《SQL Server 2012 T-SQL基础》读书笔记 - 7.进阶查询
Chapter 7 Beyond the Fundamentals of Querying
window function是什么呢?就是你SELECT出来一个结果集,然后对于每一行,你都想给它对应一个标量(a scalar),而这个标量是通过a subset of rows计算得到的,而这个a subset of the rows其实就是你得到的结果集里面的一个subset(子集)。所以说就是把每一行都对应a subset of the rows,而这个对应关系通过OVER指定。举个例子:
SELECT empid, ordermonth, val,
SUM(val) OVER(PARTITION BY empid
ORDER BY ordermonth
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS runval
FROM Sales.EmpOrders;
结果:

讲解一下。OVER子句里面有三个部分:partitioning, ordering, and framing。partitioning就是PARTITION BY,其实就是分组,类似GROUP BY,如果不指定PARTITION BY,那么每行的对应就是整个结果集。ordering对应ORDER BY,但这里的ORDER BY跟数据展示没关系,它只是为了这个window函数服务的,也就是有些具体的计算需要根据顺序来计算。最后的ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW对应framing,UNBOUNDED PRECEDING表示分组的开始。所以说,比如对于上面的empid = 1的那几行,runval是根据ordermonth不断累积的。
Ranking Window Functions:
SELECT orderid, custid, val,
ROW_NUMBER() OVER(ORDER BY val) AS rownum,
RANK() OVER(ORDER BY val) AS rank,
DENSE_RANK() OVER(ORDER BY val) AS dense_rank,
NTILE(10) OVER(ORDER BY val) AS ntile
FROM Sales.OrderValues
ORDER BY val;
结果:
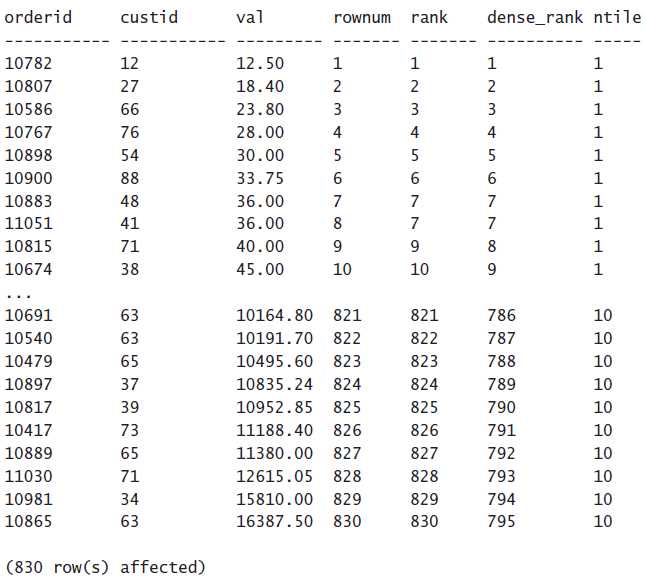
注意上面的val列里面有两行都为36,那么这时候ROW_NUMBER会给他们分配不同的编号。但是RANK和DENSE_RANK会给他们分配相同的编号,rank编号为9的意思是有8行的val比这行的val要小,dense rank为9的意思是有distinct的8行的val比这行的val要小。
NTILE(10)意思就是把结果分成十组,因为一共有830行,所以每组有83行。
注意,SELECT中如果用了DISTINCT,那么DISTINCT是在window函数之后进行的,如果你同时用了DISTINCT和ROW_NUMBER,那么你还不如不要这个DISTINCT。
Offset Window Functions:
先举个栗子:
SELECT custid, orderid, val,
LAG(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS prevval,
LEAD(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS nextval
FROM Sales.OrderValues;
结果:

讲解一下:PARTITION BY custid就相当于把范围定在custid是一样的这些行,LAG就是取当前行的前一行,LEAD就是取当前行的后一行,因为前后这个概念需要顺序作为前提,所以有个ORDER BY。其实LAG和LEAD还有两个可选参数,比如LAG(val, 3, 0)的意思就是,取向后的第三行,如果没有这样一行,就返回0。默认是LAG(column,1,NULL)。
然后是FIRST_VALUE和LAST_VALUE的例子:
SELECT custid, orderid, val,
FIRST_VALUE(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS firstval,
LAST_VALUE(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) AS lastval
FROM Sales.OrderValues
ORDER BY custid, orderdate, orderid;
结果:

讲解一下:以FIRST_VALUE为例,其实就是返回这个分组中某个范围里的第一行,而那个名叫ROWS的window frame unit,我的理解就是继续缩小范围,比如ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW意思就是把范围定在分组的开始到当前行,ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING就是把范围定在当前行到分组的结束。如果不指定这样一个window frame unit,默认的范围的右边界是当前行。而且作者说应当显示指定一个window frame unit。
Aggregate Window Functions:
在SQL Server2012之前,window aggregate functions只支持PARTITION,举个例子:
SELECT orderid, custid, val,
SUM(val) OVER() AS totalvalue,
SUM(val) OVER(PARTITION BY custid) AS custtotalvalue
FROM Sales.OrderValues;
结果:

之前讲过,如果你不指定PARTITION那么范围就是整个结果集。当然,一般都会用window function的值和当前值做一个计算,比如:
SELECT orderid, custid, val,
100. * val / SUM(val) OVER() AS pctall,
100. * val / SUM(val) OVER(PARTITION BY custid) AS pctcust
FROM Sales.OrderValues;
从SQL Server 2012开始,聚合函数支持ordering和framing,例子参考这一章最开始的那个例子。其中的framing部分可以用很多种变化,比如ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING意思就是把范围缩小到当前行向前的两行和向后的一行之间。
考虑以下SQL:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid, custid
UNION ALL
SELECT empid, NULL, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY empid
UNION ALL
SELECT NULL, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY custid
UNION ALL
SELECT NULL, NULL, SUM(qty) AS sumqty
FROM dbo.Orders;
结果:

我们定义,上面被UNION ALL的四个query分别定义了四个grouping sets:(empid, custid)、(empid)、(custid),以及一个空的 grouping set: ()。但是你这么写很不好,第一是代码很长,第二是性能很差。咋整?用下面这种语法:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY
GROUPING SETS
(
(empid, custid),
(empid),
(custid),
()
);
这种语法在逻辑上跟上面那个是一样的。但是SQL Server会做优化,提升性能。
还可以用CUBE,同构CUBE你可以得到基于输入参数的所有可能的grouping sets,比如CUBE(a, b, c)就相当于GROUPING SETS( (a, b, c), (a, b), (a, c), (b, c), (a), (b), (c), () )
语法如下:
SELECT empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid, custid);
ROLLUP类似,比如ROLLUP(a, b, c)就等于GROUPING SETS( (a, b, c), (a, b), (a), () )
有这么一个函数GROUPING:
SELECT
GROUPING(empid) AS grpemp,
GROUPING(custid) AS grpcust,
empid, custid, SUM(qty) AS sumqty
FROM dbo.Orders
GROUP BY CUBE(empid, custid);
结果:

比如GROUPING(empid)的意思就是:当前这一行,如果empid是作为grouping set中的一员的话,就返回0,否则返回1。
还有个类似的函数GROUPING_ID,它可以接受所有你用在grouping sets里面的元素作为参数,然后返回一个整数(用二进制来看),每一位都代表一个你的元素,0代表是当前grouping set一员,1代表不是。比如你GROUPING_ID(a, b, c, d),如果当前的分组是(a,c)那么就返回0101(二进制)。
《SQL Server 2012 T-SQL基础》读书笔记 - 7.进阶查询的更多相关文章
- SQL Server Window Function 窗体函数读书笔记二 - A Detailed Look at Window Functions
这一章主要是介绍 窗体中的 Aggregate 函数, Rank 函数, Distribution 函数以及 Offset 函数. Window Aggregate 函数 Window Aggrega ...
- SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第1部分)
为了缩小读取操作所涉及范围,本文首先着眼于简单的SELECT查询,然后引入执行更新操作有关的附加过程.最后你会读到,优化性能时SQLServer使用还原工具的相关术语和流程. 关系和存储引擎 如图所示 ...
- SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第2部分)
计划缓存(Plan Cache) 如果SQL Server已经找到一个好的方式去执行一段代码时,应该把它作为随后的请求重用,因为生成执行计划是耗费时间且资源密集的,这样做是有有意义的. 如果没找到被缓 ...
- SQL Sever 各版本下载 SQL Server 2012下载SQL Server 2008下载SQL Server 2005
SQL Server 2012SQL Server 2012 开发版(DVD)(X64,X86)(中文简体)ed2k://|file|cn_sql_server_2012_developer_edit ...
- sql server 2012 导出sql文件
导出表数据和表结构sql文件 在工作中,经常需要导出某个数据库中,某些表数据:或者,需要对某个表的结构,数据进行修改的时候,就需要在数据库中导出表的sql结构,包括该表的建表语句和数据存储语句!在这个 ...
- SQL Server Window Function 窗体函数读书笔记一 - SQL Windowing
SQL Server 窗体函数主要用来处理由 OVER 子句定义的行集, 主要用来分析和处理 Running totals Moving averages Gaps and islands 先看一个简 ...
- SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第3部分)(完结)
一个简单的更新查询 现在应该知道只读取数据的查询生命周期,下一步来认定当你需要更新数据时会发生什么.这个部分通过看一个简单的UPDATE查询,修改刚才例子里读取的数据,来回答. 庆幸的是,直到存取方法 ...
- SQL Server 2012 - 动态SQL查询
动态SQL的两种执行方式:EXEC @sql 和 EXEC sys.sp_executesql @sql DECLARE @c_ids VARCHAR(200) SET @c_ids ='1,2' - ...
- SQL Server 2012 - 数据库的基础操作
数据库基本操作 --新建数据库卡 use master go create database SchoolDB on ( Name=SchoolDB, FileName='D;\DB\SchoolDB ...
随机推荐
- [Python3] 003 变量类型概述 & 数字类型详叙
目录 0. 变量类型概述 1. 数字类型详叙 1.1 整数 1.1.1 常用进制 1.1.2 少废话,上例子 1.2 浮点数 1.2.1 使用浮点数时可以"偷懒" 1.2.2 科学 ...
- HNUSTOJ 1601:名字缩写
1601: 名字缩写 时间限制: 1 Sec 内存限制: 128 MB 提交: 288 解决: 80 [提交][状态][讨论版] 题目描述 Noname老师有一个班的学生名字要写,但是他太懒了,想 ...
- 深度学习之group convolution,计算量及参数量
目录: 1.什么是group convolution? 和普通的卷积有什么区别? 2.分析计算量.flops 3.分析参数量 4.相比于传统普通卷积有什么优势以及缺点,有什么改进方法? 5.refer ...
- JSP中九大内置对象及其作用
jsp中有九大内置对象分别为:request,response,session,application,out,pageContext,page,config,exception. request:请 ...
- linux(centeros)svn的安装
SVN linux搭建svn服务器参考:http://www.cnblogs.com/chaichuan/p/3758173.htmlSubversion(SVN) 是一个开源的版本控制系統, 也就是 ...
- element ui 选择期 传对象
<template> <el-select value-key="label" v-model="value" placeholder=&qu ...
- Python RSA操作
公钥加密.私钥解密 # -*- coding: utf-8 -*- import rsa # rsa加密 def rsaEncrypt(str): # 生成公钥.私钥 (pubkey, privkey ...
- delete释放空间时出错的原因
int *a=new int[10]; ...... delete []a; 后面“delete []a;”出现错误的情况大致有: 1 数组的首地址a被你有意无意更改了,如:a++之类的: 2 变量的 ...
- 202-基于TI DSP TMS320C6678、Xilinx K7 FPGA XC7K325T的高速数据处理核心板
该DSP+FPGA高速信号采集处理板由我公司自主研发,包含一片TI DSP TMS320C6678和一片Xilinx FPGA K7 XC72K325T-1ffg900.包含1个千兆网口,1个FMC ...
- Ubuntu18 给terminal改个漂亮的命令行提示符
重新安装了VMware和Ubuntu,但是命令行提示符太单调,不美观,如何更改呢.于是在网上巴拉巴拉搜寻一番. 1.更改PS1环境变量,这俩都可以,我选择第一个: export PS1="\ ...