使用 Apache SeaTunnel 实现 Kafka Source 解析复杂Json 案例

版本说明:
SeaTunnel:apache-seatunnel-2.3.2-SNAPHOT
引擎说明:
Flink:1.16.2
Zeta:官方自带
前言
近些时间,我们正好接手一个数据集成项目,数据上游方是给我们投递到Kafka,我们一开始的技术选型是SpringBoot+Flink对上游数据进行加工处理(下文简称:方案一),由于测试不到位,后来到线上,发现数据写入效率完全不符合预期。后来将目光转到开源项目SeaTunnel上面,发现Source支持Kafka,于是开始研究测试,开发环境测试了500w+数据,发现效率在10000/s左右。果断放弃方案一,采取SeaTunnel对数据进行集成加工(下文简称:方案二)。在SeaTunnel研究的过程中,总结了两种方法,方法二相较于方法一,可以实现全场景使用,无需担心字段值里面各种意想不到的字符对数据落地造成错位现象的发生。
对比

在方案二的基础上又衍生出两种方法

所以,在经过长时间的探索和我们线上验证得出结论,建议使用方案二的方法二。
好了,我们进入正文,主篇幅主要介绍方案二中的两种方法,让大家主观的感受SeaTunnel的神奇。
方案一 Springboot+Flink实现Kafka 复杂JSON的解析
网上案例很多,在此不做过多介绍。
方案二 SeaTunnel实现Kafka复杂JSON的解析
在开始介绍之前,我们看一下我们上游方投递Kafka的Json样例数据(对部分数据进行了敏感处理),如下:
"magic": "a***G",
"type": "D***",
"headers": null,
"messageSchemaId": null,
"messageSchema": null,
"message": {
"data": {
"LSH": "187eb13****l0214723",
"NSRSBH": "9134****XERG56",
"QMYC": "01*****135468",
"QMZ": "1Zr*****UYGy%2F5bOWtrh",
"QM_SJ": "2023-05-05 16:42:10.000000",
"YX_BZ": "Y",
"ZGHQ_BZ": "Y",
"ZGHQ_SJ": "2023-06-26 16:57:17.000000",
"SKSSQ": 202304,
"SWJG_DM": "",
"SWRY_DM": "00",
"CZSJ": "2023-05-05 16:42:10.000000",
"YNSRSBH": "9134****XERG56",
"SJTBSJ": "2023-06-26 19:29:59.000",
"SJCZBS": "I"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "12440977",
"timestamp": "2023-06-26T19:29:59.673000",
"streamPosition": "00****3.16",
"transactionId": "000***0006B0002",
"changeMask": "0FFF***FF",
"columnMask": "0F***FFFF",
"transactionEventCounter": 1,
"transactionLastEvent": false
}
}
}
方法一、不通过UDF函数实现
存在问题:字段值存在分隔符,例如‘,’ 则数据在落地的时候会发生错位现象。
该方法主要使用官网 transform-v2的各种转换插件进行实现,主要用到的插件有 Replace、Split以及Sql实现
ST脚本:(ybjc_qrqm.conf)
env {
execution.parallelism = 100
job.mode = "STREAMING"
job.name = "kafka2mysql_ybjc"
execution.checkpoint.interval = 60000
}
source {
Kafka {
result_table_name = "DZFP_***_QRQM1"
topic = "DZFP_***_QRQM"
bootstrap.servers = "centos1:19092,centos2:19092,centos3:19092"
