Hadoop学习之路(7)MapReduce自定义排序
本文测试文本:
tom 20 8000
nancy 22 8000
ketty 22 9000
stone 19 10000
green 19 11000
white 39 29000
socrates 30 40000
MapReduce中,根据key进行分区、排序、分组
MapReduce会按照基本类型对应的key进行排序,如int类型的IntWritable,long类型的LongWritable,Text类型,默认升序排序
为什么要自定义排序规则?现有需求,需要自定义key类型,并自定义key的排序规则,如按照人的salary降序排序,若相同,则再按age升序排序
以Text类型为例:
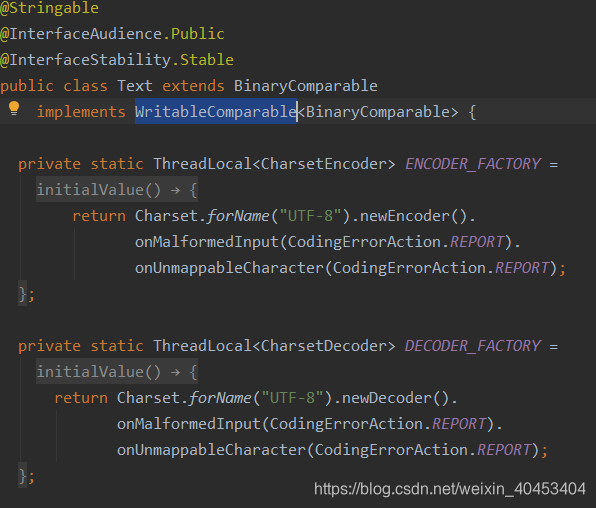
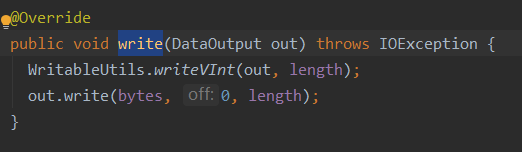
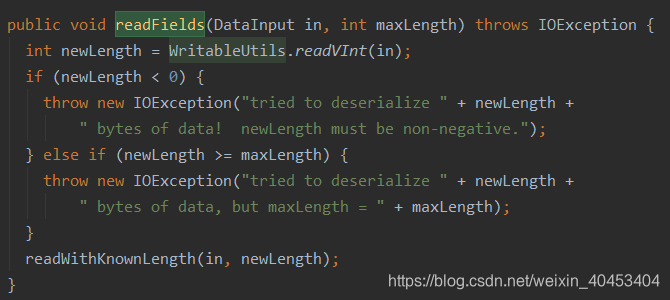
Text类实现了WritableComparable接口,并且有write()、readFields()和compare()方法
readFields()方法:用来反序列化操作
write()方法:用来序列化操作
所以要想自定义类型用来排序需要有以上的方法
自定义类代码:
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Person implements WritableComparable<Person> {
private String name;
private int age;
private int salary;
public Person() {
}
public Person(String name, int age, int salary) {
//super();
this.name = name;
this.age = age;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
@Override
public String toString() {
return this.salary + " " + this.age + " " + this.name;
}
//先比较salary,高的排序在前;若相同,age小的在前
public int compareTo(Person o) {
int compareResult1= this.salary - o.salary;
if(compareResult1 != 0) {
return -compareResult1;
} else {
return this.age - o.age;
}
}
//序列化,将NewKey转化成使用流传送的二进制
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(name);
dataOutput.writeInt(age);
dataOutput.writeInt(salary);
}
//使用in读字段的顺序,要与write方法中写的顺序保持一致
public void readFields(DataInput dataInput) throws IOException {
//read string
this.name = dataInput.readUTF();
this.age = dataInput.readInt();
this.salary = dataInput.readInt();
}
}
MapReuduce程序:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
public class SecondarySort {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","hadoop2.7");
Configuration configuration = new Configuration();
//设置本地运行的mapreduce程序 jar包
configuration.set("mapreduce.job.jar","C:\\Users\\tanglei1\\IdeaProjects\\Hadooptang\\target\\com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
Job job = Job.getInstance(configuration, SecondarySort.class.getSimpleName());
FileSystem fileSystem = FileSystem.get(URI.create(args[1]), configuration);
if (fileSystem.exists(new Path(args[1]))) {
fileSystem.delete(new Path(args[1]), true);
}
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(Person.class);
job.setMapOutputValueClass(NullWritable.class);
//设置reduce的个数
job.setNumReduceTasks(1);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Person.class);
job.setOutputValueClass(NullWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class MyMap extends
Mapper<LongWritable, Text, Person, NullWritable> {
//LongWritable:输入参数键类型,Text:输入参数值类型
//Persion:输出参数键类型,NullWritable:输出参数值类型
@Override
//map的输出值是键值对<K,V>,NullWritable说关心V的值
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
//LongWritable key:输入参数键值对的键,Text value:输入参数键值对的值
//获得一行数据,输入参数的键(距首行的位置),Hadoop读取数据的时候逐行读取文本
//fields:代表着文本一行的的数据
String[] fields = value.toString().split(" ");
// 本列中文本一行数据:nancy 22 8000
String name = fields[0];
//字符串转换成int
int age = Integer.parseInt(fields[1]);
int salary = Integer.parseInt(fields[2]);
//在自定义类中进行比较
Person person = new Person(name, age, salary);
context.write(person, NullWritable.get());
}
}
public static class MyReduce extends
Reducer<Person, NullWritable, Person, NullWritable> {
@Override
protected void reduce(Person key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
}
运行结果:
40000 30 socrates
29000 39 white
11000 19 green
10000 19 stone
9000 22 ketty
8000 20 tom
8000 22 nancy
Hadoop学习之路(7)MapReduce自定义排序的更多相关文章
- Hadoop学习之路(6)MapReduce自定义分区实现
MapReduce自带的分区器是HashPartitioner 原理:先对map输出的key求hash值,再模上reduce task个数,根据结果,决定此输出kv对,被匹配的reduce任务取走. ...
