为什么 GPU 更适用于时域算法,而 CPU 更适用于频域算法?
对于懂电脑的人来讲,他们可以简单地区分出电脑的GPU和CPU的应用范畴及其优势,而今天我们要讨论的问题是“为什么 GPU 更适用于时域算法,而 CPU 更适用于频域算法?”在讨论这个问题之前,我先带大家来了解一下计算中 GPU 与 CPU 架构的区别及并行的处理方式。
1. CPU 与 GPU 架构的区别
CPU 和 GPU 在基本架构层面上存在巨大的差异,CPU 有庞大而广泛的指令集,可与更多的计算机组件(例如内存、输入和输出)交互以执行复杂的指令;而 GPU 是一种专门的协处理器,只有在高数据吞吐量的任务上表现出色,而在其他任务上的表现则不尽如人意。
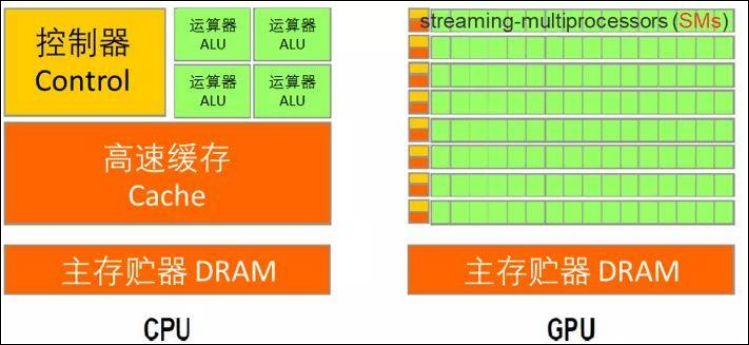
CPU 更强调指定运行的低延迟,其处理方式主要为串行,如果遇到多任务并发需求,则只能通过切换进行,切换时 CPU 必须重置寄存器和状态变量、刷新缓存等等。不过 CPU 经过延迟优化,在多个任务之间的切换速度非常快,让人感觉它在并行处理任务,但本质上,它仍为一次运行一项任务。因此 CPU 可迅速处理各种不同难度的任务,但面对源源不断的重复性任务也会力不从心。
因此想要提高 CPU 的性能,需要靠不断提高主频来实现,比如常见的 CPU 主频为 2~4GHz。
相比之下,GPU 更强调高数据吞吐量,其核心的主频通常为 1GHz 左右,提高处理速度除了提高主频和架构,也常常通过“堆料”的方式进行,即增加流处理器的数量。因此相对于 CPU, GPU更适合于重复性和高度并行的计算任务,最常规也是最初始的应用便是图形渲染和显示。后来人们发现它对多组数据执行并行操作的能力,也非常适合于某些非图形任务,例如机器学习、金融、模拟、科学计算等大规模且反复运行相同数学函数的活动。

2. 并行处理
并行处理有三个分类:数据并行、指令并行和线程并行。线程是一串串行执行的指令,每条指令操作一个或多个数据。在此基础上,实现并行的方式有三种,一种是多个这样的串行指令序列同时执行,就是 Hydra 为代表的多线程并行模式;第二种数据并行是同一条指令应用在并行的数据上。
比如本来是一条加法指令计算 C=A+B,同时将加法应用到一组 A 和一组 B 上得到一组 C 上就是数据并行。这就是典型的单指令多数据 SIMD(Single Instruction Multiple Data)架构。
第三种是指令并行,也就是说在同一时间发射多条指令,同时计算不同数据多个不同运算,这是典型的VLIW(Very Long Instruction Word)架构。但是由于实现 VLIW 的编译器难度太高,使得直接实现大规模可扩展的指令并行比较困难。

Imagine 是斯坦福的一个数据并行的多核处理器。Imagine 有 8 个 ALU 单元被同一个控制器所控制,同时对大量的并行数据进行同样的操作。这种处理器的模式后来被称为流处理器,也是现今 Nvidia 采用的架构,如 Fermi 系列,就是这种数据并行流处理器的一种实现实例。
下图即是Imagine 的结构框图,可以看到它犹如一个大型 SIMD 单元簇。不可否认的是,就这样一个看似简单的设计架构却能极大地提高数据运算的并行度,使得它在处理 SIMD 数据时,如 FDTD/FITD 这样对同一数据地址上的数进行完全相同的简单 ALU(算术逻辑单元 - Arithmetic Logic Unit)操作具有极高的并行效率。