schema = {
fields {
message = {
data = {
LSH = "string",
NSRSBH = "string",
QMYC = "string",
QMZ = "string",
QM_SJ = "string",
YX_BZ = "string",
ZGHQ_BZ = "string",
ZGHQ_SJ = "string",
SKSSQ = "string",
SWJG_DM = "string",
SWRY_DM = "string",
CZSJ = "string",
YNSRSBH = "string",
SJTBSJ = "string",
SJCZBS = "string"
}
}
}
}
start_mode = "earliest"
#start_mode.offsets = {
# 0 = 0
# 1 = 0
# 2 = 0
#}
kafka.config = {
auto.offset.reset = "earliest"
enable.auto.commit = "true"
# max.poll.interval.ms = 30000000
max.partition.fetch.bytes = "5242880"
session.timeout.ms = "30000"
max.poll.records = "100000"
}
}
}
transform {
Replace {
source_table_name = "DZFP_***_QRQM1"
result_table_name = "DZFP_***_QRQM2"
replace_field = "message"
pattern = "[["
replacement = ""
#is_regex = true
#replace_first = true
}
Replace {
source_table_name = "DZFP_***_QRQM2"
result_table_name = "DZFP_***_QRQM3"
replace_field = "message"
pattern = "]]"
replacement = ""
#is_regex = true
#replace_first = true
}
Split {
source_table_name = "DZFP_***_QRQM3"
result_table_name = "DZFP_***_QRQM4"
# 存在问题: 如果字段值存在分隔符 separator,则数据会错位
separator = ","
split_field = "message"
# 你的第一个字段包含在zwf5里面,,前五个占位符是固定的。
output_fields = [zwf1,zwf2,zwf3,zwf4,zwf5,nsrsbh,qmyc,qmz,qm_sj,yx_bz,zghq_bz,zghq_sj,skssq,swjg_dm ,swry_dm ,czsj ,ynsrsbh ,sjtbsj ,sjczbs]
}
sql{
source_table_name = "DZFP_***_QRQM4"
query = "select replace(zwf5 ,'fields=[','') as lsh,nsrsbh,trim(qmyc) as qmyc,qmz,qm_sj,yx_bz, zghq_bz,zghq_sj,skssq,swjg_dm ,swry_dm ,czsj ,ynsrsbh ,sjtbsj ,replace(sjczbs,']}]}','') as sjczbs from DZFP_DZDZ_QRPT_YWRZ_QRQM4 where skssq <> ' null'"
result_table_name = "DZFP_***_QRQM5"
}
}
sink {
Console {
source_table_name = "DZFP_***_QRQM5"
}
jdbc {
source_table_name = "DZFP_***_QRQM5"
url = "jdbc:mysql://localhost:3306/dbname?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
