Slim模型部署多GPU
1 多GPU原理
单GPU时,思路很简单,前向、后向都在一个GPU上进行,模型参数更新时只涉及一个GPU。
多GPU时,有模型并行和数据并行两种情况。
模型并行指模型的不同部分在不同GPU上运行。
数据并行指不同GPU上训练数据不同,但模型是同一个(相当于是同一个模型的副本)。
TensorFlow支持的是数据并行。
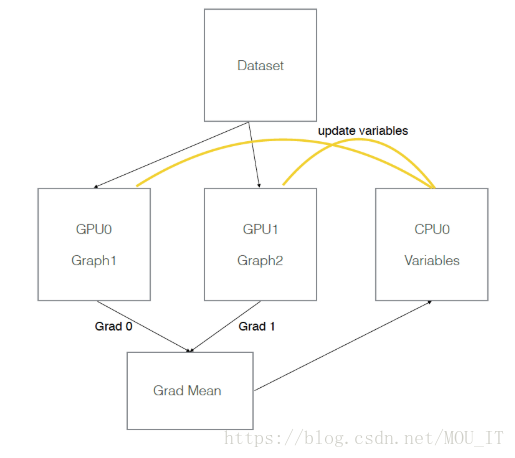
数据并行的原理:CPU负责梯度平均和参数更新,在GPU上训练模型的副本。
多GPU并行计算的过程如下:
1)模型副本定义在GPU上;
2)对于每一个GPU, 都是从CPU获得数据,前向传播进行计算,得到loss,并计算出梯度;
3)CPU接到GPU的梯度,取平均值,然后进行梯度更新。
这个在tf的实现思路如下:
模型参数保存在一个指定gpu/cpu上,模型参数的副本在不同gpu上,每次训练,提供batch_size*gpu_num数据,并等量拆分成多个batch,分别送入不同GPU。前向在不同gpu上进行,模型参数更新时,将多个GPU后向计算得到的梯度数据进行平均,并在指定GPU/CPU上利用梯度数据更新模型参数。
假设有两个GPU(gpu0,gpu1),模型参数实际存放在cpu0上,实际一次训练过程如下图所示:
2 model_deploy.py文件及其用法
为了能让一个Slim模型在多个GPU上训练更加容易,这个模块提供了一系列帮助函数,比如create_clones()、optimize_clones()、deploy()、gather_clone_loss()、_add_gradients_summaries()、_sum_clones_gradients()等,该模块位于:https://github.com/tensorflow/models/blob/master/research/slim/deployment/model_deploy.py
用法如下:
g = tf.Graph()
# 定义部署配置信息,你可以将此类的实例传递给deploy()以指定如何部署要构建的模型。 如果未传递,则将使用从默认deployment_hparams构建的实例。
config = model_deploy.DeploymentConfig(num_clones=2, clone_on_cpu=True)
# 在保存变量的设备上创建global step
with tf.device(config.variables_device()):
global_step = slim.create_global_step()
# 定义输入
with tf.device(config.inputs_device()):
images, labels = LoadData(...)
inputs_queue = slim.data.prefetch_queue((images, labels))
# 定义优化器
with tf.device(config.optimizer_device()):
optimizer = tf.train.MomentumOptimizer(FLAGS.learning_rate, FLAGS.momentum)
# 定义模型和损失函数
def model_fn(inputs_queue):
images, labels = inputs_queue.dequeue()
predictions = CreateNetwork(images)
slim.losses.log_loss(predictions, labels)
# 模型部署
model_dp = model_deploy.deploy(config, model_fn, [inputs_queue],optimizer=optimizer)
# 开始训练
slim.learning.train(model_dp.train_op, my_log_dir,summary_op=model_dp.summary_op)
Clone namedtuple:把那些每次调用model_fn的关联值保存在一起
- outputs: 调用model_fn()后的返回值
- scope: 用来创建clone的scope
- device: 用来创建clone的设备
DeployedModel namedtuple: 把那些需要被多个副本训练的值保存在一起
- train_op: 一个运行优化器训练的操作,包含由model_fn创建的更新操作。仅仅在指定优化器时显示。
- summary_op : 一个由model_fn()创建的操作,用来summeries和处理梯度。
- total_loss: 总的损失,包含由model_fn()返回的损失和正则化损失的总和
- clones: 通过create_clones()返回的克隆元组列表
DeploymentConfig的参数:
- num_clones: 部署在每个副本上的模型克隆数量,该模型将在每个副本中复制num_clones次。
- clone_on_cpu: 如果为true,则克隆被放在CPU上
- replica_id: 模型部署所在副本的索引,对于主副本而言通常是0
- num_replicas: 如果num_replicas为1,则通过单个进程部署模型。 在这种情况下,worker_device,num_ps_tasks和ps_device将被忽略。如果num_replicas大于1,则worker_device和ps_device必须为worker和ps作业指定TensorFlow设备,而num_ps_tasks必须为正。
- num_ps_tasks : ps作业的任务数。 0不使用副本。
- worker_job_name : 作业名
- ps_job_name : 参数服务器作业名
Slim模型部署多GPU的更多相关文章
- TensorFlow Serving实现多模型部署以及不同版本模型的调用
前提:要实现多模型部署,首先要了解并且熟练实现单模型部署,可以借助官网文档,使用Docker实现部署. 1. 首先准备两个你需要部署的模型,统一的放在multiModel/文件夹下(文件夹名字可以任意 ...
