spark性能调优03-shuffle调优
1、开启map端输出文件的合并机制
1.1 为什么要开启map端输出文件的合并机制
默认情况下,map端的每个task会为reduce端的每个task生成一个输出文件,reduce段的每个task拉取map端每个task生成的相应文件

开启后,map端只会在并行执行的task生成reduce端task数目的文件,下一批map端的task执行时,会复用首次生成的文件
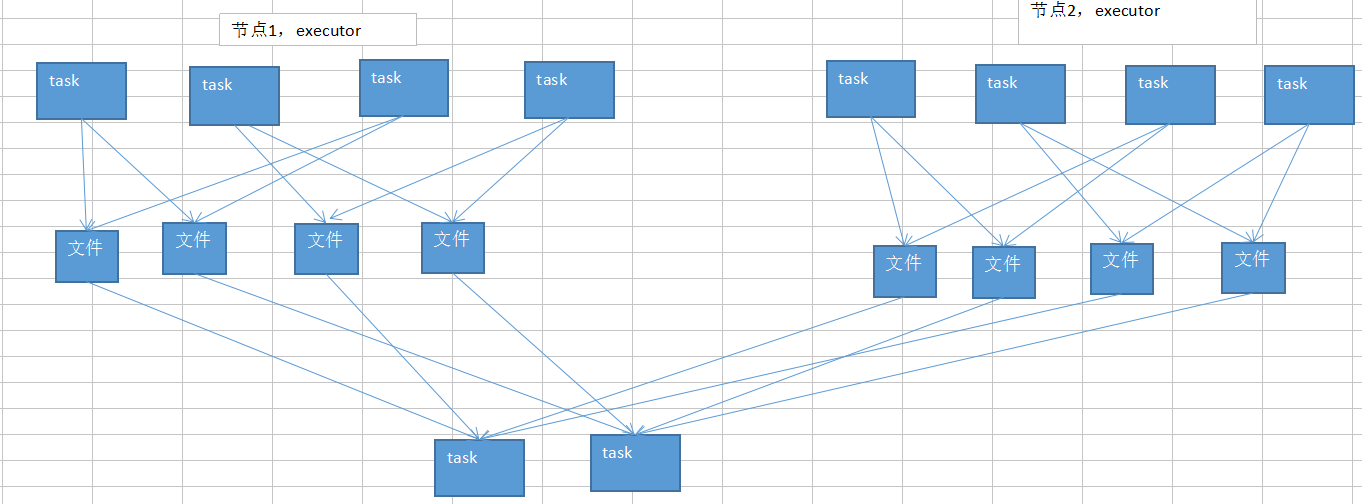
1.2 如何开启
//开启map端输出文件的合并机制
conf.set("spark.shuffle.consolidateFiles", "true");
2、调节map端内存缓冲区
2.1 为什么要调节map端内存缓冲区
默认情况下,shuffle的map task,输出的文件到内存缓冲区,当内存缓冲区满了,才会溢写spill操作到磁盘,如果该缓冲区比较小,而map端输出文件又比较大,会频繁的出现溢写到磁盘,影响性能。
2.2 如何调整
//设置map 端内存缓冲区大小(默认32k)
conf.set("spark.shuffle.file.buffer", "64k");
3、调节reduce端内存占比
3.1 为什么要调节reduce端内存占比
reduce task 在进行汇聚,聚合等操作时,实际上使用的是自己对应的executor内存,默认情况下executor分配给reduce进行聚合的内存比例是0.2,如果拉取的文件比较大,会频繁溢写到本地磁盘,影响性能。
3.2 如何调整
//设置reduce端内存占比
conf.set("spark.shuffle.memoryFraction", "0.4");
4、修改shuffle管理器
4.1 有哪些shuffle管理器
HashShuffleManager:1.2.x版本前的默认选择
SortShuffleManager:1.2.x版本之后的默认选择,会对每个task要处理的数据进行排序;同时,可以避免像HashShuffleManager那么默认去创建多份磁盘文件,而是一个task只会写入一个磁盘文件,不同reduce task需要的的数据使用offset来进行划分。
tungsten-sort(钨丝):1.5.x之后的出现,和SortShuffleManager相似,但是它本事实现了一套内存管理机制,性能有了很大的提高,而且避免了shuffle过程中产生大量的OOM、GC等相关问题。
4.2 如何选择
4.2.1 如果不需要排序,建议使用HashShuffleManager以提高性能
4.2.2 如果需要排序,建议使用SortShuffleManager
4.2.3 如果不需要排序,但是希望每个task输出的文件都合并到一个文件中,可以去调节bypassMergeThreshold这个阀值(默认为200),因为在合并文件的时候会进行排序,所以应该让该阀值大于reduce task数量。
4.2.4 如果需要排序,而且版本在1.5.x或者更高,可以尝试使用tungsten-sort
4.3 在项目中如何使用
//设置spark shuffle manager (hash,sort,tungsten-sort)
conf.set("spark.shuffle.manager", "tungsten-sort"); //设置文件合并的阀值
conf.set("spark.shuffle.sort.bypassMergeThreshold", "");
spark性能调优03-shuffle调优的更多相关文章
- Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优 • Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存. ...
