Python爬虫实战——反爬策略之代理IP【无忧代理】
一般情况下,我并不建议使用自己的IP来爬取网站,而是会使用代理IP。
原因很简单:爬虫一般都有很高的访问频率,当服务器监测到某个IP以过高的访问频率在进行访问,它便会认为这个IP是一只“爬虫”,进而封锁了我们的IP。
那我们爬虫对IP代理的要求是什么呢?
- 1、代理IP数量较多,可以减低被封锁的概率;
- 2、IP生命周期较短,因为没钱o(´^`)o。
接下来,就讲一下从购买代理IP到urllib配置代理IP的全过程。
购买代理IP:
代理IP的中间商有很多,我们以无忧代理为例。

- 这里共有4套餐,我们选择第一个“¥10”套餐,进入详情界面:

- 竟然更便宜了,只要8.5???买!
(我真的没拿无忧代理的广告费......) - 购买成功之后,我们点击“创建API接口”:
- 获取HTTP爬虫代理IP的API链接:

配置代理IP:
- 我们先调用下接口试一下:
import urllib.request as ur
proxy_address = ur.urlopen('http://api.ip.data5u.com/dynamic/get.html?order=d314e5e5e19b0dfd19762f98308114ba&sep=4').read()
print(proxy_address)
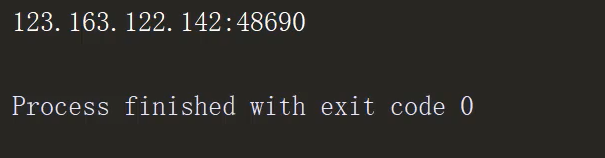
- 由于返回结果为字节,我们还需对其进行
utf-8格式转换,以及去空格:
proxy_address = proxy_address.decode('utf-8').strip()
输出如下:
- 创建proxy_handler:
proxy_handler = ur.ProxyHandler(
{
'http': proxy_address
}
)
- 新建opener对象:
proxy_opener = ur.build_opener(proxy_handler)
- 使用代理IP进行访问并输出:
request = ur.Request(url='https://edu.csdn.net/')
# open == urlreponse,只是进行了代理IP封装
reponse = proxy_opener.open(request).read().decode('utf-8')
print(reponse)
输出如下:

全文完整代码:
import urllib.request as ur
proxy_address = ur.urlopen('http://api.ip.data5u.com/dynamic/get.html?order=d314e5e5e19b0dfd19762f98308114ba&sep=4').read().decode('utf-8').strip()
# print(proxy_address)
# 创建proxy_handler
proxy_handler = ur.ProxyHandler(
{
'http': proxy_address
}
)
# 新建opener对象
proxy_opener = ur.build_opener(proxy_handler)
request = ur.Request(url='https://edu.csdn.net/')
# open == urlreponse,只是进行了代理IP封装
reponse = proxy_opener.open(request).read().decode('utf-8')
print(reponse)
为我心爱的女孩~~
Python爬虫实战——反爬策略之代理IP【无忧代理】的更多相关文章
- Python爬虫实战——反爬策略之模拟登录【CSDN】
在<Python爬虫实战-- Request对象之header伪装策略>中,我们就已经讲到:=="在header当中,我们经常会添加两个参数--cookie 和 User-Age ...
- 抖音爬虫教程,python爬虫采集反爬策略
一.爬虫与反爬简介 爬虫就是我们利用某种程序代替人工批量读取.获取网站上的资料信息.而反爬则是跟爬虫的对立面,是竭尽全力阻止非人为的采集网站信息,二者相生相克,水火不容,到目前为止大部分的网站都还是可 ...
- Python爬虫实战——反爬机制的解决策略【阿里】
这一次呢,让我们来试一下"CSDN热门文章的抓取". 话不多说,让我们直接进入CSND官网. (其实是因为我被阿里的反爬磨到没脾气,不想说话--) 一.URL分析 输入" ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- 原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我 注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的. 爬虫 ...
- python爬虫--cookie反爬处理
Cookies的处理 作用 保存客户端的相关状态 在爬虫中如果遇到了cookie的反爬如何处理? 手动处理 在抓包工具中捕获cookie,将其封装在headers中 应用场景:cookie没有有效时长 ...
- Python爬虫-字体反爬-猫眼国内票房榜
偶然间知道到了字体反爬这个东西, 所以决定了解一下. 目标: https://maoyan.com/board/1 问题: 类似下图中的票房数字无法获取, 直接复制粘贴的话会显示 □ 等无法识别的字 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
随机推荐
- python中map的排序以及取出map中取最大最小值
map排序: 1.按key排序: items=dict.items() items.sort() sorted(dict.items(),key=lambda x:x[0],reverse=False ...
- oracle 中||
oracle里双竖线是字符串连接运算符!
- 如何在Mac上将视频刻录到DVD / ISO文件
如果您希望将喜爱的视频转换为DVD / Blu-ray光盘以进行物理备份或播放,则Mac版Wondershare UniConverter可以专业地完成任务.今天的教程就是如何在Mac上轻松刻录DVD ...
- 【和孩子一起学编程】 python笔记--第二天
第六章 GUI:用户图形界面(graphical user interface) 安装easygui:打开cmd命令窗口,输入:pip install easygui 利用msgbox()函数创建一个 ...
- spring boot 依赖配置
虽然springboot号称是零配置 配置文件确实不需要,但是 依赖还是要有的 <parent> <groupId>org.springframework.boo ...
- 深度解析双十一背后的阿里云 Redis 服务
摘要: Redis是一个使用范围很广的NOSQL数据库,阿里云Redis同时在公有云和阿里集团内部进行服务,本文介绍了阿里云Redis双11的一些业务场景:微淘社区之亿级关系链存储.天猫直播之评论商品 ...
- 四. jenkins部署springboot项目(1)--window环境
前提:jenkins和springboot运行在同一台机器 springboot项目使用git和maven jenkins所需的插件如Maven,Git等这里就不再详述. 1.jenkins配置git ...
- JS-jQuery:百科
ylbtech-JS-jQuery:百科 jQuery是一个快速.简洁的JavaScript框架,是继Prototype之后又一个优秀的JavaScript代码库(或JavaScript框架).jQu ...
- 27. Unittest单元测试框架的介绍与使用
unittest单元测试框架 先贴一下unittest官网地址.unittest文档开头介绍了四个重要的概念:test fixture,test case, test suite, test runn ...
- Hello cnblogs!
console.log('Hello cnblogs')!