- PyTorch专栏(六): 混合前端的seq2seq模型部署
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/ 欢迎关注PyTorch官方中文教程站: http://pytorch.panchuang.net/ 专栏目录: 第一 ...
- 混合前端seq2seq模型部署
混合前端seq2seq模型部署 本文介绍,如何将seq2seq模型转换为PyTorch可用的前端混合Torch脚本.要转换的模型来自于聊天机器人教程Chatbot tutorial. 1.混合前端 在 ...
- 学习笔记TF022:产品环境模型部署、Docker镜像、Bazel工作区、导出模型、服务器、客户端
产品环境模型部署,创建简单Web APP,用户上传图像,运行Inception模型,实现图像自动分类. 搭建TensorFlow服务开发环境.安装Docker,https://docs.docker. ...
- 用tensorlayer导入Slim模型迁移学习
上一篇博客[用tensorflow迁移学习猫狗分类]笔者讲到用tensorlayer的[VGG16模型]迁移学习图像分类,那麽问题来了,tensorlayer没提供的模型怎么办呢?别担心,tensor ...
- Tensorflow Serving 模型部署和服务
http://blog.csdn.net/wangjian1204/article/details/68928656 本文转载自:https://zhuanlan.zhihu.com/p/233614 ...
- 【tensorflow-转载】tensorflow模型部署系列
参考 1. tensorflow模型部署系列: 完
- 自动化kolla-ansible部署openstack+GPU透传方法
自动化kolla-ansible部署openstack+GPU透传方法 欢迎加QQ群:1026880196 进行交流学习 1. CentOS7.x-8.x系列为虚拟机配置GPU直通 1. 编辑文件vi ...
- 如何使用flask将模型部署为服务
在某些场景下,我们需要将机器学习或者深度学习模型部署为服务给其它地方调用,本文接下来就讲解使用python的flask部署服务的基本过程. 1. 加载保存好的模型 为了方便起见,这里我们就使用简单的分 ...
随机推荐
- 前端 -- javas-基本语法/引用等
javas-基本语法/引用等 JavaScript介绍 JavaScript是运行在浏览器端的脚步语言,JavaScript主要解决的是前端与用户交互的问题,包括使用交互与数据交互. JavaScri ...
- CSS 圣杯布局
前端的两个经典布局想必大家都有多了解--圣杯布局和双飞翼布局,因为它既能体现你懂HTML结构又能体现出你对DIV+CSS布局的掌握. 事实上,圣杯布局其实和双飞翼布局是一回事.它们实现的都是三栏布局, ...
- 牛客多校第十场 D Han Xin and His Troops 中国剩余定理
题意: 韩信有若干个兵,给定你若干个模数和余数,再给你一个1e18以内的范围限制,求解同余方程组,如果无解,输出“他一定在撒谎”,如果最小解超出范围限制,输出“他可能在撒谎”,否则输出最小解 注意:不 ...
- 【Android】Retrofit网络请求参数注解,@Path、@Query、@QueryMap.
对Retrofit已经使用了一点时间了,是时候归纳一下各种网络请求的service了. 下面分为GET.POST.DELETE还有PUT的请求,说明@Path.@Query.@QueryMap.@Bo ...
- Flex birdeye笔记
1.将官网示例demo运行起来 新建Flex项目,直接将官网src下的demo拷贝到新建的项目的src下 .将官网example-binaries目录下的文件拷贝到新建项目的bin-debug下即可 ...
- topjui.common.js
function getTabWindow() { var curTabWin = null; if (topJUI.config.aloneUse) { curTabWin = window; } ...
- HDU-6441-Find Integer-费马大定理+奇偶数列法则
感觉这样看的比较清楚. 题意: 给出n和a,判断能否求出a^n+b^n=c^n中b和c的值,若可以输出b和c,否则则输出-1 -1. 思路: 数据给的比较大,但是题目很简单,套两个公式:费马打定理和奇 ...
- (c# )操作Excel的时候出现:不能使用对象或链接
可能就是你打开了多个Excel进程没有关掉出现的问题. 编程:对文件操作的时候要养成关掉进程的习惯 在c#中操作完后关闭资源的代入如下: System.Runtime.InteropServices. ...
- codeforces round#524 C. Masha and two friends /// 矩形切割
题目大意: 给定n行m列的黑白棋盘如下 给定矩形的左下点x1 y1和右上点x2 y2将这个区域都涂成白色 再给定矩形的左下点x3 y3和右上点x4 y4将这个区域都涂成黑色 求最后棋盘内有分别多少个白 ...
- vc面试题目
class B { public: B() { cout << "default constructor" << endl; } ~B() { cout & ...