Hadoop学习之路(7)MapReduce自定义排序
本文测试文本:
tom 20 8000
nancy 22 8000
ketty 22 9000
stone 19 10000
green 19 11000
white 39 29000
socrates 30 40000
MapReduce中,根据key进行分区、排序、分组
MapReduce会按照基本类型对应的key进行排序,如int类型的IntWritable,long类型的LongWritable,Text类型,默认升序排序
为什么要自定义排序规则?现有需求,需要自定义key类型,并自定义key的排序规则,如按照人的salary降序排序,若相同,则再按age升序排序
以Text类型为例:
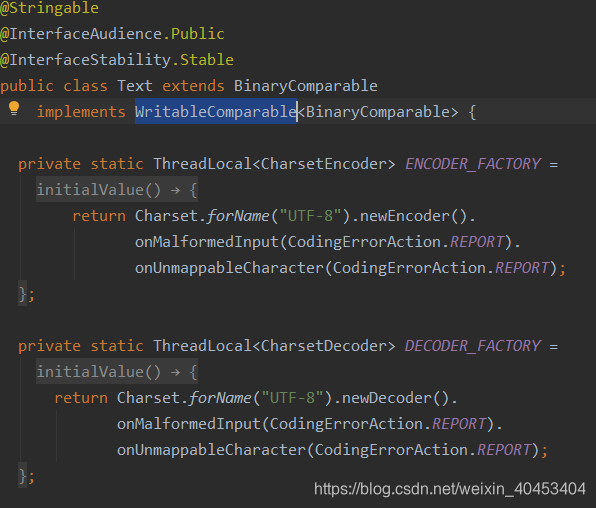
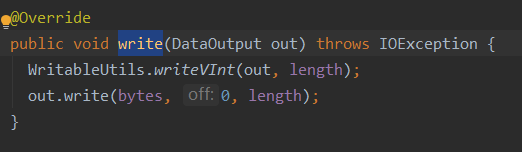
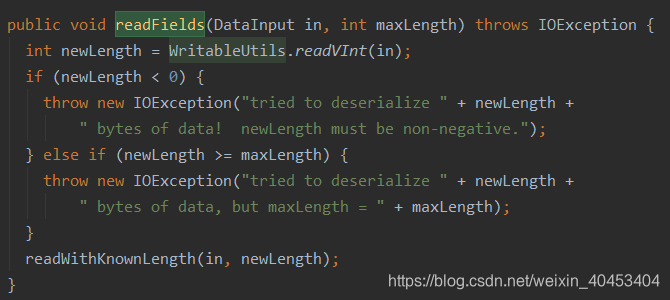
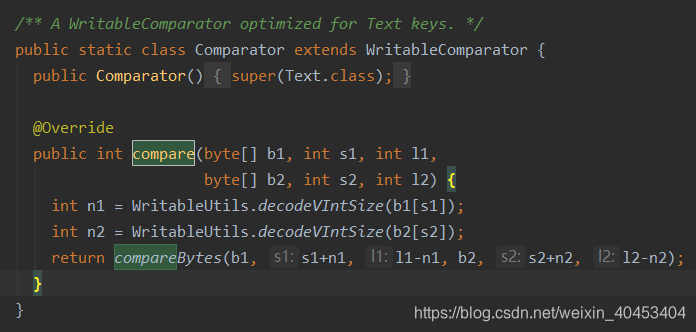
Text类实现了WritableComparable接口,并且有write()、readFields()和compare()方法
readFields()方法:用来反序列化操作
write()方法:用来序列化操作
所以要想自定义类型用来排序需要有以上的方法
自定义类代码:
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Person implements WritableComparable<Person> {
private String name;
private int age;
private int salary;
public Person() {
}
public Person(String name, int age, int salary) {
//super();
this.name = name;
this.age = age;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
@Override
public String toString() {
return this.salary + " " + this.age + " " + this.name;
}
//先比较salary,高的排序在前;若相同,age小的在前
public int compareTo(Person o) {
int compareResult1= this.salary - o.salary;
if(compareResult1 != 0) {
return -compareResult1;
} else {
return this.age - o.age;
}
}
//序列化,将NewKey转化成使用流传送的二进制
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(name);
dataOutput.writeInt(age);
dataOutput.writeInt(salary);
}
//使用in读字段的顺序,要与write方法中写的顺序保持一致
public void readFields(DataInput dataInput) throws IOException {
//read string
this.name = dataInput.readUTF();
this.age = dataInput.readInt();
this.salary = dataInput.readInt();
}
}
MapReuduce程序:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
public class SecondarySort {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","hadoop2.7");
Configuration configuration = new Configuration();
//设置本地运行的mapreduce程序 jar包
configuration.set("mapreduce.job.jar","C:\\Users\\tanglei1\\IdeaProjects\\Hadooptang\\target\\com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
Job job = Job.getInstance(configuration, SecondarySort.class.getSimpleName());
FileSystem fileSystem = FileSystem.get(URI.create(args[1]), configuration);
if (fileSystem.exists(new Path(args[1]))) {
fileSystem.delete(new Path(args[1]), true);
}
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(Person.class);
job.setMapOutputValueClass(NullWritable.class);
//设置reduce的个数
job.setNumReduceTasks(1);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Person.class);
job.setOutputValueClass(NullWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class MyMap extends
Mapper<LongWritable, Text, Person, NullWritable> {
//LongWritable:输入参数键类型,Text:输入参数值类型
//Persion:输出参数键类型,NullWritable:输出参数值类型
@Override
//map的输出值是键值对<K,V>,NullWritable说关心V的值
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
