【爬虫实战】用python爬今日头条热榜TOP50榜单!
一、爬取目标
您好!我是@马哥python说,一名10年程序猿。
今天分享一期爬虫案例,爬取的目标是:今日头条热榜的榜单数据。
打开今日头条 首页,在页面右侧会看到头条热榜,如下:
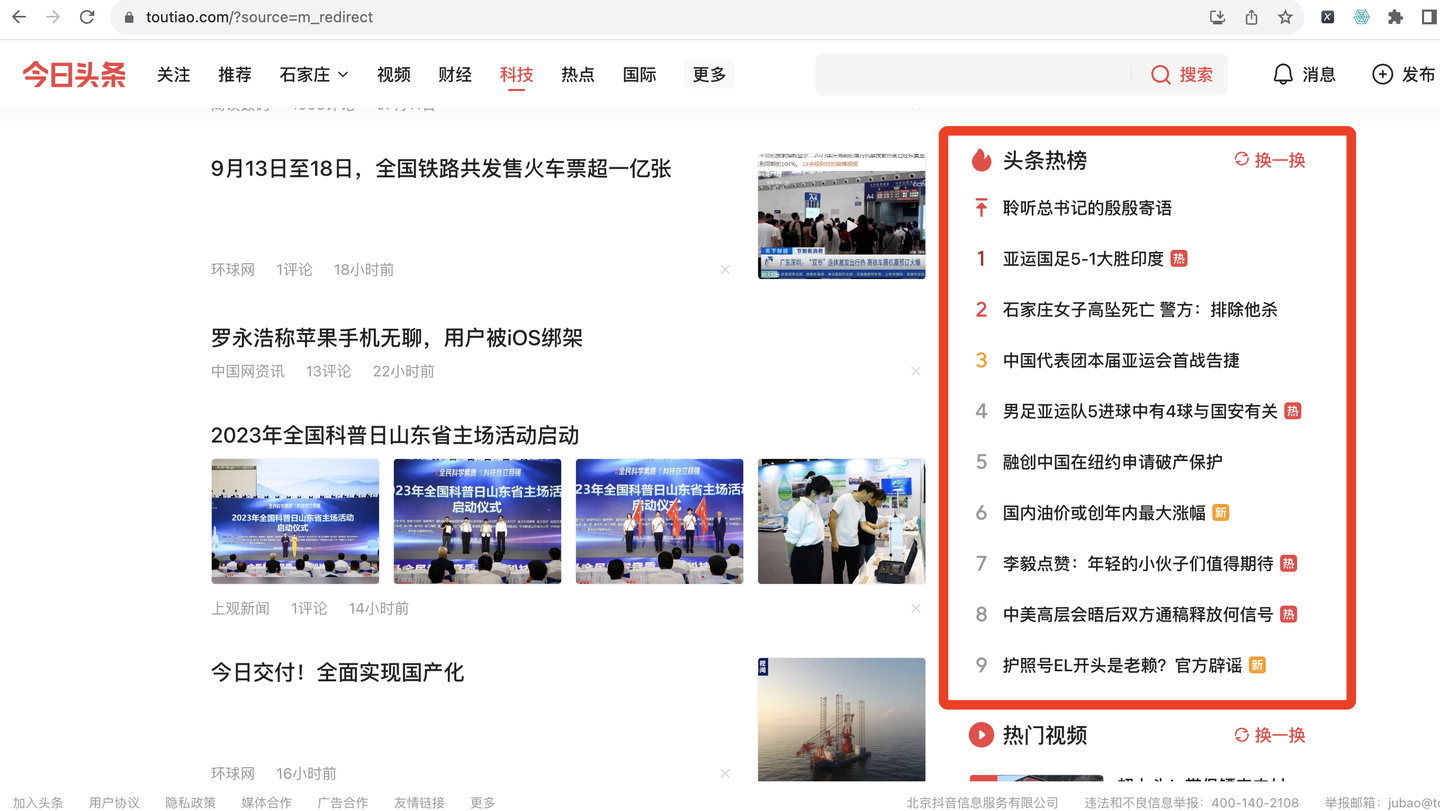
爬取以上6个关键字段,含:
热榜排名,热榜标题,热度值,热榜标签,热榜分类,热榜链接。
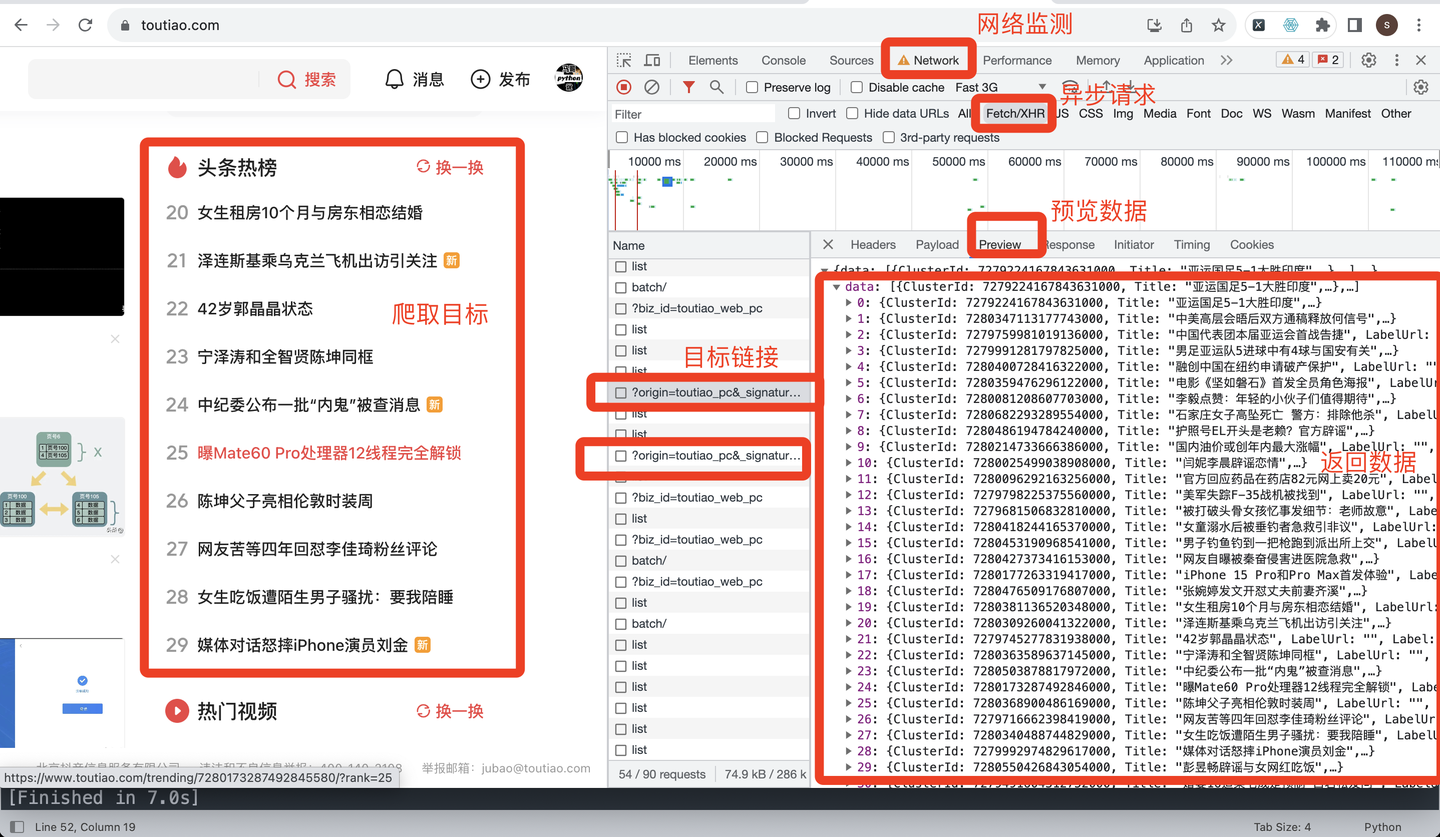
开发者模式分析:
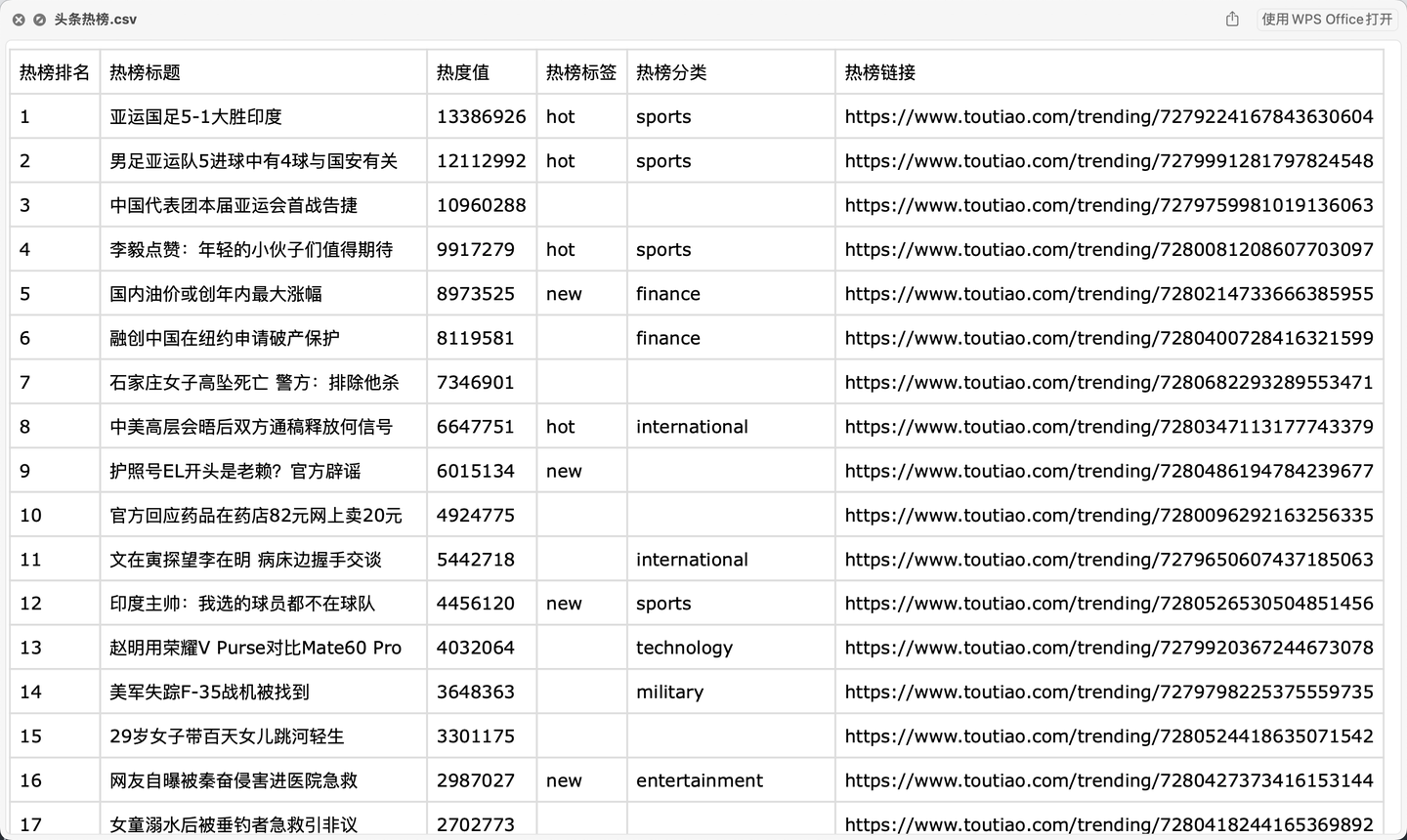
二、爬取结果
爬取结果截图:
三、代码讲解
首先,导入需要用到的库:
import requests
import pandas as pd
import re
定义一个请求头:(爬取目标较简单,一个User-agent即可)
# 请求头
h1 = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15',
}
定义请求地址:
url = 'https://www.toutiao.com/hot-event/hot-board/?origin=toutiao_pc'