user = "user"
password = "pwd"
batch_size = 200000
database = "dbname"
table = "tablename"
generate_sink_sql = true
primary_keys = ["nsrsbh","skssq"]
}
}
正常写入数据是可以写入了。
写入成功如下:
● kafka源数据:
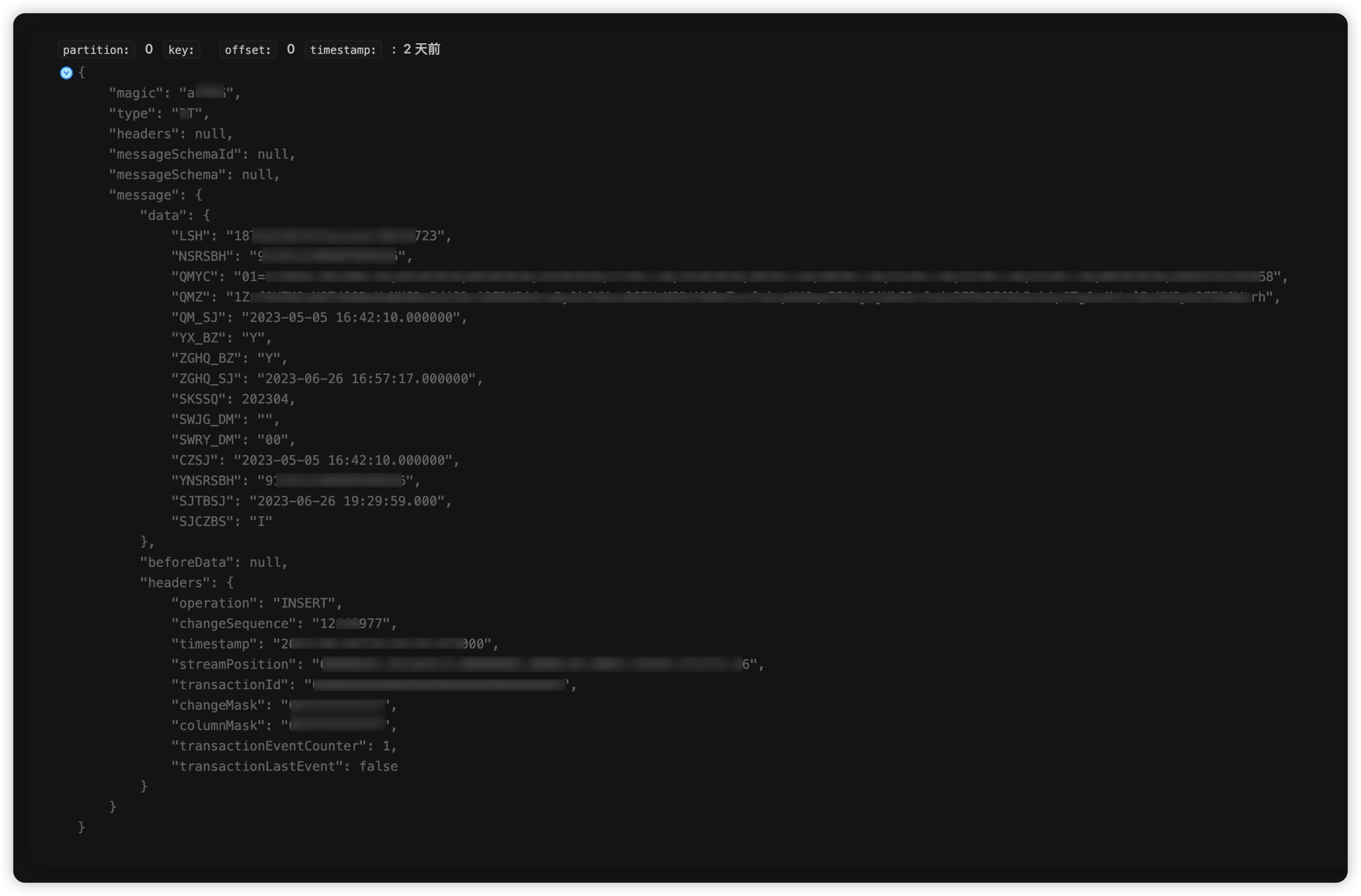
● tidb目标数据:

现在我们模拟给kafka发送一条数据,其中,SJTBSJ字段我在中间设置一个, 是逗号。
原始值:2023-06-26 19:29:59.000 更改之后的值2023-06-26 19:29:59.0,00
往topic生产一条数据命令
kafka-console-producer.sh --topic DZFP_***_QRQM --broker-list centos1:19092,centos2:19092,centos3:19092
发送如下:
"magic": "a***G",
"type": "D***",
"headers": null,
"messageSchemaId": null,
"messageSchema": null,
"message": {
"data": {
"LSH": "187eb13****l0214723",
"NSRSBH": "9134****XERG56",
"QMYC": "01*****135468",
"QMZ": "1Zr*****UYGy%2F5bOWtrh",
"QM_SJ": "2023-05-05 16:42:10.000000",
"YX_BZ": "Y",
"ZGHQ_BZ": "Y",
"ZGHQ_SJ": "2023-06-26 16:57:17.000000",
"SKSSQ": 202304,
"SWJG_DM": "",
"SWRY_DM": "00",
"CZSJ": "2023-05-05 16:42:10.000000",
"YNSRSBH": "9134****XERG56",
"SJTBSJ": "2023-06-26 19:29:59.0,00",
"SJCZBS": "I"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "12440977",
"timestamp": "2023-06-26T19:29:59.673000",
"streamPosition": "00****3.16",
"transactionId": "000***0006B0002",
"changeMask": "0FFF***FF",
"columnMask": "0F***FFFF",
"transactionEventCounter": 1,
"transactionLastEvent": false
}
}
}
写入之后,发现数据错位了。
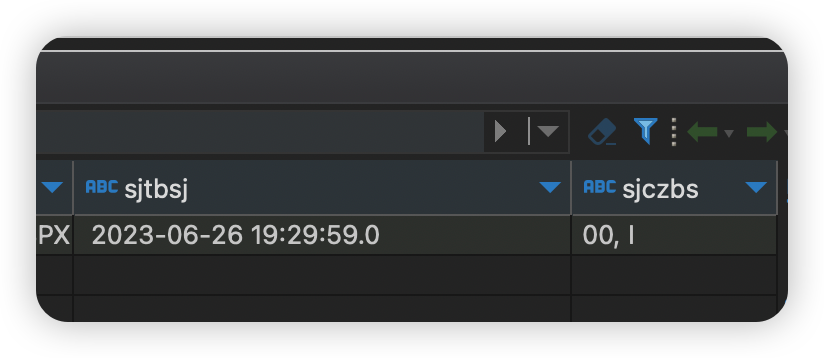
结论:其实这个问题线上还是能遇到的,比如地址字段里面含有逗号,备注信息里面含有逗号等等,这种现象是不可避免的,所以此种方案直接pass。对数据危害性极大!可以处理简单的数据,当做一种思路。
方法二:通过UDF函数实现
该方法通过UDF函数扩展(https://seatunnel.apache.org/docs/2.3.2/transform-v2/sql-udf)的方式,实现嵌套kafka source json源数据的解析。可以大大简化ST脚本的配置
ST脚本:(ybjc_qrqm_yh.conf)
env {
execution.parallelism = 5
job.mode = "STREAMING"
job.name = "kafka2mysql_ybjc_yh"
execution.checkpoint.interval = 60000
}
source {
Kafka {
result_table_name = "DZFP_***_QRQM1"
topic = "DZFP_***_QRQM"
bootstrap.servers = "centos1:19092,centos2:19092,centos3:19092"
schema = {
