java爬取读者文摘杂志
java爬虫入门实战练习
此代码仅用于学习研究
此次练习选择了读者文摘杂志网站进行文章爬取
练习中用到的都只是一些简单的方法,不过过程中复习了输入流输出流的使用以及文件的创建写入等知识,对自己还是有所帮助的
经小伙伴提醒,部分文章存在乱码,我们将这两个地方修改一下就可以了
代码可以直接运行(需要Jsoup包),唯一需要在E盘下创建一个名为FileTest的文件夹存储下载的文件或者修改一下代码中的存储路径
第一处(第52行)修改为:
OutputStreamWriter fileOutputStream = new OutputStreamWriter(new FileOutputStream(file,true),"UTF-8");
第二处(第55行)修改为:
fileOutputStream.write(Content.toString());
原代码:
import java.io.File;
import java.io.FileOutputStream; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements; public class testDUZHE { public static void main(String[] args) throws Exception {
// 第一步:访问读者首页
String url = "https://www.dzwzzz.com/";
Document document = Jsoup.connect(url).get(); // 第二步:解析页面
Elements datatime = document.select("a");
//获取a标签
for(int num=0;num<datatime.size();num++) {
//判断文章链接
if(datatime.get(num).attr("href").charAt(4)=='_') {
//获取a标签中href属性的值
String deHref = datatime.get(num).attr("href");
System.out.println("==================\n\n\n");
System.out.println("开始获取"+deHref.substring(0, 4)+"年第"+deHref.substring(5,7)+"期");
System.out.println("\n\n\n==================");
//根据a标签的值创建不同年份期刊的文件夹
File fileTest = new File("E:/FileTest/"+datatime.get(num).text());
fileTest.mkdirs();//创建文件夹
//访问不同期刊页面
