elasticsearch 基础 —— 处理冲突及乐观并发控制
处理冲突
当我们使用 index API 更新文档 ,可以一次性读取原始文档,做我们的修改,然后重新索引 整个文档 。 最近的索引请求将获胜:无论最后哪一个文档被索引,都将被唯一存储在 Elasticsearch 中。如果其他人同时更改这个文档,他们的更改将丢失。
很多时候这是没有问题的。也许我们的主数据存储是一个关系型数据库,我们只是将数据复制到 Elasticsearch 中并使其可被搜索。 也许两个人同时更改相同的文档的几率很小。或者对于我们的业务来说偶尔丢失更改并不是很严重的问题。
但有时丢失了一个变更就是 非常严重的 。试想我们使用 Elasticsearch 存储我们网上商城商品库存的数量, 每次我们卖一个商品的时候,我们在 Elasticsearch 中将库存数量减少。
有一天,管理层决定做一次促销。突然地,我们一秒要卖好几个商品。 假设有两个 web 程序并行运行,每一个都同时处理所有商品的销售,如图 图 7 “Consequence of no concurrency control” 所示。
图 7. Consequence of no concurrency control
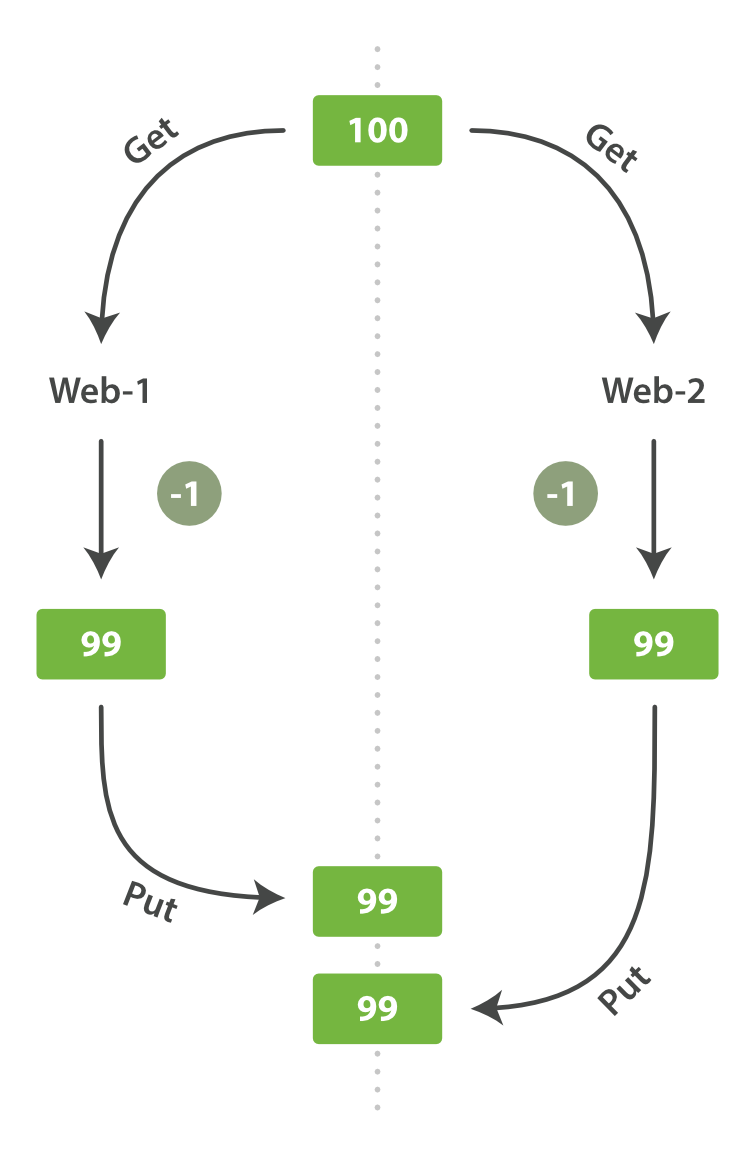
web_1 对 stock_count 所做的更改已经丢失,因为 web_2 不知道它的 stock_count 的拷贝已经过期。 结果我们会认为有超过商品的实际数量的库存,因为卖给顾客的库存商品并不存在,我们将让他们非常失望。
变更越频繁,读数据和更新数据的间隙越长,也就越可能丢失变更。
在数据库领域中,有两种方法通常被用来确保并发更新时变更不会丢失:
悲观并发控制
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
乐观并发控制
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
乐观并发控制
Elasticsearch 是分布式的。当文档创建、更新或删除时, 新版本的文档必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许 顺序是乱的。 Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前讨论 index , GET 和 delete 请求时,我们指出每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。 Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version 号来达到这个目的。 如果该版本不是当前版本号,我们的请求将会失败。
让我们创建一个新的博客文章:
PUT /website/blog/1/_create
{
"title": "My first blog entry",
"text": "Just trying this out..."