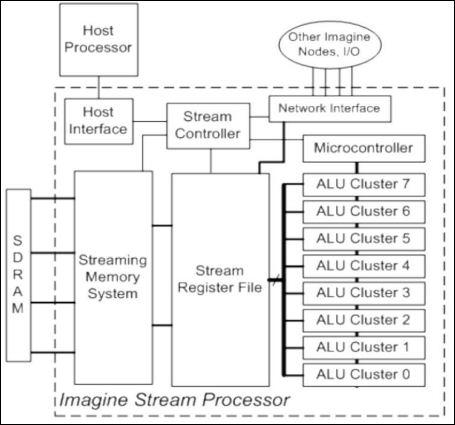
接下来我们来考察一下 GPU 处理器的结构,如 Nvidia Fermi 系列,不难发现他们和 Imagine 有着惊人的相似之处,即每个处理器核是一个简单的 ALU 阵列。在 Nvidia 的名词里,处理器核叫Streaming Multiprocessor(SM),每个 Fermi 的 SM 里有 32 个 32 位的 ALU、32 个单精度的浮点运算单元还有一些特殊运算单元。
SM 相当于 Imagine 中的 ALU Cluster,能够执行 SIMD 的操作,但是绝对和 Intel 以及 AMD 中的处理器核相距甚远。通用处理器中的每个核拥有庞大的指令池 Pool和寄存器堆 Stack,可执行繁杂的指令预取、分支预测、条件跳转等操作,虽然计算单元不如 SM多。换句话说,如果你的程序没有那么宽的单指令多数据并行,就不要指望 SM 比传统处理器核快。
了解了 CPU 和 GPU 的架构后,不难得出如下结论:当程序或算法中存在大量规则数据并行的操作或运算时,GPU 将是最佳选择;相反地,当程序中有大量的分支或跳转或对不同数据源需要进行操作时,CPU 的效率更高。即 SIMD 部分占整个运算的百分比,此百分比越大,则采用 GPU的效果将越好,否则,采用 CPU 会更好。
所以并不是一般人所理解的,GPU 就适用于 FDTD,而不适用于 FEM,只是 FEM 中能够进行 SIMD 的部分太小,所以 CPU 对其更有效而已。
推荐文章:
为什么 GPU 更适用于时域算法,而 CPU 更适用于频域算法?的更多相关文章
- 思考与算法:大脑是cpu、思考是算法
思考与算法:大脑是cpu.思考是算法
- 【算法•日更•第五十期】二分图(km算法)
▎前言 戳开这个链接看看,惊不惊喜,意不意外?传送门. 没想到我的博客竟然被别人据为己有了,还没办法投诉. 这年头写个博客太难了~~~ 之前小编写过了二分图的一些基础知识和匈牙利算法,今天来讲一讲km ...
- 最小生成树--Prim算法,基于优先队列的Prim算法,Kruskal算法,Boruvka算法,“等价类”UnionFind
最小支撑树树--Prim算法,基于优先队列的Prim算法,Kruskal算法,Boruvka算法,“等价类”UnionFind 最小支撑树树 前几节中介绍的算法都是针对无权图的,本节将介绍带权图的最小 ...
- 《算法4》2.1 - 插入排序算法(Insertion Sort), Python实现
排序算法列表电梯: 选择排序算法:详见 Selection Sort 插入排序算法(Insertion Sort):非常适用于小数组和部分排序好的数组,是应用比较多的算法.详见本文 插入排序算法的语言 ...
- 数构与算法 | 什么是大 O 表示算法时间复杂度
正文: 开篇我们先思考这么一个问题:一台老式的 CPU 的计算机运行 O(n) 的程序,和一台速度提高的新式 CPU 的计算机运 O(n2) 的程序.谁的程运行效率高呢? 答案是前者优于后者.为什么呢 ...