fields {
message = {
data = "map<string,string>"
}
}
}
start_mode = "earliest"
#start_mode.offsets = {
# 0 = 0
# 1 = 0
# 2 = 0
#}
kafka.config = {
auto.offset.reset = "earliest"
enable.auto.commit = "true"
# max.poll.interval.ms = 30000000
max.partition.fetch.bytes = "5242880"
session.timeout.ms = "30000"
max.poll.records = "100000"
}
}
}
transform {
sql{
source_table_name = "DZFP_***_QRQM1"
result_table_name = "DZFP_***_QRQM2"
# 这里的qdmx就是我自定义的UDF函数,具体实现下文详细讲解。。。
query = "select qdmx(message,'lsh') as lsh,qdmx(message,'nsrsbh') as nsrsbh,qdmx(message,'qmyc') as qmyc,qdmx(message,'qmz') as qmz,qdmx(message,'qm_sj') as qm_sj,qdmx(message,'yx_bz') as yx_bz,qdmx(message,'zghq_bz') as zghq_bz,qdmx(message,'zghq_sj') as zghq_sj,qdmx(message,'skssq') as skssq,qdmx(message,'swjg_dm') as swjg_dm,qdmx(message,'swry_dm') as swry_dm,qdmx(message,'czsj') as czsj,qdmx(message,'ynsrsbh') as ynsrsbh, qdmx(message,'sjtbsj') as sjtbsj,qdmx(message,'sjczbs') as sjczbs from DZFP_DZDZ_QRPT_YWRZ_QRQM1"
}
}
sink {
Console {
source_table_name = "DZFP_***_QRQM2"
}
jdbc {
source_table_name = "DZFP_***_QRQM2"
url = "jdbc:mysql://localhost:3306/dbname?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
user = "user"
password = "pwd"
batch_size = 200000
database = "dbname"
table = "tablename"
generate_sink_sql = true
primary_keys = ["nsrsbh","skssq"]
}
}
执行脚本:查看结果,发现并没有错位,还在原来的字段(sjtbsj)上面。
这种方法,是通过key获取value值。不会出现方法一中的按照逗号分割出现数据错位现象。
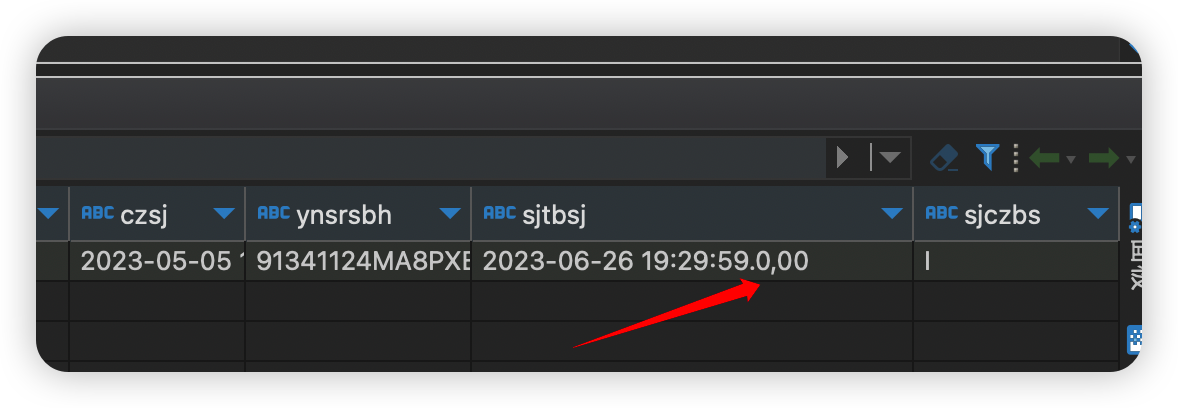
具体UDF函数编写如下。
maven引入如下:
<dependencies>
<dependency>
<groupId>org.apache.seatunnel</groupId>
<artifactId>seatunnel-transforms-v2</artifactId>
<version>2.3.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.seatunnel</groupId>
<artifactId>seatunnel-api</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service-annotations</artifactId>
<version>1.1.1</version>