//LongWritable key:输入参数键值对的键,Text value:输入参数键值对的值
//获得一行数据,输入参数的键(距首行的位置),Hadoop读取数据的时候逐行读取文本
//fields:代表着文本一行的的数据
String[] fields = value.toString().split(" ");
// 本列中文本一行数据:nancy 22 8000
String name = fields[0];
//字符串转换成int
int age = Integer.parseInt(fields[1]);
int salary = Integer.parseInt(fields[2]);
//在自定义类中进行比较
Person person = new Person(name, age, salary);
context.write(person, NullWritable.get());
}
}
public static class MyReduce extends
Reducer<Person, NullWritable, Person, NullWritable> {
@Override
protected void reduce(Person key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
}
运行结果:
40000 30 socrates
29000 39 white
11000 19 green
10000 19 stone
9000 22 ketty
8000 20 tom
8000 22 nancy
Hadoop学习之路(7)MapReduce自定义排序的更多相关文章
- Hadoop学习之路(6)MapReduce自定义分区实现
MapReduce自带的分区器是HashPartitioner 原理:先对map输出的key求hash值,再模上reduce task个数,根据结果,决定此输出kv对,被匹配的reduce任务取走. ...
- Hadoop学习之路(5)Mapreduce程序完成wordcount
程序使用的测试文本数据: Dear River Dear River Bear Spark Car Dear Car Bear Car Dear Car River Car Spark Spark D ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Hadoop学习之路(十三)MapReduce的初识
MapReduce是什么 首先让我们来重温一下 hadoop 的四大组件: HDFS:分布式存储系统 MapReduce:分布式计算系统 YARN:hadoop 的资源调度系统 Common:以上三大 ...
- Hadoop学习(4)-- MapReduce
MapReduce是一种用于大规模数据集的并行计算编程模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.其主要思想Map(映射)和Reduce(规约)都是从函数是编程语言中借鉴而来的 ...
- 小强的Hadoop学习之路
本人一直在做NET开发,接触这行有6年了吧.毕业也快四年了(6年是因为大学就开始在一家小公司做门户网站,哈哈哈),之前一直秉承着学要精,就一直一门心思的在做NET(也是懒吧).最近的工作一直都和大数据 ...
- 我的hadoop学习之路
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上. Ha ...
- Hadoop学习基础之三:MapReduce
现在是讨论这个问题的不错的时机,因为最近媒体上到处充斥着新的革命所谓“云计算”的信息.这种模式需要利用大量的(低端)处理器并行工作来解决计算问题.实际上,这建议利用大量的低端处理器来构建数据中心,而不 ...
随机推荐
- 剑指offer刷题笔记
删除链表中重复的结点:较难 在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针. 例如,链表1->2->3->3->4->4- ...
- NR / 5G - Downlink Carrier Waveform
- linux 学习操作小计
屌丝最近在接触lamp开发 把工作中遇到的 问题和 一些常用的操作记下来.以便以后去翻阅 (1)linux下备份mysql数据库方法 #mysqldump -u root -p dbname > ...
- 学习CSS之用CSS实现时钟效果
一.机械时钟 1.最终效果 用 CSS 绘制的机械时钟效果如下: HTML 中代码结构为: <body> <div class="clock"> ...
- 开发时从宿主机连接容器中的MySQL
从宿主机连接Docker容器中的MySQL 刚接触Docker,电脑安装Docker后,使用docker命令pull了一个MySQL5.6的Docker镜像,之后docker run启动创建容器. 可 ...
- [Python]List 过滤
获取数据库列表屏蔽系统自带数据库 # 原代码 db_list_result = [('master', ), ('tempdb', ), ('model', ), ('msdb', ), ('stud ...
- redis系列-14点的灵异事件
概述 项目组每天14点都会遭遇惊魂时刻.一条条告警短信把工程师从午后小憩中拉回现实.之后问题又神秘消失.是PM喊你上工了?还是服务器给你开玩笑?下面请看工程师如何一步一步揪出真凶,解决问题. 如果不想 ...
- Python2-Django配置阿里大于的短信验证码接口
1.短信发送开发指南地址:https://help.aliyun.com/document_detail/55491.html?spm=a2c4g.11186623.6.568.l5zTwH 2.SD ...
- Red Team 指南-第1章 红队和红队概述
第1章 红队和红队概述 贡献者:Tony Kelly @infosectdk # 翻译者 BugMan 什么是红队?它来自哪里? 红队的起源是军事起源.人们意识到,为了更好地防御, 需要攻击自己的防御 ...
- go实现java虚拟机01
前段时间看了一本书,说的是用go语言实现java虚拟机,很有意思,于是就花了一段时间学习了一下go语言,虽然对go的底层理解不是很深,但是写代码还是可以的,就当做个读书笔记吧! 链接在这里,另外还有一 ...