Python爬虫实战教程:爬取网易新闻
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: Amauri
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
此文属于入门级级别的爬虫,老司机们就不用看了。
本次主要是爬取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选的分类是国内新闻。然后鼠标右键点击查看源代码,发现源代码中并没有页面正中的新闻列表。这说明此网页采用的是异步的方式。也就是通过api接口获取的数据。
那么确认了之后可以使用F12打开谷歌浏览器的控制台,点击Network,我们一直往下拉,发现右侧出现了:"... special/00804KVA/cm_guonei_03.js? .... "之类的地址,点开Response发现正是我们要找的api接口。 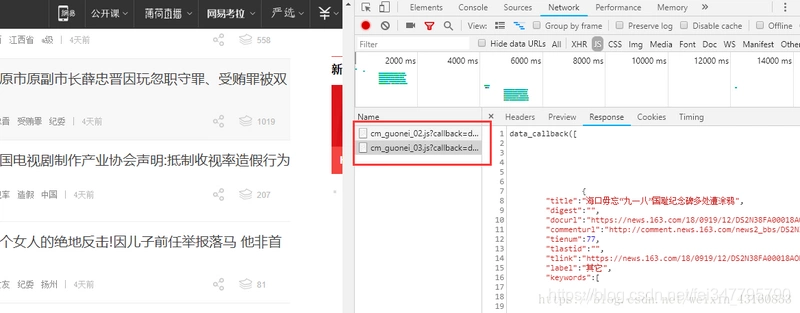
可以看到这些接口的地址都有一定的规律:“cm_guonei_03.js”、 “cm_guonei_04.js”,那么就很明显了:
http://temp.163.com/special/0...*).js
上面的连接也就是我们本次抓取所要请求的地址。
接下来只需要用到的python的两个库:
requests
json
BeautifulSoup
requests库就是用来进行网络请求的,说白了就是模拟浏览器来获取资源。
由于我们采集的是api接口,它的格式为json,所以要用到json库来解析。BeautifulSoup是用来解析html文档的,可以很方便的帮我们获取指定div的内容。
下面开始编写我们爬虫:
第一步先导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
接着我们定义一个获取指定页码内数据的方法:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样子就得到每个页码对应的内容列表:
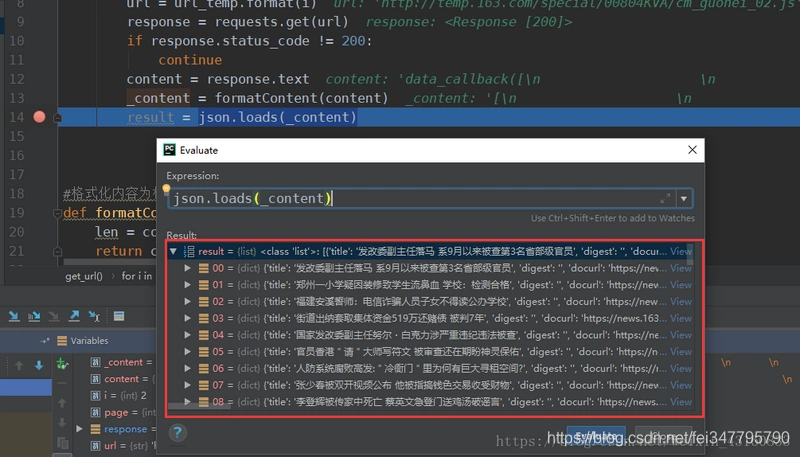
之后通过分析数据可知下图圈出来的则是需要抓取的标题、发布时间以及新闻内容页面。
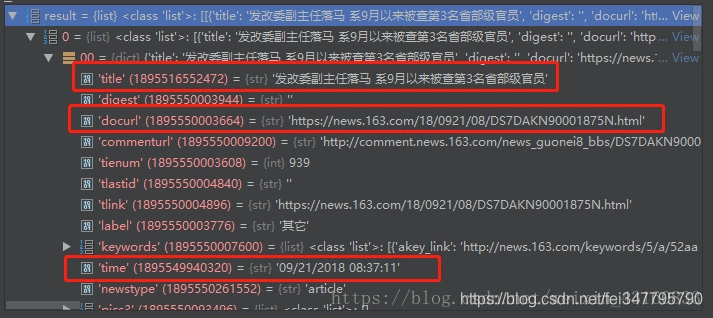
既然现在已经获取到了内容页的url,那么接下来开始抓取新闻正文。
在抓取正文之前要先分析一下正文的html页面,找到正文、作者、来源在html文档中的位置。
我们看到文章来源在文档中的位置为:id = "ne_article_source" 的 a 标签。 作者位置为:class = "ep-editor" 的 span 标签。 正文位置为:class = "post_text" 的 div 标签。
下面试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到此为止我们所要抓取的所有数据都已经采集了。
那么接下来当然是把它们保存下来,为了方便我直接采取文本的形式来保存。下面是最终的结果:

格式为json字符串,“标题” : [ ‘日期’, ‘url’, ‘来源’, ‘作者’, ‘正文’ ]。
要注意的是目前实现的方式是完全同步的,线性的方式,存在的问题就是采集会非常慢。主要延迟是在网络IO上,可以升级为异步IO,异步采集。
Python爬虫实战教程:爬取网易新闻的更多相关文章
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python爬虫实战之爬取智联职位信息和博客文章信息
1.python爬取招聘信息 简单爬取智联招聘职位信息 # !/usr/bin/env python # -*-coding:utf-8-*- """ @Author ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- python 爬虫实战1 爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 本篇目标 抓取糗事百科热门段子 过滤带有图片的段子 实现每按一次回车显示一个段子的发布时间,发布人 ...