- 目标反射回波检测算法及其FPGA实现 之一:算法概述
目标反射回波检测算法及其FPGA实现之一:算法概述 前段时间,接触了一个声呐目标反射回波检测的项目.声呐接收机要实现的核心功能是在含有大量噪声的反射回波中,识别出发射机发出的激励信号的回波.我会分几篇 ...
- (转)jvm具体gc算法介绍标记整理--标记清除算法
转自:https://www.cnblogs.com/ityouknow/p/5614961.html GC算法 垃圾收集器 概述 垃圾收集 Garbage Collection 通常被称为“GC”, ...
- EM算法(1):K-means 算法
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(1) : K-means算法 1. 简介 K-mean ...
- VIPS:基于视觉的页面分割算法[微软下一代搜索引擎核心分页算法]
VIPS:基于视觉的页面分割算法[微软下一代搜索引擎核心分页算法] - tingya的专栏 - 博客频道 - CSDN.NET VIPS:基于视觉的页面分割算法[微软下一代搜索引擎核心分页算法] 分类 ...
- 【算法】字符串匹配之Z算法
求文本与单模式串匹配,通常会使用KMP算法.后来接触到了Z算法,感觉Z算法也相当精妙.在以前的博文中也有过用Z算法来解决字符串匹配的题目. 下面介绍一下Z算法. 先一句话讲清楚Z算法能求什么东西. 输 ...
随机推荐
- Spring源码构建踩坑记录
1:Kotlin: warnings found and -Werror specified Kotlin将程序中的警告变更为错误导致的问题,只需要改变一下级别即可,注意看是那个模块的 解决方式:fi ...
- 痞子衡嵌入式:盘点国内RISC-V内核MCU厂商(2018年发布产品)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是国内RISC-V内核MCU厂商(2018). 虽然RISC-V风潮已经吹了好几年,但2019年才是其真正进入主流市场的元年,最近国内大量 ...
- Javaweb学习笔记第六弹
本章节的存在意义是:学到PreparedStatement反应较慢,理解不透彻,来做个比较,加深印象 详细讲述PrepareStatement 与 Statement 连接数据库的部分区别 在我学习的 ...
- 【Unity3D】常用快捷键
1 单键 Q:扒手拖动(Scene) W:移动(GameObject) E:旋转 R:三维缩放(GameObject 不会变形) T:单维缩放(GameObject 会变形) Y:平移.旋转.缩放 F ...
- Promise的使用及原理
此文章主要讲解核心思想和基本用法,想要了解更多细节全面的使用方式,请阅读官方API 这篇文章假定你具备最基本的异步编程知识,例如知道什么是回调,知道什么是链式调用,同时具备最基本的单词量,例如page ...
- Python ArcPy批量掩膜、重采样大量遥感影像
本文介绍基于Python中ArcPy模块,对大量栅格遥感影像文件进行批量掩膜与批量重采样的操作. 首先,我们来明确一下本文的具体需求.现有一个存储有大量.tif格式遥感影像的文件夹:且其中除了 ...
- Nacos 服务发现
更多内容,前往 IT-BLOG 一.Nacos 简介 Nacos 是阿里的一个开源产品,它是针对微服务架构中的服务发现.配置管理.服务治理的综合型解决方案.Nacos 使服务更容易注册,并通过 DNS ...
- 阿里巴巴建议这样遍历Map,今天就用几种方式做个比较一下看那种最好用
今天不举例子了,问一句你开心吗?不开心也要记得把开心的事情放到快乐源泉小瓶子里,偶尔拿出来一一遍历看看. Map在我们Java程序员高频使用的一种数据结构,Map的遍历方式也有很多种,那那种方式比较 ...
- Java设计模式 —— 桥接模式
10 桥接模式 10.1 桥接模式概述 Bridge Pattern: 将抽象部分与它的实现部分解耦,使得两者都能够独立变化. 桥接模式是一种很实用的结构型模式,如果系统中某个类存在两个独立变化的维度 ...
- SprintBoot2报错汇总
报错1:SpringBoot找不到bean Unable to start ServletWebServerApplicationContext due to missing ServletWebSe ...