}响应体告诉我们,这个新创建的文档 _version 版本号是 1 。现在假设我们想编辑这个文档:我们加载其数据到 web 表单中, 做一些修改,然后保存新的版本。
首先我们检索文档:
GET /website/blog/1响应体包含相同的 _version 版本号 1 :
{
"_index" : "website",
"_type" : "blog",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"title": "My first blog entry",
"text": "Just trying this out..."
}
}
现在,当我们尝试通过重建文档的索引来保存修改,我们指定 version 为我们的修改会被应用的版本:
PUT /website/blog/1?version=1

{
"title": "My first blog entry",
"text": "Starting to get the hang of this..."
}
_version为1时,本次更新才能成功。
此请求成功,并且响应体告诉我们 _version 已经递增到 2 :
{
"_index": "website",
"_type": "blog",
"_id": "1",
"_version": 2
"created": false
}
然而,如果我们重新运行相同的索引请求,仍然指定 version=1 , Elasticsearch 返回 409 ConflictHTTP 响应码,和一个如下所示的响应体:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
}
],
"type": "version_conflict_engine_exception",
"reason": "[blog][1]: version conflict, current [2], provided [1]",
"index": "website",
"shard": "3"
},
"status": 409
}
这告诉我们在 Elasticsearch 中这个文档的当前 _version 号是 2 ,但我们指定的更新版本号为 1 。
我们现在怎么做取决于我们的应用需求。我们可以告诉用户说其他人已经修改了文档,并且在再次保存之前检查这些修改内容。 或者,在之前的商品 stock_count 场景,我们可以获取到最新的文档并尝试重新应用这些修改。
所有文档的更新或删除 API,都可以接受 version 参数,这允许你在代码中使用乐观的并发控制,这是一种明智的做法。
通过外部系统使用版本控制
一个常见的设置是使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索, 这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch ,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号 — 或一个能作为版本号的字段值比如 timestamp — 那么你就可以在 Elasticsearch 中通过增加 version_type=external 到查询字符串的方式重用这些相同的版本号, 版本号必须是大于零的整数, 且小于 9.2E+18 — 一个 Java 中 long 类型的正值。
外部版本号的处理方式和我们之前讨论的内部版本号的处理方式有些不同, Elasticsearch 不是检查当前 _version 和请求中指定的版本号是否相同, 而是检查当前 _version 是否 小于 指定的版本号。 如果请求成功,外部的版本号作为文档的新 _version 进行存储。
外部版本号不仅在索引和删除请求是可以指定,而且在 创建 新文档时也可以指定。
例如,要创建一个新的具有外部版本号 5 的博客文章,我们可以按以下方法进行:
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
} 在响应中,我们能看到当前的 _version 版本号是 5 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 5,
"created": true
}
现在我们更新这个文档,指定一个新的 version 号是 10 :
PUT /website/blog/2?version=10&version_type=external
{
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}请求成功并将当前 _version 设为 10 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 10,
"created": false
}
如果你要重新运行此请求时,它将会失败,并返回像我们之前看到的同样的冲突错误, 因为指定的外部版本号不大于 Elasticsearch 的当前版本号。
使用外部版本类型时,系统会检查传递给索引请求的版本号是否大于当前存储文档的版本号,而不是检查匹配的版本号。如果为true,则将对文档进行索引并使用新的版本号。如果提供的值小于或等于存储文档的版本号,则会发生版本冲突,索引操作将失败。
外部版本控制支持值0作为有效版本号。这允许版本与外部版本控制系统同步,其中版本号从0开始而不是1。版本号等于0的文档既不能使用查询来更新,也不能用查询来删除,只要它们的版本号等于0就有这个副作用。
索引类型
在上面解释的内部*外部版本类型旁边,Elasticsearch还支持特定用例的其他类型。这里是不同版本类型及其语义的概述。
- internal
仅当给定版本与存储的文档的版本相同时才索引文档。 - external或external_gt
仅在给定版本严格高于所存储文档的版本或如果没有现有文档时索引文档。给定版本将用作新版本,并与新文档一起存储。提供的版本必须是非负长数字。 - external_gte
仅在给定版本等于或高于存储文档的版本时索引文档。如果没有现有文档,操作也将成功。给定版本将用作新版本,并与新文档一起存储。提供的版本必须是非负长数字。
elasticsearch 基础 —— 处理冲突及乐观并发控制的更多相关文章
- Elasticsearch基础知识要点QA
前言:本文为学习整理实践他人成果的记录型博客.在此统一感谢各原作者,如果你对基础知识不甚了解,可以通过查看Elasticsearch权威指南中文版, 此处注意你的elasticsearch版本,版本不 ...
