spark性能调优03-shuffle调优
1、开启map端输出文件的合并机制
1.1 为什么要开启map端输出文件的合并机制
默认情况下,map端的每个task会为reduce端的每个task生成一个输出文件,reduce段的每个task拉取map端每个task生成的相应文件

开启后,map端只会在并行执行的task生成reduce端task数目的文件,下一批map端的task执行时,会复用首次生成的文件
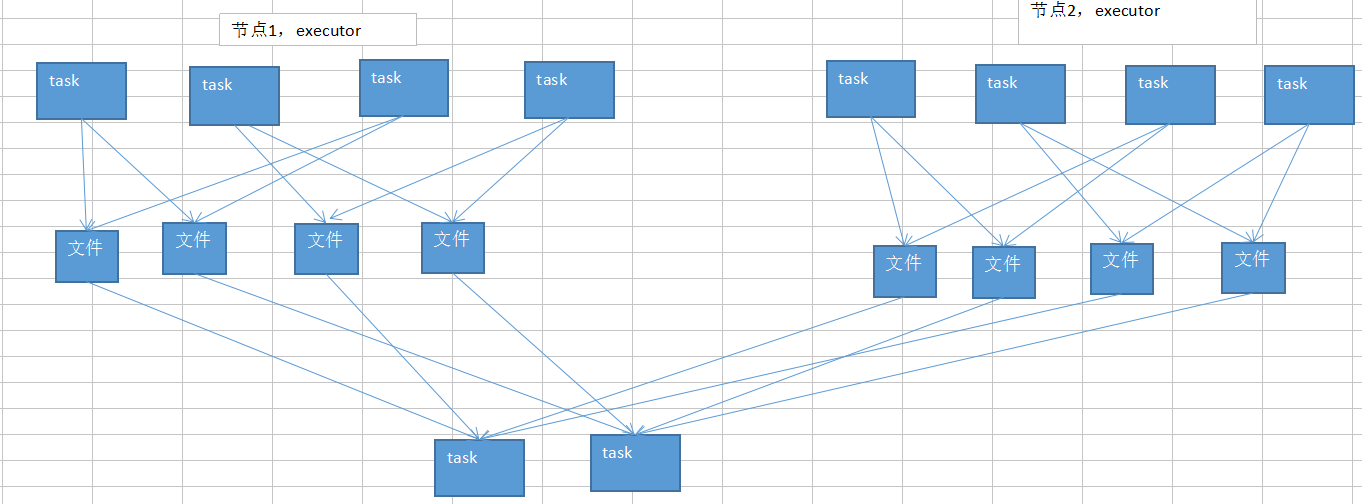
1.2 如何开启
//开启map端输出文件的合并机制
conf.set("spark.shuffle.consolidateFiles", "true");
2、调节map端内存缓冲区
2.1 为什么要调节map端内存缓冲区
默认情况下,shuffle的map task,输出的文件到内存缓冲区,当内存缓冲区满了,才会溢写spill操作到磁盘,如果该缓冲区比较小,而map端输出文件又比较大,会频繁的出现溢写到磁盘,影响性能。
2.2 如何调整
//设置map 端内存缓冲区大小(默认32k)
conf.set("spark.shuffle.file.buffer", "64k");
3、调节reduce端内存占比
3.1 为什么要调节reduce端内存占比
reduce task 在进行汇聚,聚合等操作时,实际上使用的是自己对应的executor内存,默认情况下executor分配给reduce进行聚合的内存比例是0.2,如果拉取的文件比较大,会频繁溢写到本地磁盘,影响性能。
3.2 如何调整
//设置reduce端内存占比
conf.set("spark.shuffle.memoryFraction", "0.4");
4、修改shuffle管理器
4.1 有哪些shuffle管理器
HashShuffleManager:1.2.x版本前的默认选择
SortShuffleManager:1.2.x版本之后的默认选择,会对每个task要处理的数据进行排序;同时,可以避免像HashShuffleManager那么默认去创建多份磁盘文件,而是一个task只会写入一个磁盘文件,不同reduce task需要的的数据使用offset来进行划分。
tungsten-sort(钨丝):1.5.x之后的出现,和SortShuffleManager相似,但是它本事实现了一套内存管理机制,性能有了很大的提高,而且避免了shuffle过程中产生大量的OOM、GC等相关问题。
4.2 如何选择
4.2.1 如果不需要排序,建议使用HashShuffleManager以提高性能
4.2.2 如果需要排序,建议使用SortShuffleManager
4.2.3 如果不需要排序,但是希望每个task输出的文件都合并到一个文件中,可以去调节bypassMergeThreshold这个阀值(默认为200),因为在合并文件的时候会进行排序,所以应该让该阀值大于reduce task数量。
4.2.4 如果需要排序,而且版本在1.5.x或者更高,可以尝试使用tungsten-sort
4.3 在项目中如何使用
//设置spark shuffle manager (hash,sort,tungsten-sort)
conf.set("spark.shuffle.manager", "tungsten-sort"); //设置文件合并的阀值
conf.set("spark.shuffle.sort.bypassMergeThreshold", "");
spark性能调优03-shuffle调优的更多相关文章
- Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优 • Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存. ...
