【爬虫实战】用python爬今日头条热榜TOP50榜单!
一、爬取目标
您好!我是@马哥python说,一名10年程序猿。
今天分享一期爬虫案例,爬取的目标是:今日头条热榜的榜单数据。
打开今日头条 首页,在页面右侧会看到头条热榜,如下:
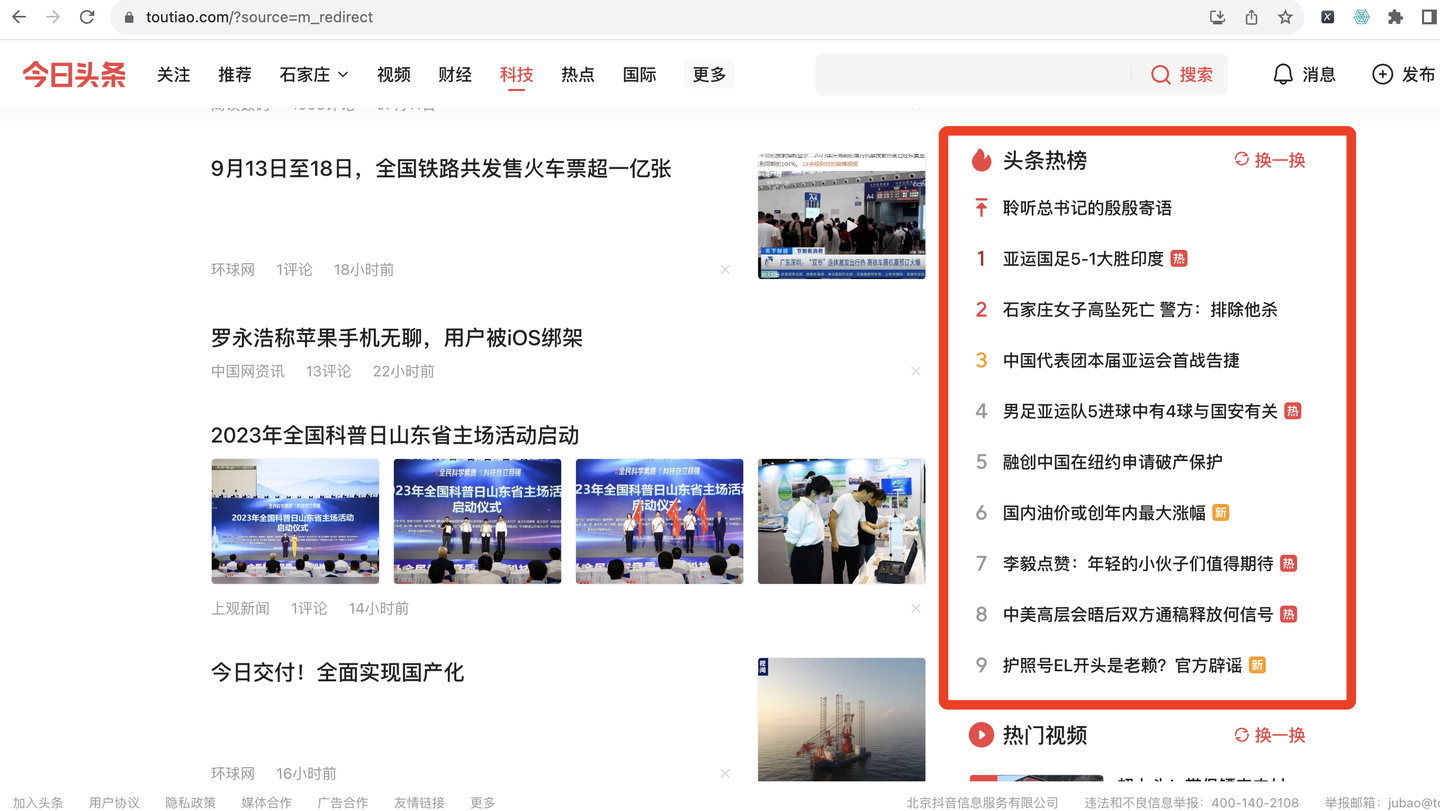
爬取以上6个关键字段,含:
热榜排名,热榜标题,热度值,热榜标签,热榜分类,热榜链接。
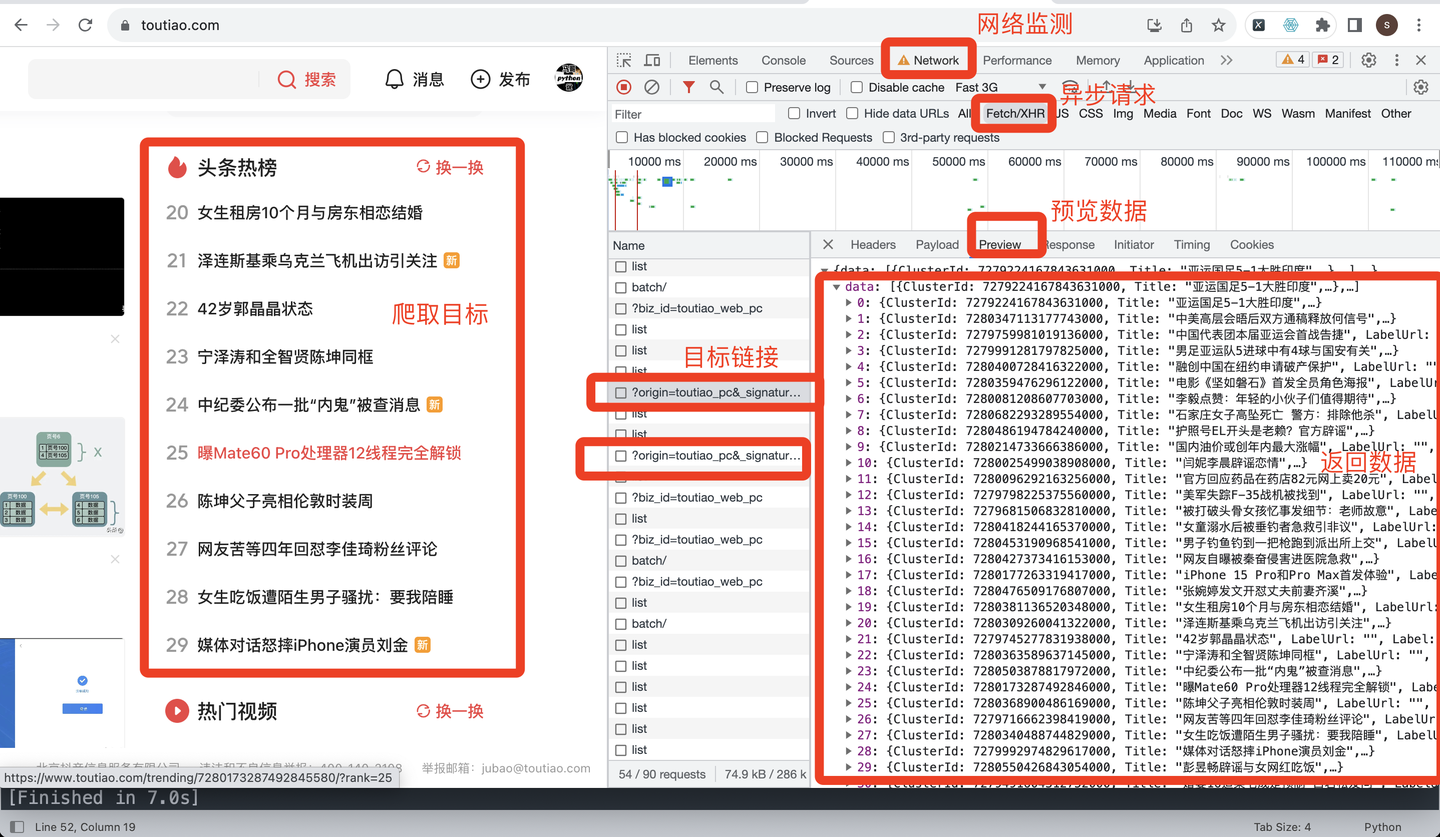
开发者模式分析:
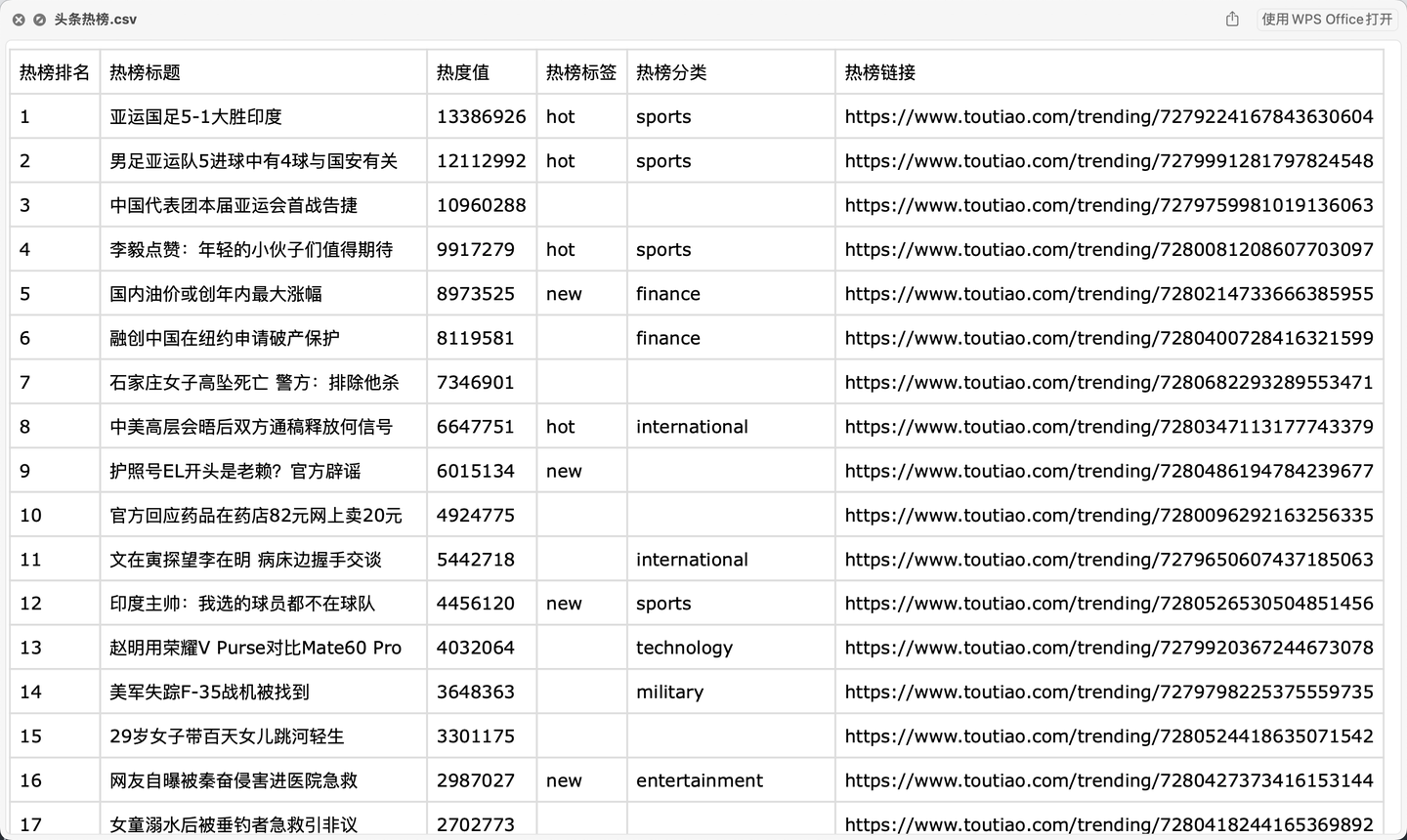
二、爬取结果
爬取结果截图:
三、代码讲解
首先,导入需要用到的库:
import requests
import pandas as pd
import re
定义一个请求头:(爬取目标较简单,一个User-agent即可)
# 请求头
h1 = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15',
}
定义请求地址:
url = 'https://www.toutiao.com/hot-event/hot-board/?origin=toutiao_pc'