<optional>true</optional>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.1.1</version>
<optional>true</optional>
<scope>compile</scope>
</dependency>
</dependencies>
UDF具体实现java代码如下:
package org.seatunnel.sqlUDF;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.google.auto.service.AutoService;
import org.apache.seatunnel.api.table.type.BasicType;
import org.apache.seatunnel.api.table.type.SeaTunnelDataType;
import org.apache.seatunnel.transform.sql.zeta.ZetaUDF;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@AutoService(ZetaUDF.class)
public class QdmxUDF implements ZetaUDF {
@Override
public String functionName() {
return "QDMX";
}
@Override
public SeaTunnelDataType<?> resultType(List<SeaTunnelDataType<?>> list) {
return BasicType.STRING_TYPE;
}
// list 参数实例:(也就是kafka 解析过来的数据)
//SeaTunnelRow{tableId=, kind=+I, fields=[{key1=value1,key2=value2,.....}]}
@Override
public Object evaluate(List<Object> list) {
String str = list.get(0).toString();
//1 Remove the prefix
str = StrUtil.replace(str, "SeaTunnelRow{tableId=, kind=+I, fields=[{", "");
//2 Remove the suffix
str = StrUtil.sub(str, -3, 0);
// 3 build Map key value
Map<String, String> map = parseToMap(str);
if ("null".equals(map.get(list.get(1).toString())))
return "";
// 4 return the value of the key
return map.get(list.get(1).toString());
}
public static Map<String, String> parseToMap(String input) {
Map<String, String> map = new HashMap<>();
// 去除大括号 在字符串阶段去除
// input = input.replaceAll("[{}]", "");
// 拆分键值对
String[] pairs = input.split(", ");
for (String pair : pairs) {
String[] keyValue = pair.split("=");
if (keyValue.length == 2) {
String key = keyValue[0].trim().toLowerCase();
String value = keyValue[1].trim();
map.put(key, value);
}
}
return map;
}
}
然后打包,打包命令如下:
mvn -T 8 clean install -DskipTests -Dcheckstyle.skip -Dmaven.javadoc.skip=true
查看META-INF/services, 看注解@AutoService 是否生成对应的spi接口:
如下:则打包成功!
