:redis 核心数据存储结构及核心业务模型实现应用场景
总结篇4:redis 核心数据存储结构及核心业务模型实现应用场景
redis 和memcached 有什么区别?为什么在高并发下,单线程的redis 比多线程的效率高?
- mc 可以缓存图片和视频,redis 支持除更多的数据结构。redis 典型的应用场景是用户订单列表,用户消息,帖子评论等。
- redis 可以使用虚拟内存,redis 可持久化和aof 灾难恢复,支持主从数据备份。如果redis 挂了,内存能够快速恢复热数据,不会将压力瞬间压在数据库上,没有cache 预热的过程。对于只读和数据一致性要求不高的场景可以采用持久化存储。
- redis 可以做消息队列。redis 支持集群,可以实现主动复制,读写分离,mc 如果想实现高可用,需要进行二次开发。
- mc 存储的vlaue 最大为1M。
选择mc 的场景:
- 1 纯kv, 数据量非常大的业务。
原因是: - 1 mc 的内存分配采用的是预分配内存池的管理方式,能够省去内存分配的时间。redis 是临时申请空间,可以导致碎片化
- 2 虚拟内存使用,mc 将所有的数据存储在物理内存里,redis 有自己的vm 机制,理论上能够存储比物理内在更多的数据,当数据超量时,引发swap, 把冷数据刷新到磁盘上。从这点上看,数据量大时,mc 更快
- 3 网络模型。mc 使用非阻塞的io 复用模型,redis 也是使用非阻塞的io 复用模型,但是redis 还提供了一些非kv 存储之外的排序,聚合功能,复杂的cpu 计算,会阻塞整个io 调度,从这点上由于redis 提供的功能较多,mc 更快一些。
- 4 线程模型,mc 使用多线程,主线程监听,worker 子线程接受请求,执行读写,这个过程可能存在锁冲突。redis 使用单线程,虽然无锁冲突,但是难以利用多核的特性提升吞吐量。
选择redis 场景:
- 1 存储方式上:mc 会把数据全部存储在内存中,断电后会挂掉,数据不能超过内存的大小。redis 有部分数据存在硬盘上,这样能保证数据持久性。
- 2 数据支持类型上:redis 支持更丰富的数据类型
- 3 使用底层模型不同:底层实现方式以及客户端之间通信的应用协议不同。redis 直接构建了vm 机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
- 4 value 大小。redis 可以达到1 G,而mc 只有1 M。
mc 多线程模型引入了缓存一致性和锁,加锁带来了性能损耗。为什么 redis 单线程还如此快?因为底层有高效数据存储结构。整个redis 存储结构是全局哈希表,哈希运算非常快,时间复杂度为常量。
redis 常见性能问题和解决方案
- 1 master 最好不要做持久化工作,如RDB 内存快照和AOF 日志文件
- 2 如果数据比较重要,某个slave 开启AOF 备份,策略设置成每秒同步一次
- 3 为了主从复制的速度和连接的稳定性,master 和slave 最好在一个局域网内
- 4 尽量避免在压力大得主库上增加从库
- 主从复制不要采用网状结构,尽量是线性结构。
redis set key value, 其中key 类型都是string 类型。五种基本类型都是对应的value。
String 应用场景
- 字符串常用操作
set key value // 存入字符串键值对
mset key value [key value] // 批量存储字符串键值对
- 单值缓存
1 set key value
2 get key
- 对象缓存
1 set user:1 value(json 格式数据)
2 mset user:1 name zhuge user:1:balance 888
mget user:1:name user:1:balance
- 分布式锁
setnx product:100001 true // 返回1 代表获取锁成功
setnx product:100001 true // 返回0代表获取锁失败
。。。执行业务操作
del product:100001 // 执行完业务释放锁
set product:100001 true ex 10 nx // 防止程序意外终止导致死锁
- 计数器
incr article:readcount:{文章id} // 文章点赞数
get article:readcount:{文章id}
- 分布式系统全局序列号
incrby orderid 100 、、 redis 批量生成序列号提升性能