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优
摘抄自https://tech.meituan.com/spark-tuning-pro.html 一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘I ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优[转]
概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优 ...
- Spark性能优化:开发调优篇
1.前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算 ...
- spark调优——Shuffle调优
在Spark任务运行过程中,如果shuffle的map端处理的数据量比较大,但是map端缓冲的大小是固定的,可能会出现map端缓冲数据频繁spill溢写到磁盘文件中的情况,使得性能非常低下,通过调节m ...
- Spark性能调优-高级篇
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能调优-基础篇
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
随机推荐
- Java 集合基础详细介绍
一.Java集合框架概述 集合.数组都是对多个数据进行存储操作的结构,简称Java容器.此时的存储,主要指的是内存层面的存储,不涉及到持久化的存储(.txt, .jpg, .avi,数据库中).Jav ...
- Composite UI Application Block(CAB)
序言 资料 https://www.cnblogs.com/lglruirui/archive/2010/06/21/1761737.html?tdsourcetag=s_pcqq_aiomsg ht ...
- Oracle --45 个非常有用的 Oracle 查询语句
日期/时间 相关查询 1.获取当前月份的第一天运行这个命令能快速返回当前月份的第一天.你可以用任何的日期值替换 “SYSDATE”来指定查询的日期.SELECT TRUNC (SYSDATE, 'MO ...
- ElasticSearch的介绍
1.ELK 1.1 集中式日志系统 日志,对于任何系统来说都是及其重要的组成部分.在计算机系统里面,更是如此.但是由于现在的计算机系统大多比较复杂,很多系统都不是在一个地方,甚至都是跨国界的:即使是在 ...
- 后盾网lavarel视频项目---1、数据迁移
后盾网lavarel视频项目---1.数据迁移 一.总结 一句话总结: 1.lavarel的数据迁移比较简单,就是用php来创建数据表 2.创建迁移文件:php artisan make:migrat ...
- linux可用的跨平台C# .net standard2.0 写的高性能socket框架
能在window(IOCP)/linux(epoll)运行,基于C# .net standard2.0 写的socket框架,可使用于.net Framework/dotnet core程序集,.使用 ...
- 看天猫EDM营销学企业EDM营销
众所周知,天猫EDM营销在业内算做的风生水起,相当不错.本文就由天猫EDM营销来教大家学做企业EDM营销. 1.邮件内容相对精美,并都带有天猫tmall各个栏目的链接,并且对于重点推出了的几个店铺给出 ...
- 2018.03.29 python-pandas transform/apply 的使用
#一般化的groupby方法:apply df = pd.DataFrame({'data1':np.random.rand(5), 'data2':np.random.rand(5), 'key1' ...
- 【转载】inno setup 水波纹效果,检测安装vcredist_x86.exe等
以下inno setup脚本,实现了:1.水波纹效果 2.安装时检测是否安装其他版本,并在欢迎页面添加文字提示 4.检测安装vcredist_x86.exe 3.卸载时添加提示 ; 脚本由 Inno ...
- Oracle不完全恢复-主动恢复和incarnation/RMAN-20208/RMAN-06004
12.3 主动恢复 主动不完全恢复是将数据库“撤回”到从前的传统方法,主要用来撤销认为修改.一般需要先判断PIT点的时间或SCN --1 重启db到mount状态 --2 用restore将所有的数据 ...