- elasticsearch基础知识杂记
日常工作中用到的ES相关基础知识和总结.不足之处请指正,会持续更新. 1.集群的健康状况为 yellow 则表示全部主分片都正常运行(集群可以正常服务所有请求),但是 副本 分片没有全部处在正常状态. ...
- 第18/24周 乐观并发控制(Optimistic Concurrency)
大家好,欢迎回到性能调优培训.上个星期我通过讨论悲观并发模式拉开了第5个月培训的序幕.今天我们继续,讨论下乐观并发模式(Optimistic Concurrency). 行版本(Row Version ...
- Entity Framework 乐观并发控制
一.背景 我们知道,为了防止并发而出现脏读脏写的情况,可以使用Lock语句关键字,这属于悲观并发控制的一种技术,,但在分布式站点下,锁的作用几乎不存在,因为虽然锁住了A服务器的实例对象,但B服务器上的 ...
- ElasticSearch基础知识讲解
第一节 ElasticSearch概述 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTfull web接口.ElasticSea ...
- ELK(elasticsearch+kibana+logstash)搜索引擎(二): elasticsearch基础教程
1.elasticsearch的结构 首先elasticsearch目前的结构为 /index/type/id id对应的就是存储的文档ID,elasticsearch一般将数据以JSON格式存储. ...
- Elasticsearch 基础入门
原文地址:Elasticsearch 基础入门 博客地址:http://www.extlight.com 一.什么是 ElasticSearch ElasticSearch是一个基于 Lucene 的 ...
- .NET:通过 CAS 来理解数据库乐观并发控制,顺便给出无锁的 RingBuffer。
背景 大多数企业开发人员都理解数据库乐观并发控制,不过很少有人听说过 CAS(我去年才听说这个概念),CAS 是多线程乐观并发控制策略的一种,一些无锁的支持并发的数据结构都会使用到 CAS,本文对比 ...
- ElasticSearch 基础 1
ElasticSearch 基础=============================== 索引创建 ========================== 1. RESTFUL APIAPI 基本 ...
随机推荐
- JS基础入门篇(三)— for循环,取余,取整。
1.for循环 1.for的基本简介 作用: 根据一定的条件,重复地执行一行或多行代码 语法: for( 初始化 ; 判断条件 ; 条件改变 ){ 代码块 } 2.for循环的执行顺序 <bod ...
- 使用Node,Vue和ElasticSearch构建实时搜索引擎
(译者注:相关阅读:node.js,vue.js,Elasticsearch) 介绍 Elasticsearch是一个分布式的RESTful搜索和分析引擎,能够解决越来越多的用例. Elasticse ...
- 快速开发框架下载地址(github)
eladmin:https://github.com/elunez/eladmin bootDo:https://www.oschina.net/p/bootdo
- vsto c# 获取word里面的图片并保存
internal void GetEmbeddedImages() { ; Document doc = Globals.ThisAddIn.Application.ActiveDocument; f ...
- 【leetcode】1081. Smallest Subsequence of Distinct Characters
题目如下: Return the lexicographically smallest subsequence of text that contains all the distinct chara ...
- 对Promise的研究4
Promise.reject() Promise.reject(reason)方法也会返回一个新的 Promise 实例,该实例的状态为rejected. const p = Promise.reje ...
- centos 配置vlan
https://access.redhat.com/documentation/zh-cn/red_hat_enterprise_linux/7/html/networking_guide/sec-c ...
- CSS中浮动属性float及清除浮动
1.float属性 CSS 的 Float(浮动),会使元素向左或向右移动,由于浮动的元素会脱离文档流,所以它后面的元素会重新排列. 浮动元素之后的那些元素将会围绕它,而浮动元素之前的元素将不会受到影 ...
- mysql 1067 - Invalid default value for 'addtime'错误处理
错误描述 TABLE `bota_payment_closing` ( `id` int(11) NOT NULL AUTO_INCREMENT, `monthly` varchar(8) NOT N ...
- char* 和 cha[]
char* s1 = "hello";//字符串常量 s是一个保存了字符串首地址的指针变量,同时也是字符串的名字,s的内容是第一个字符的地址,当s指向常量字符串时候,内容不能改变( ...