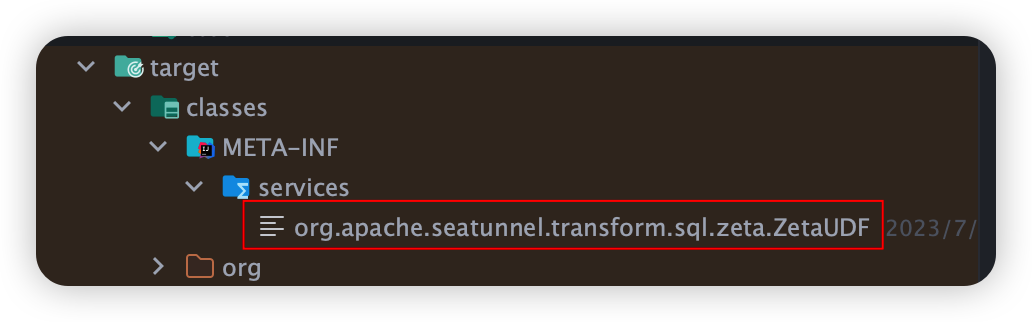
如果没有,则打包失败,UDF函数无法使用.
可以参考我的打包插件:
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-site-plugin</artifactId>
<version>3.7</version>
<dependencies>
<dependency>
<groupId>org.apache.maven.doxia</groupId>
<artifactId>doxia-site-renderer</artifactId>
<version>1.8</version>
</dependency>
</dependencies>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.1.1</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
</plugins>
</build>
最终打成的jar包放到 ${SEATUNNEL_HOME}/lib目录下,由于我的UDF函数引入了第三方jar包,也需要一并上传。如果是Zeta集群,需要重启Zeta集群才能生效。其他引擎实时生效。
最终上传成功如下:
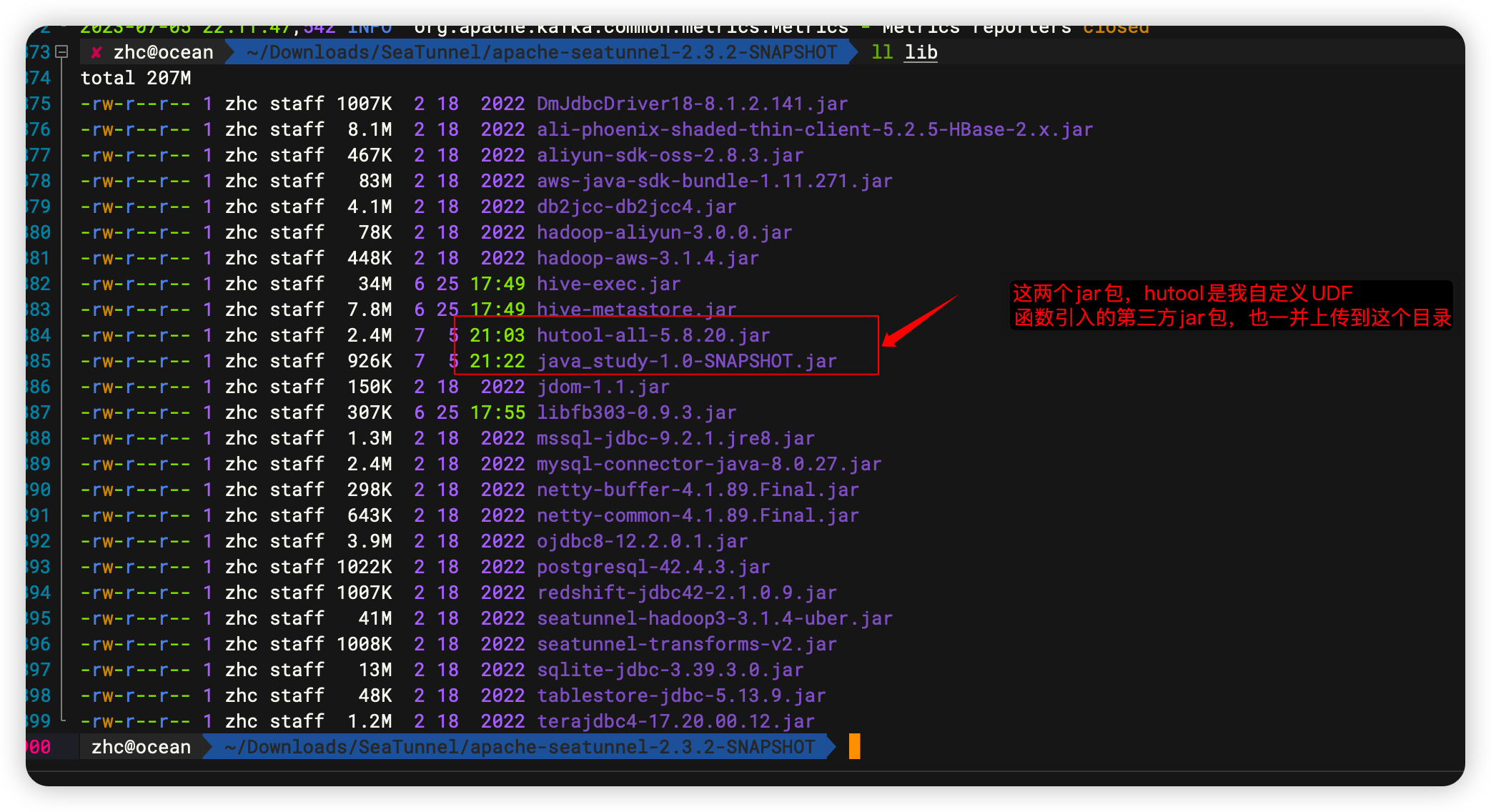
说明:这个hutool-all的jar包可以含在java_study这个项目里面,我图方便,上传了两个。
综上,推荐使用通过UDF函数扩展的方式,实现嵌套kafka source json源数据的解析。
本文由 白鲸开源 提供发布支持!
使用 Apache SeaTunnel 实现 Kafka Source 解析复杂Json 案例的更多相关文章