用requests发送请求:
# 发送请求
response = requests.get(url, headers=h1)
查看响应码并以json方式接收返回数据:
# 查看响应码
print(r.status_code)
# 接收返回数据
json_data = r.json()
定义一些空列表,用于存放数据:
title_list = [] # 热榜标题
value_list = [] # 热度值
url_list = [] # 热榜链接
category_list = [] # 热榜分类
label_list = [] # 热榜标签
以"热榜标题"字段为例:
for data in json_data['data']:
# 热榜标题
title = data['Title']
print('热榜标题:', title)
title_list.append(title)
其中,热榜链接比较特殊,接口中返回的url很长,形如:

可以看到,url中从?往后,都是不必要的请求参数。
所以,用正则表达式把?后面的全部删掉,提取出id,再进行拼接url,如下:
# 正则表达式提取出链接id
url3 = re.search(r"(?<=https:\/\/www\.toutiao\.com\/trending\/)\d+", url2).group(0)
# 拼接链接
url4 = 'https://www.toutiao.com/trending/' + str(url3)
最后,把所有字段存放的列表数据组成Dataframe格式:
# 把列表数据组装成Dataframe数据
df = pd.DataFrame(
{
'热榜排名': range(1, data_num + 1), # 一共50条
'热榜标题': title_list,
'热度值': value_list,
'热榜标签': label_list,
'热榜分类': category_list,
'热榜链接': url_list,
}
)
进一步保存到csv文件里:
# 保存到csv文件
df.to_csv(result_file, header=True, index=False, encoding='utf_8_sig')
以上,核心逻辑讲解完毕。
代码中还含有:解析热度值、热榜标签、热榜分类、热榜链接字段等,详见文末完整代码。
四、技术总结
爬取技术流程:
- requests 发送请求
- json 解析数据
- re 正则表达式提取文本
- pandas 保存csv
五、演示视频
演示视频:代码演示:用python爬头条热榜TOP50榜单!