一般我们设置数据库自增主键,并设置相应索引。如果数据量很大,分库分表时就实现不了。可以用缓存实现。为提升性能,我们可以优化,做一个批量内存的自增,比如一次生成100个。
hash 常用操作
优点:
- 同类数据归类整合储存,方便数据管理
- 相比 string 操作消耗内在与cpu 更小
缺点:
- 过期功能不能使用在field 上,只能用在key 上
- redis 集群架构下不适合大规模使用
hset key field value // 存储一个哈希表key 的键值
hsetnx key field value // 存储一个不存在的哈希表key 的键值
hmset key field value [field value ...] // 在一个哈希表key 中存储多个键值对
hget key field // 获取哈希表key 中多个field 键值
hmget key field [field...] // 批量获取哈希表key 中多个field 键值
hdel key field [field...] // 删除哈希表key 中的field 键值
hlen key // 返回哈希表key 中field 的数据
hgetall key // 返回哈希表key 中所有的键值
hincrby key field increment // 为哈希表key 中field 键的值加上增量 increment
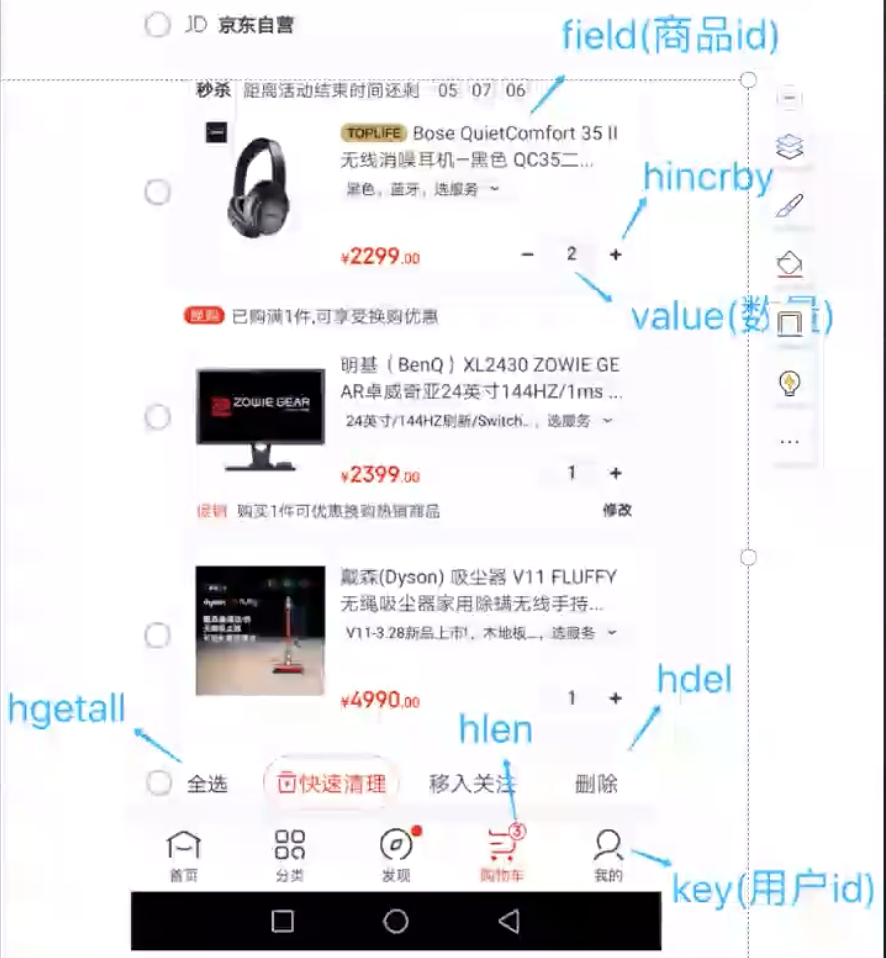
场景:购物车
以用户id 为key
以商品id 为field
商品数据为value
购物车操作
添加商品 hset cart:1001 10088 1
增加商品 hincrby cart:1001 10088 1
商品数量 hlen cart:1001
删除商品 hdel cart:1001 10088
获取购物车所有商品 hgetall cart:1001
list 结构
list 常用操作
lpush key value [value..] //插入到列表最左边
rpush key value [value...] //插入到列表最右边
lpop key // 移除列表的头元素
rpop key // 移除列表的尾元素
lrange key start stop // 列表区间内元素
blpop key [key ...] timeout // 从列表表头中弹出第一个元素。如果元素为空,阴塞等待timeout 秒。如果timeout 为0, 一直等待
brpop key [key ...] timeout // 从列表表尾弹出元素
常用数据结构
stack (栈) = lpush + lpop = filo
queue (队列) = lpush + rpop
blocking MQ(阴塞队列) = lpush + brpop
场景:
消息流页面:订阅号,微博等
(这块功能如果用数据库也可实现,但是一般性能比较慢。如果有order by 等排序功能,还容易导致索失效。)
1 发消息id为18 lpush msh:{nameId} 18
2 发消息id为20 lpush msh:{nameId} 20
3 查看消息流 lrange msg:{nameId} 0 9
每个消息流推送给每个粉丝,如果粉丝量大,lpush 命令需要优化。如pipeline,或优先推送在线用户。
set 结构
set 常用操作
sadd key member [member ...] // 往集合key 中存入元素, 元素存在则忽略
srem key member [member ...] // 从集合key 中删除元素
smembers key // 获取集合key 中所有元素
scard key // 获取集合key 的元素个数
sismember key member // 判断member 元素是否存在集合key 中
srandmember key [count] // 从集合key k 中选出count 个元素,元素不从key 中删除
spop key [count] // 从集合key 中选出count 个元素,元素从key 中删除
应用场景:
抽奖
1 点击抽奖加入集合 sadd key {userid}
2 查看所有抽奖用户 smembers key
3 抽取count 名中奖者
srandmember key [count] / spop key [count]
点赞
sadd like:{消息id}{用户id}
取消点赞