- 陈胡:Apache SeaTunnel实现 非CDC数据抽取实践
导读: 随着全球数据量的不断增长,越来越多的业务需要支撑高并发.高可用.可扩展.以及海量的数据存储,在这种情况下,适应各种场景的数据存储技术也不断的产生和发展.与此同时,各种数据库之间的同步与转化的需 ...
- Kafka设计解析(一)- Kafka背景及架构介绍
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/01/02/Kafka深度解析 背景介绍 Kafka简介 Kafka是一种分布式的,基于发布/订阅 ...
- Kafka深度解析
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/01/02/Kafka深度解析 背景介绍 Kafka简介 Kafka是一种分布式的,基于发布/订阅 ...
- 流式处理的新贵 Kafka Stream - Kafka设计解析(七)
原创文章,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/kafka/kafka_stream/ Kafka Stream背景 Ka ...
- Kafka设计解析(七)- Kafka Stream
本文介绍了Kafka Stream的背景,如Kafka Stream是什么,什么是流式计算,以及为什么要有Kafka Stream.接着介绍了Kafka Stream的整体架构,并行模型,状态存储,以 ...
- Kafka设计解析(二十二)Flink + Kafka 0.11端到端精确一次处理语义的实现
转载自 huxihx,原文链接 [译]Flink + Kafka 0.11端到端精确一次处理语义的实现 本文是翻译作品,作者是Piotr Nowojski和Michael Winters.前者是该方案 ...