String DuZhe = "https://www.dzwzzz.com/"+deHref;
Document newdocu = Jsoup.connect(DuZhe).get();
//获取a标签
Elements a_Elements = newdocu.select("a");
for(int i=0;i<a_Elements.size();i++) {
//判断是否是文章链接
if (a_Elements.get(i).attr("href").charAt(0)=='d'
&&a_Elements.get(i).attr("href").charAt(1)=='u')
{
//访问文章所在页
String purpose = "https://www.dzwzzz.com/"+deHref.substring(0, 8)+a_Elements.get(i).attr("href");
Document finaldocu = Jsoup.connect(purpose).get();
//获取文章标题
Elements h1_elements = finaldocu.select("h1");
String title = h1_elements.text();
//获取文章内容
Elements p_Elements = finaldocu.select("p");
String Content = p_Elements.text();
//创建txt文件
File file = new File("E:/FileTest/"+datatime.get(num).text()+"/"+title+".txt");
//创建文件输出流
FileOutputStream fileOutputStream = new FileOutputStream(file,true);
//这里的true功能是不覆盖原有内容,所以多次运行程序会造成重复
//将文章内容写入文件
fileOutputStream.write(Content.getBytes());
fileOutputStream.close();
System.out.println("文章地址"+purpose);
System.out.println(title+" 下载成功!");
}
}
}
} } }
运行截图:
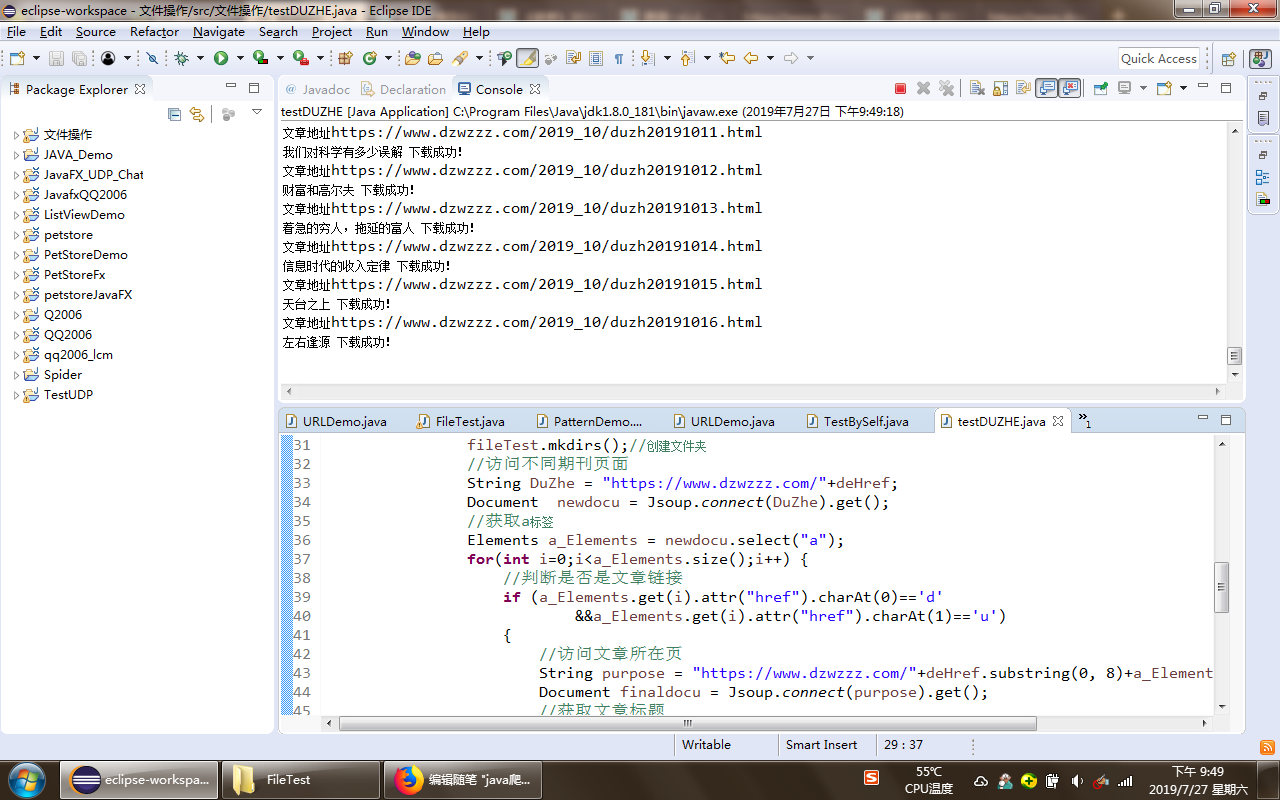
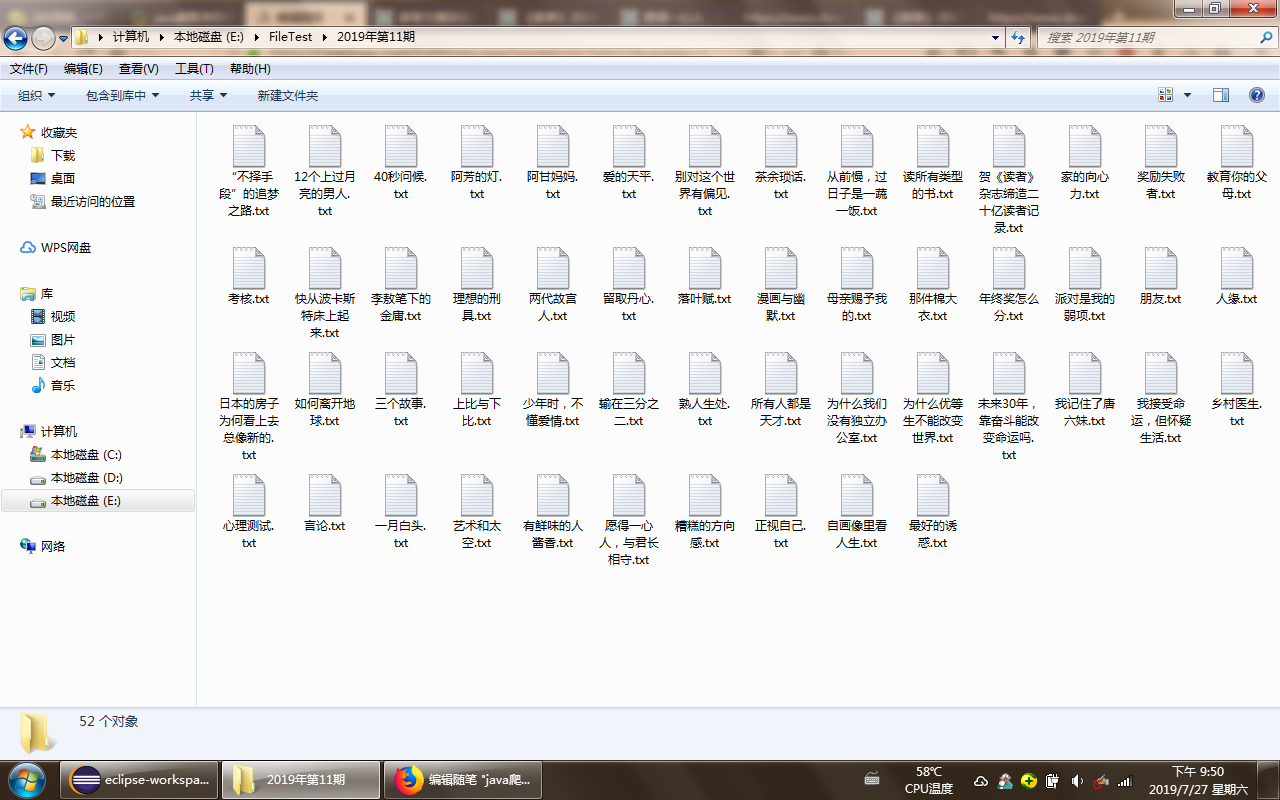
下载成功文件示例:
java爬取读者文摘杂志的更多相关文章
- MinerHtmlThread.java 爬取页面线程
MinerHtmlThread.java 爬取页面线程 package com.iteye.injavawetrust.miner; import org.apache.commons.logging ...