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优
摘抄自https://tech.meituan.com/spark-tuning-pro.html 一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘I ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优[转]
概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优 ...
- Spark性能优化:开发调优篇
1.前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算 ...
- spark调优——Shuffle调优
在Spark任务运行过程中,如果shuffle的map端处理的数据量比较大,但是map端缓冲的大小是固定的,可能会出现map端缓冲数据频繁spill溢写到磁盘文件中的情况,使得性能非常低下,通过调节m ...
- Spark性能调优-高级篇
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能调优-基础篇
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
随机推荐
- postman—使用newman来执行postman脚本
我们知道postman是基于javascript语言编写的,而导出的json格式的postman脚本也无法直接在服务器运行,它需要在newman中执行(可以把newman看做postman脚本的运行环 ...
- DevOps之持续集成Jenkins+Gitlab
一.什么是DevOps DevOps(英文Development(开发)和Operations(技术运营)的组合)是一组过程.方法与系统的统称,DevOps是一组最佳实践强调(开发.运维.测试)在应用 ...
- JavaScript动态创建script标签并执行js代码
<script> //创建一个script标签 function loadScriptString(code) { var script = document.createElement( ...
- BZOJ 4289: PA2012 Tax Dijkstra + 查分
Description 给出一个N个点M条边的无向图,经过一个点的代价是进入和离开这个点的两条边的边权的较大值,求从起点1到点N的最小代价.起点的代价是离开起点的边的边权,终点的代价是进入终点的边的边 ...
- eclipse中使用maven搭建多模块项目
暂时参考:https://blog.csdn.net/u012343297/article/details/79883870
- Spring Boot教程(二十)开发Web应用(1)
静态资源访问 在我们开发Web应用的时候,需要引用大量的js.css.图片等静态资源. 默认配置 Spring Boot默认提供静态资源目录位置需置于classpath下,目录名需符合如下规则: /s ...
- 【机器学习速成宝典】模型篇05朴素贝叶斯【Naive Bayes】(Python版)
目录 先验概率与后验概率 条件概率公式.全概率公式.贝叶斯公式 什么是朴素贝叶斯(Naive Bayes) 拉普拉斯平滑(Laplace Smoothing) 应用:遇到连续变量怎么办?(多项式分布, ...
- maven的配置及使用
Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的软件项目管理工具. Apache官网下载maven 解压缩,配置环境变量: path路径:E:\apache-ma ...
- 目标双站定位仿真C++代码
point-position2 初步完善版. 不再使用eigen库,行列式直接计算得出结果.判断共面异面分别处理. 先提取双站获得图像的匹配特征点,由双站位置信息解析目标位置. // point-po ...
- 【python3】 抓取异常信息try/except
注意:老版本的Python,except语句写作"except Exception, e",Python 2.6后应写作"except Exception as e&qu ...