- Hadoop学习之路(5)Mapreduce程序完成wordcount
程序使用的测试文本数据: Dear River Dear River Bear Spark Car Dear Car Bear Car Dear Car River Car Spark Spark D ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Hadoop学习之路(十三)MapReduce的初识
MapReduce是什么 首先让我们来重温一下 hadoop 的四大组件: HDFS:分布式存储系统 MapReduce:分布式计算系统 YARN:hadoop 的资源调度系统 Common:以上三大 ...
- Hadoop学习(4)-- MapReduce
MapReduce是一种用于大规模数据集的并行计算编程模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.其主要思想Map(映射)和Reduce(规约)都是从函数是编程语言中借鉴而来的 ...
- 小强的Hadoop学习之路
本人一直在做NET开发,接触这行有6年了吧.毕业也快四年了(6年是因为大学就开始在一家小公司做门户网站,哈哈哈),之前一直秉承着学要精,就一直一门心思的在做NET(也是懒吧).最近的工作一直都和大数据 ...
- 我的hadoop学习之路
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上. Ha ...
- Hadoop学习基础之三:MapReduce
现在是讨论这个问题的不错的时机,因为最近媒体上到处充斥着新的革命所谓“云计算”的信息.这种模式需要利用大量的(低端)处理器并行工作来解决计算问题.实际上,这建议利用大量的低端处理器来构建数据中心,而不 ...
随机推荐
- The related functions and attributes for managing attributes - 操作属性的重要属性和函数
特性 property 都是类属性(静态变量),但是特性管理的其实是实例属性的存取, ****** 回顾 -'类方法' classmethod 和 '静态方法' staticmethod 皆可以访问类 ...
- 20200220--python学习第13天
今日内容 作业题(21题) 推导式 装饰器 模块[可选] 内容回顾 1.函数 a.参数 def func(a1,a2):pass def func(a1,a2=None):pass 默认参数推荐使用不 ...
- php 安装 event 和 libevent 扩展
这里使用的是php7.0.24 ,php是yum安装的 一.安装event扩展 用yum无法安装event扩展 手动安装 php 必须要开启 sockets 功能,需要安装php的socket扩展,才 ...
- 杭电-------2048不容易系列之(4)考新郎(C语言)
/* 思路:有n位新郎,但是又m位新郎会找错,那么有n-m位新郎会找对,而找对的n-m位新郎的找发就是在 n位新郎中随机找n-m位有多少种排列组合公式有n!/(m!*(n-m!)),而另外找错的新郎则 ...
- Java基础环境配置及HelloWorld
一.什么是JDK,JRE JDK(Java Development Kit Java开发工具包) JDK是提供给Java开发人员使用的,其中包含了java的开发工具,也包括了JRE.所以安装了JDK, ...
- docker启动nginx的ssl配置
前提条件 一台云服务器(阿里云.腾讯云等的centOS) 服务器上面要有docker(安装方法这里不做介绍) 一个域名 ssl证书(两个文件:一个key后缀,一个pem后缀:生成方法很多这里不再介绍) ...
- css中伪类和伪元素
伪类和伪元素时对那些我们不能通过class.id等选择元素的补充 伪类的操作对象是文档树中已有的元素(可以给已有元素加了一个类替代),而伪元素则创建了一个文档数外的元素(可以添加一个新元素替代) CS ...
- JS高阶编程技巧--compose函数
先看代码: let fn1 = function (x) { return x + 10; }; let fn2 = function (x) { return x * 10; }; let fn3 ...
- 复制表结构创建分表 再设置自增ID
CREATE TABLE table_name1 LIKE table_name ALTER TABLE test AUTO_INCREMENT=x
- Cesium案例解析(五)——3DTilesPhotogrammetry摄影测量3DTiles数据
目录 1. 概述 2. 案例 3. 结果 1. 概述 3D Tiles是用于传输和渲染大规模3D地理空间数据的格式,例如摄影测量,3D建筑,BIM / CAD,实例化特征和点云等.与常规的模型文件格式 ...