- 原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我 注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的. 爬虫 ...
- python 爬虫实战4 爬取淘宝MM照片
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http:/ ...
- 芝麻HTTP:Python爬虫实战之爬取百度贴吧帖子
本篇目标 1.对百度贴吧的任意帖子进行抓取 2.指定是否只抓取楼主发帖内容 3.将抓取到的内容分析并保存到文件 1.URL格式的确定 首先,我们先观察一下百度贴吧的任意一个帖子. 比如:http:// ...
随机推荐
- 如何将hive表中的数据导出
近期经常将现场的数据带回公司测试,所以写下该文章,梳理一下思路. 1.首先要查询相应的hive表,比如我要将c_cons这张表导出,我先查出hive中是否有这张表. 查出数据,证明该表在hive中存在 ...
- POJ2182题解——线段树
POJ2182题解——线段树 2019-12-20 by juruoOIer 1.线段树简介(来源:百度百科) 线段树是一种二叉搜索树,与区间树相似,它将一个区间划分成一些单元区间,每个单元区间对应线 ...
- threejs 限制物件只能在指定平面上拖拽
threejs提供有 DragController.js的例子来辅助拖拽 该例子可以在基于当前屏幕的x和y轴上拖拽物体,但是它不能影响z轴. 查看代码,可以在touchStart\mousedown下 ...
- Prometheus监控(二)
Prometheus监控(二) 数据类型 Counter(计数器类型) Counter类型的指标的工作方式和计数器一样,只增不减(除非系统发生了重置),Counter一般用于累计值. Gauges(仪 ...
- Larave中CSRF攻击
1.什么是CSRF攻击? CSRF是跨站请求伪造(Cross-site request forgery)的英文缩写\ Laravel框架中避免CSRF攻击很简单 ...
- Java每日一面(Part2数据库)[19/11/28]
作者:故事我忘了¢个人微信公众号:程序猿的月光宝盒 1.如何设计一个关系型数据库 如上图,首先划分成两大部分: 1.存储部分:类似一个文件系统,把数据存储到一个持久化设备中,如机械硬盘,固态等 ...
- Java生鲜电商平台-高可用微服务系统如何设计?
Java生鲜电商平台-高可用微服务系统如何设计? 说明:Java生鲜电商平台高可用架构往往有以下的要求: 高可用.这类的系统往往需要保持一定的 SLA,7*24 时不间断运行不代表完全不挂,而是有一定 ...
- pyhton的安装,环境变量的设置,pycharm的安装下载,中文汉化和字体的设置
1.下载pycharm https://www.7down.com/soft/336988.html 1.pycharm的汉化下载汉化包:resources_cn.jar 放到pycharm的安 ...
- 软工第八次实验——Git
hiahiahia我又来作恶了,莫名其妙的第八次实验还要更新! 文章目录 一.Git 1.1 概述 1.1.1 Git 1.1.2 分布式版本控制系统 1.1.3 指令集 1.2 版本控制系统 1.2 ...
- [Go] 轻量服务器框架全局配置的实现以及解析json
在一个应用中经常需要有一个配置文件,可以对代码中的参数进行配置,可以使用一个json文件来对应一个struct的对象,进行全局配置 建一个conf/zinx.json作为配置文件 { "Na ...