用requests发送请求:
# 发送请求
response = requests.get(url, headers=h1)
查看响应码并以json方式接收返回数据:
# 查看响应码
print(r.status_code)
# 接收返回数据
json_data = r.json()
定义一些空列表,用于存放数据:
title_list = [] # 热榜标题
value_list = [] # 热度值
url_list = [] # 热榜链接
category_list = [] # 热榜分类
label_list = [] # 热榜标签
以"热榜标题"字段为例:
for data in json_data['data']:
# 热榜标题
title = data['Title']
print('热榜标题:', title)
title_list.append(title)
其中,热榜链接比较特殊,接口中返回的url很长,形如:

可以看到,url中从?往后,都是不必要的请求参数。
所以,用正则表达式把?后面的全部删掉,提取出id,再进行拼接url,如下:
# 正则表达式提取出链接id
url3 = re.search(r"(?<=https:\/\/www\.toutiao\.com\/trending\/)\d+", url2).group(0)
# 拼接链接
url4 = 'https://www.toutiao.com/trending/' + str(url3)
最后,把所有字段存放的列表数据组成Dataframe格式:
# 把列表数据组装成Dataframe数据
df = pd.DataFrame(
{
'热榜排名': range(1, data_num + 1), # 一共50条
'热榜标题': title_list,
'热度值': value_list,
'热榜标签': label_list,
'热榜分类': category_list,
'热榜链接': url_list,
}
)
进一步保存到csv文件里:
# 保存到csv文件
df.to_csv(result_file, header=True, index=False, encoding='utf_8_sig')
以上,核心逻辑讲解完毕。
代码中还含有:解析热度值、热榜标签、热榜分类、热榜链接字段等,详见文末完整代码。
四、技术总结
爬取技术流程:
- requests 发送请求
- json 解析数据
- re 正则表达式提取文本
- pandas 保存csv
五、演示视频
演示视频:代码演示:用python爬头条热榜TOP50榜单!