- MinerConfig.java 爬取配置类
MinerConfig.java 爬取配置类 package com.iteye.injavawetrust.miner; import java.util.List; /** * 爬取配置类 * @ ...
- Java爬取网络博客文章
前言 近期本人在某云上购买了个人域名,本想着以后购买与服务器搭建自己的个人网站,由于需要筹备的太多,暂时先搁置了,想着先借用GitHub Pages搭建一个静态的站,搭建的过程其实也曲折,主要是域名地 ...
- Java爬取校内论坛新帖
Java爬取校内论坛新帖 为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法. 嗯,这次就选Java. 第三方库准备 Jsoup Jsoup是一款比较好 ...
- Java爬取B站弹幕 —— Python云图Wordcloud生成弹幕词云
一 . Java爬取B站弹幕 弹幕的存储位置 如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号, ...
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
[背景] 在上一篇博文java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表 ...
- java爬取并下载酷狗TOP500歌曲
是这样的,之前买车送的垃圾记录仪不能用了,这两天狠心买了好点的记录仪,带导航.音乐.蓝牙.4G等功能,寻思,既然有这些功能就利用起来,用4G听歌有点奢侈,就准备去酷狗下点歌听,居然都是需要办会员才能下 ...
- Java爬取并下载酷狗音乐
本文方法及代码仅供学习,仅供学习. 案例: 下载酷狗TOP500歌曲,代码用到的代码库包含:Jsoup.HttpClient.fastJson等. 正文: 1.分析是否可以获取到TOP500歌单 打开 ...
- Java爬取先知论坛文章
Java爬取先知论坛文章 0x00 前言 上篇文章写了部分爬虫代码,这里给出一个完整的爬取先知论坛文章代码. 0x01 代码实现 pom.xml加入依赖: <dependencies> & ...
随机推荐
- Elasticsearch学习,请先看这一篇
题记: Elasticsearch研究有一段时间了,现特将Elasticsearch相关核心知识.原理从初学者认知.学习的角度,从以下9个方面进行详细梳理.欢迎讨论-- 0. 带着问题上路--ES是如 ...
- 【学习总结】Python-3-身份运算符 is 与 == 区别
参考:菜鸟教程-Python3运算符 身份运算符 is 和 is not:用于比较两个对象的存储单元 判断两个标识符是不是引用自相同或不同对象,返回一个布尔值 对于"同一个对象"中 ...
- spring 事物(三)—— 声明式事务管理详解
spring的事务处理分为两种: 1.编程式事务:在程序中控制事务开始,执行和提交:详情请点此跳转: 2.声明式事务:在Spring配置文件中对事务进行配置,无须在程序中写代码:(建议使用) 我对&q ...
- java 关键字汇总
关键字 描述 abstract 抽象方法,抽象类的修饰符 assert 断言条件是否满足 continue 不执行循环体剩余部分 default switch语句中的默认分支 do-while 循环语 ...
- common-dbcp2数据库连接池参数说明(转)
转自:http://bsr1983.iteye.com/blog/2092467 由于commons-dbcp所用的连接池出现版本升级,因此commons-dbcp2中的数据库池连接配置也发生了变化, ...
- input file 上传文件类型控制
文件类型 accept *.3gpp audio/3gpp, video/3gpp.ac3 audio/ac3.asf allpication/vnd.ms-asf.au audio/basic.cs ...
- C++ 浅析调试,内存重叠查看
这里举个例子查看内存, 环境为:vs 2017 测试为strcpy[因为测试老api,需要在 预处理中 添加 _CRT_SECURE_NO_WARNINGS ] 测试问题:内存溢出 源码: #incl ...
- BeanUtils.copyProperties()拷贝属性时,忽略空值
把source的属性值复制给target的相同属性上,注意:双方需要复制的属性要有get.set方法 BeanUtils.copyProperties(source, target, PublicUt ...
- iterators和generators
iterators >>> mylist=[x*x for x in range(3)] >>> mylist [0, 1, 4] generators >& ...
- iview select下拉框的蜜汁小坑
前言 最近使用iview的select下拉选择器,遇到一个很神奇的问题:选中下拉框里面的一个值,但是再去点下拉框的时候就只剩刚才选中的数据了.感觉应该是插件把刚才选中的数据当做的搜索条件,所以需要做的 ...