- Kafka深度解析(如何在producer中指定partition)(转)
原文链接:Kafka深度解析 背景介绍 Kafka简介 Kafka是一种分布式的,基于发布/订阅的消息系统.主要设计目标如下: 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能 ...
- Kafka设计解析(七)Kafka Stream
转载自 技术世界,原文链接 Kafka设计解析(七)- Kafka Stream 本文介绍了Kafka Stream的背景,如Kafka Stream是什么,什么是流式计算,以及为什么要有Kafka ...
- Kafka设计解析(一)Kafka背景及架构介绍
转载自 技术世界,原文链接 Kafka设计解析(一)- Kafka背景及架构介绍 本文介绍了Kafka的创建背景,设计目标,使用消息系统的优势以及目前流行的消息系统对比.并介绍了Kafka的架构,Pr ...
- 大数据学习day36-----flume02--------1.avro source和kafka source 2. 拦截器(Interceptor) 3. channel详解 4 sink 5 slector(选择器)6 sink processor
1.avro source和kafka source 1.1 avro source avro source是通过监听一个网络端口来收数据,而且接受的数据必须是使用avro序列化框架序列化后的数据.a ...
随机推荐
- 洛谷 P5595 歌唱比赛
题目链接:歌唱比赛 思路 根据题目分析可得,假如小x的点赞数是123111,小y的点赞数是234111,则字符串的第4为到第6位结果都为Z,分别为对比(111,111),(11,11),(1,1),字 ...
- 推荐一个vs Nuget部署插件
写在前面 nuget部署工具, 无论是直接用web上传还是用命令行工具上传,还是其他第三方工具我都没找到满意,直到那天在群里提了一下,有位大佬说了个NuPackvs插件,用了下,感觉基本满足了我的需求 ...
- FPGA对EEPROM驱动控制(I2C协议)
本文摘要:本文首先对I2C协议的通信模式和AT24C16-EEPROM芯片时序控制进行分析和理解,设计了一个i2c通信方案.人为按下写操作按键后,FPGA(Altera EP4CE10)对EEPROM ...
- TGI 基准测试
本文主要探讨 TGI 的小兄弟 - TGI 基准测试工具.它能帮助我们超越简单的吞吐量指标,对 TGI 进行更全面的性能剖析,以更好地了解如何根据实际需求对服务进行调优并按需作出最佳的权衡及决策.如果 ...
- 如何从零开始集成DTM Android SDK
什么是动态标签管理? 动态标签管理(Dynamic Tag Manager,简称"DTM"),可让开发者快速配置更新测量代码及相关代码片段,可以基于Web界面轻松地进行分析.测量代 ...
- .NET Core MVC基础之返回文件类型
.NET Core MVC基础之返回文件类型 前言 上一篇文章讲了基础的返回类型,这篇文章讲解如何返回文件类型给浏览器下载. 系列文章 .NET MVC基础之页面传值方式 通过图片流来返回图片 返回类 ...
- 在win10上安装MTK驱动(附驱动下载链接)
参考:https://www.cnblogs.com/keepgoing707/p/4926171.html 背景 在调试MTK平台MT67XX的时候,发现安装preloader驱动装不上. 第三方i ...
- Linux 时间 与 定时器
背景 在学习 Linux 信号 有关知识中,提到了 alarm函数. 进程时间 (原文地址:https://www.cnblogs.com/clover-toeic/p/3845210.html) 进 ...
- NAT类型发现
一.前言 之前一篇文章中,提出了一个判断NAT类型的方案.该方案是自己研究设计的,比较粗糙.近期研读了关于STUN的一些协议标准,其中RFC3489中就包含了判断NAT类型的标准方案. 与自己设计的方 ...
- 谈谈你对MVVM开发模式和MVT的理解?
MVVM分为Model.View.ViewModel三者. Model 代表数据模型,数据和业务逻辑都在Model层中定义: View 代表UI视图,负责数据的展示: ViewModel 负责监听 M ...