六、附完整源码
本案例完整源码已上传微信公众号"老男孩的平凡之路",后台回复"爬头条热榜"即可获取。 点击直达:点这里
我是@马哥python说,一名10年程序猿,持续分享python干货中!
【爬虫实战】用python爬今日头条热榜TOP50榜单!的更多相关文章
- Python爬虫学习笔记之爬今日头条的街拍图片
代码: import requests import os from hashlib import md5 from urllib.parse import urlencode from multip ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫实战三之爬取嗅事百科段子
一.前言 俗话说,上班时间是公司的,下班了时间才是自己的.搞点事情,写个爬虫程序,每天定期爬取点段子,看着自己爬的段子,也是一种乐趣. 二.Python爬取嗅事百科段子 1.确定爬取的目标网页 首先我 ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- 一起学爬虫——使用xpath库爬取猫眼电影国内票房榜
之前分享了一篇使用requests库爬取豆瓣电影250的文章,今天继续分享使用xpath爬取猫眼电影热播口碑榜 XPATH语法 XPATH(XML Path Language)是一门用于从XML文件中 ...
- Python爬虫实战教程:爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Amauri PS:如有需要Python学习资料的小伙伴可以加点击 ...
随机推荐
- Oracle regexp_replace 手机号脱敏
select '18012345678',regexp_replace('18012345678','(.){4}','****',4,1) from dual;
- KingbaseES toast技术原理及实现
前言 1.TOAST的作用 TOAST全称是The Oversized-Attribute Storage Technique, 超大属性存储技术,就是超长字段在数据库中的存储方式.主要用来应对物理数 ...
- JS实现决策报表缓存最后一次查询条件
问题描述 决策报表在打开时希望参数控件的值可以默认是上一次页面关闭前最后一次查询所选择的值. 解决方案 每次点击查询后将参数值保存到浏览器缓存中(适用于控件在参数栏内),或每次控件值发生改变后将参数值 ...
- 5 JavaScript变量提升
5 变量提升 看以下代码, 或多或少会有些问题的. function fn(){ console.log(name); var name = '大马猴'; } fn() 发现问题了么. 这么写代码, ...
- Jetty的bytebufferpool模块
bytebufferpool模块用于配置Jetty的ByteBuffer对象的对象池. 通过对象池的方式来管理ByteBuffer对象的使用和生命周期,期望降低Jetty进程内存的使用,同时降低JVM ...
- [一本通1681]统计方案 题解(Meet in mid与逆元的结合)
题目描述 小\(B\)写了一个程序,随机生成了\(n\)个正整数,分别是\(a[1]-a[n]\),他取出了其中一些数,并把它们乘起来之后模\(p\),得到了余数\(c\).但是没过多久,小\(B\) ...
- Visual Studio 2022插件的安装及使用 - 编程手把手系列文章
这次开始写手把手编程系列文章,刚写到C#的Dll程序集类库的博文,就发现需要先介绍Visual Studio 2022的插件的安装及使用,因为在后面编码的时候会用到这些个插件,所以有必要先对这个内容进 ...
- Elasticjob 3.x 最新版本源码解读(含备注源码)
源码地址(含备注):https://gitee.com/ityml/elastic-job-zgc 官方网站: https://shardingsphere.apache.org/elasticjob ...
- 鸿蒙HarmonyOS实战-ArkUI组件(Navigation)
一.Navigation Navigation组件通常作为页面的根容器,支持单页面.分栏和自适应三种显示模式.开发者可以使用Navigation组件提供的属性来设置页面的标题栏.工具栏.导航栏等. 在 ...
- 重新点亮linux 命令树————压缩和解压缩[四]
前言 简单整理一下压缩和解压缩. 正文 在windows 中我们使用压缩和解压缩一般是7z这个压缩和解压软件,但是在linux中压缩和解压是两个不同的软件. 在最早的linux 备份介质是磁带,使用的 ...