六、附完整源码
本案例完整源码已上传微信公众号"老男孩的平凡之路",后台回复"爬头条热榜"即可获取。 点击直达:点这里
我是@马哥python说,一名10年程序猿,持续分享python干货中!
【爬虫实战】用python爬今日头条热榜TOP50榜单!的更多相关文章
- Python爬虫学习笔记之爬今日头条的街拍图片
代码: import requests import os from hashlib import md5 from urllib.parse import urlencode from multip ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫实战三之爬取嗅事百科段子
一.前言 俗话说,上班时间是公司的,下班了时间才是自己的.搞点事情,写个爬虫程序,每天定期爬取点段子,看着自己爬的段子,也是一种乐趣. 二.Python爬取嗅事百科段子 1.确定爬取的目标网页 首先我 ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- 一起学爬虫——使用xpath库爬取猫眼电影国内票房榜
之前分享了一篇使用requests库爬取豆瓣电影250的文章,今天继续分享使用xpath爬取猫眼电影热播口碑榜 XPATH语法 XPATH(XML Path Language)是一门用于从XML文件中 ...
- Python爬虫实战教程:爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Amauri PS:如有需要Python学习资料的小伙伴可以加点击 ...
随机推荐
- KingbaseES V8R6 集群运维案例 -- 禁止普通用户su到root
案例说明: 在集群管理中,会使用到root权限(如ip.aring命令等),为安全需要,有的生产环境禁止普通用户su切换到root,本案例测试了禁止普通用户su切换到root对集群管理带来的影响. 集 ...
- PyCharm字体大小快捷键设置(“ctrl+滚轮”实现字体的随时放大和缩小)
前言:我们在使用PyCharm工具编写Python代码的时候,希望能够随时放大缩小字体,而PyCharm默认是没有设置快捷键的,我们可以自己设置,下面就教大家如何设置. 分为两步设置: PyCharm ...
- Java实现栈
package algorithm; import java.util.Arrays; import java.util.Iterator; /** @author Administrator @da ...
- Android---ListView控件用法
首先要使用ListView是要自定义一个适配器类的,先简单分析一下适配器怎么写: 示例程序是要使用ListView列表显示出水果的图片以及对应的水果文字描述(水果名字). public class F ...
- 不到2000字,轻松带你搞懂STM32中GPIO的8种工作模式
大家好,我是知微! 学习过单片机的小伙伴对GPIO肯定不陌生,GPIO (general purpose input output)是通用输入输出端口的简称,通俗来讲就是单片机上的引脚. 在STM32 ...
- #链表#CF706E Working routine
题目 给出一个 \(n*m\) 的矩阵,每次交换两个等大的矩阵,输出 \(q\) 次操作后的矩阵 分析 维护向右和向下的指针,考虑最后输出只需要从每行的头指针向右跳, 那么修改实际上是将矩阵左边一列. ...
- 密码学系列之:IDEA
密码学系列之:IDEA 目录 简介 IDEA简介 IDEA原理 IDEA子密钥的生成 简介 IDEA的全称是International Data Encryption Algorithm,也叫做国际加 ...
- 带你玩转OpenHarmony AI:基于Seetaface2的人脸识别
简介 随着时代的进步,全民刷脸已经成为一种新型的生活方式,这也是全球科技进步的又一阶梯,人脸识别技术已经成为一种大趋势,无论在智慧出行.智能家居.智慧办公等场景均有较广泛的应用场景,本文介绍了基于Se ...
- R语言学习3:数据框处理(1)
本系列是一个新的系列,在此系列中,我将和大家共同学习R语言.由于我对R语言的了解也甚少,所以本系列更多以一个学习者的视角来完成. 参考教材:<R语言实战>第二版(Robert I.Kaba ...
- Leetcode-队列得最大值
请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数max_value.push_back 和 pop_front 的均摊时间复杂度都是O(1).若队列为空,pop_front ...