srem like:{消息id}{用户id}
检查用户是否点过赞
sismember like:{消息id}{用户id}
获取点赞用户列表
smembers like:{消息id}
获取点赞用户数
scard like:{消息id}
社交类产品的重要场景,叫社交关注模型
set 运算操作
sinter key [key ...] // 交集运算
sinterstore destination key [key ...] // 将交集结果存入新集合destination 中
sunion key [key ...] // 并集运算
sunionstore destination key [key ...] // 将并集结果存入新集合destination 中
sdiff key [key ...] // 差集运算
sdiffstore destination key [key ...] // 将差集结果存入新集合destination 中
社交关注模型
应用场景:
1 nameA关注的人 nameAset
2 nameB关注的人 nameBset
3 nameC关注的人 nameCset
4 我和nameA共同关注的人 sinter
5 我关注的人也关注了他 sismember
6 我可能认识的人 sdiff
商品筛选模型
zset 有序集合
常用操作
zadd key score member [[score member]...] // 往有序集合key 中加入带分值元素
zrem key member [member ...] // 从有序集合中删除元素
zcore key member // 返回有序集合key 中元素member 的分值
zincrby key increment member // 为有序集合key 中元素member的分值加上increment
zcard key // 返回有序集合key 中元素个数
zrange key start stop [withscores] // 正序获取有序集合key 从start 下标到stop 下标的元素
zrevrange key start stop [withscores] // 倒序
集合操作
zunionstore destkey numkeys key [key ...] 并集计算
zinterstore destkey numkeys key [key ...] 交集计算
应用场景
1 点击新闻
zincrby hotnews:202008 1 name
2 单日排行榜
zrevrange hotnews:202208 0 9 withscores
3 七日搜索榜单计算
zunionstore hotnews:20220801-20220807 7
4 展示七日榜前十
zrevrange hotnews:20220801-20220807 0 9 withscores
redis 数据结构
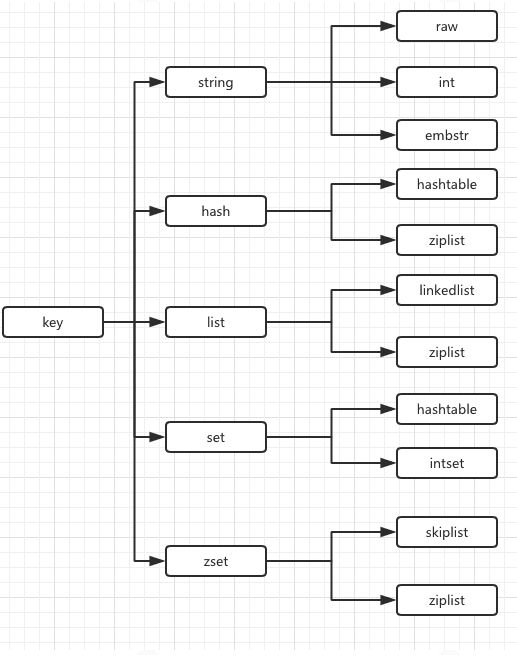
数组:根据序号随机查找很快,但是插入与删除很慢,需要挪动很多元素。
链表:插入与删除很快,只需要修改相邻元素指针,但是查找很慢,需要从第一个元素逐个遍历查找。
有序数组支持折半查找,链表不支持折半查找。
有序数组的折半查找操作速度很快,但是插入、删除操作很慢。
跳表(O(logN)):将有序列表改造为支持“折半查找”算法,可以进行快速的插入、删除、查找操作。
文:一只阿木木
总结篇4:redis 核心数据存储结构及核心业务模型实现应用场景的更多相关文章
- Redis之数据存储结构
今天去中关村软件园面试,被问到:你做项目用到的Redis处理数据用的什么结构?顿时石化,”用到的结构,不就是key-value嘛,还有什么结构?“.面试官说:“平时除了工作,要加强学习,下面的面试我觉 ...
- Redis数据结构(一)-Redis的数据存储及String类型的实现
1 引言 Redis作为基于内存的非关系型的K-V数据库.因读写响应快速.原子操作.提供了多种数据类型String.List.Hash.Set.Sorted Set.在项目中有着广泛的使用,今天我们来 ...
- Berkeley DB的数据存储结构——哈希表(Hash Table)、B树(BTree)、队列(Queue)、记录号(Recno)
Berkeley DB的数据存储结构 BDB支持四种数据存储结构及相应算法,官方称为访问方法(Access Method),分别是哈希表(Hash Table).B树(BTree).队列(Queue) ...
- kafka 数据存储结构+原理+基本操作命令
数据存储结构: Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的.每个topic又可以分成几个不同的partition(每个topic有几个partitio ...
- Cassandra 的数据存储结构——本质是SortedMap<RowKey, SortedMap<ColumnKey, ColumnValue>>
Cassandra 的数据存储结构 Cassandra 的数据模型是基于列族(Column Family)的四维或五维模型.它借鉴了 Amazon 的 Dynamo 和 Google's BigTab ...
- MySQL innodb存储引擎的数据存储结构
InnoDB存储引擎的数据存储结构 B+ 树 为什么选择B+树? 因为B+树的叶子节点存储了所有的data,所以它的非叶子节点可以存储更多的key,使得树更矮:树的高度几乎就是I/O的次数,所以选择更 ...
- 仿Redis用来作前端浏览器的数据存储结构
用js写了一个类似redis存储结构的类库,目前只有的存储类型只有hash.set两个, 还没测试过性能,欢迎各位猿友能够帮我指出程序代码的缺陷, 后期有时间会完善其他几个类型的存储结构. /**** ...
- Hashtable数据存储结构-遍历规则,Hash类型的复杂度为啥都是O(1)-源码分析
Hashtable 是一个很常见的数据结构类型,前段时间阿里的面试官说只要搞懂了HashTable,hashMap,HashSet,treeMap,treeSet这几个数据结构,阿里的数据结构面试没问 ...
- HBase介绍(2)---数据存储结构
在本文中的HBase术语:基于列:column-oriented行:row列组:column families列:column单元:cell 理解HBase(一个开源的Google的BigTable实 ...
- 0809MySQL实战系列:大字段如何优化|数据存储结构
转自https://yq.aliyun.com/articles/59256?spm=5176.100239.blogcont59257.9.5MLR2d 摘要: 背景 线上发现一张表,1亿的数据量, ...
随机推荐
- 怎么判断一个变量arr的话是否为数组(此题用 typeof 不行)?
arr instanceof Array arr.constructor == Array Object.protype.toString.call(arr) == '[Object Array]'
- JVM学习笔记-如何在IDEA打印JVM的GC日志信息
若要在Idea上打印JVM相应GC日志,其实只需在Run/Debug Configurations上进行设置即可. 拿<深入Java虚拟机>书中的3-7代码例子来演示,如 1 public ...
- axios和AJAX的区别
axios和ajax的区别 Axios和Ajax都是用于处理网络请求和与服务器进行通信的技术,但它们之间存在一些关键的区别:12 一.技术基础:Ajax(Asynchronous JavaScript ...
- PHP 使用非对称加密算法
加密的类型: 在日常设计及开发中,为确保数据传输和数据存储的安全,可通过特定的算法,将数据明文加密成复杂的密文.目前主流加密手段大致可分为单向加密和双向加密. 单向加密:通过对数据进行摘要计算生成密文 ...
- [oeasy]python0072_整数类型_int_integer_整型变量
帮助手册 回忆上次内容 上次了解的是 字符串 字符串 就是 字符的串 字符串长度 可以用 len函数 字符可以用下标索引 [] 可以用str 将整型数字 转化为 字符串 字符的长度本身 有 ...
- CSP2023
坐标HA 背景 NOIP都打完了,CSP-S都没写游记,所以来补一篇(逃-- 正文 Day 7*-1 考前一周停课集训,被whk老师怒斥不务正业,悲QWQ. Day 0 周五得到年级第一zyx的鼓励, ...
- Docker Compose 基本概要
Docker Compose 基本概要 Compose 是一个用于定义和运行多容器 Docker 应用程序的工具.使用 YAML 文件来配置多个应用程序的服务,包括生产.暂存.开发.测试以及 CI 工 ...
- 学习笔记--Java构造方法
Java构造方法 关于构造方法 构造方法又被称作:构造函数/构造器/Constructor 语法结构: [修饰符列表] 构造方法名(形式参数列表){ 构造方法体; } 对比普通方法语法结构 [修饰符列 ...
- 张高兴的 MicroPython 入门指南:(三)使用串口通信
目录 什么是串口 使用方法 使用板载串口相互通信 硬件需求 电路 代码 使用板载的 USB 串口 参考 什么是串口 串口是串行接口的简称,这是一个非常大的概念,在嵌入式中串口通常指 UART(Univ ...
- P1081 [NOIP2012 提高组] 开车旅行
思路: 首先令 \(nxt1_i\) 表示右侧最近的城市距离(\(id1_i\) 为编号),令 \(nxt2_i\) 表示右侧第二近的城市编号(\(id2_i\) 为编号):可以使用 set 找出离这 ...