PageRank学习
喜欢手写学习,记忆深刻(字丑勿喷!)。

计算过程的代码如下:
public class PageRank
{
private static double m[][]={
{ 0 , 0.5 , 1 , 0 },
{0.333333333 , 0 , 0 , 0.5},
{0.333333333 , 0 , 0 , 0.5},
{0.333333333 , 0.5 , 0 , 0 }
};
private static double v[]={0.25,0.25,0.25,0.25};
private static double v1[]={0,0,0,0};
public static void main(String[] argv)
{
for(int iterater=0;iterater<1000;iterater++)
{
for(int i=0;i<4;i++)
{
for(int j=0;j<4;j++)
{
v1[i]+=m[i][j]*v[j];
}
}
for(int k=0;k<4;k++)
{
v[k]=v1[k];
v1[k]=0;
}
}
for(int k=0;k<4;k++)
{
System.out.println(v[k]);
}
}
}
上面使用的图是一个没有太大缺陷的图,其实PageRank中海油很多问题需要处理,主要问题有:
1.终止点问题
上述上网者的行为是一个马尔科夫过程的实例,要满足收敛性,需要具备一个条件:
- 图是强连通的,即从任意网页可以到达其他任意网页:
互联网上的网页不满足强连通的特性,因为有一些网页不指向任何网页,如果按照上面的计算,上网者到达这样的网页后便走投无路、四顾茫然,导致前面累计得到的转移概率被清零,这样下去,最终的得到的概率分布向量所有元素几乎都为0。假设我们把上面图中C到A的链接丢掉,C变成了一个终止点,得到下面这个图:

对应的转移矩阵为:

连续迭代下去,最终所有元素都为0:
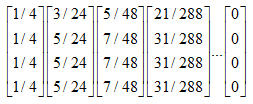
代码如下:
public class PageRank
{
private static double m[][]={
{ 0 , 0.5 , 0 , 0 },
{0.333333333 , 0 , 0 , 0.5},
{0.333333333 , 0 , 0 , 0.5},
{0.333333333 , 0.5 , 0 , 0 }//第三列全为0
};
private static double v[]={0.25,0.25,0.25,0.25};
private static double v1[]={0,0,0,0};
public static void main(String[] argv)
{
for(int iterater=0;iterater<1000;iterater++)
{
for(int i=0;i<4;i++)
{
for(int j=0;j<4;j++)
{
v1[i]+=m[i][j]*v[j];
}
}
for(int k=0;k<4;k++)
{
v[k]=v1[k];
v1[k]=0;
}
}
for(int k=0;k<4;k++)
{
System.out.println(v[k]);
}
}
}
2.陷阱问题
另外一个问题就是陷阱问题,即有些网页不存在指向其他网页的链接,但存在指向自己的链接。比如下面这个图:
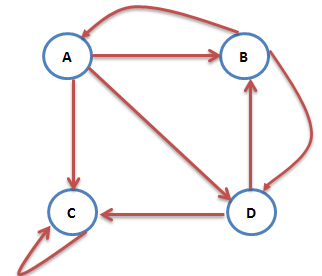

上网者跑到C网页后,就像跳进了陷阱,陷入了漩涡,再也不能从C中出来,将最终导致概率分布值全部转移到C上来,这使得其他网页的概率分布值为0,从而整个网页排名就失去了意义。如果按照上面图对应的转移矩阵为:

不断的迭代下去,就变成了这样:
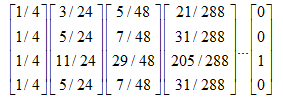
代码如下:
public class PageRank
{
private static double m[][]={
{ 0 , 0.5 , 0 , 0 },
{0.333333333 , 0 , 0 , 0.5},
{0.333333333 , 0 , 1 , 0.5},//此行第三列为1
{0.333333333 , 0.5 , 0 , 0 }
};
private static double v[]={0.25,0.25,0.25,0.25};
private static double v1[]={0,0,0,0};
public static void main(String[] argv)
{
for(int iterater=0;iterater<1000;iterater++)
{
for(int i=0;i<4;i++)
{
for(int j=0;j<4;j++)
{
v1[i]+=m[i][j]*v[j];
}
}
for(int k=0;k<4;k++)
{
v[k]=v1[k];
v1[k]=0;
}
}
for(int k=0;k<4;k++)
{
System.out.println(v[k]);
}
}
}
解决终止点问题和陷阱问题
上面过程,我们忽略了一个问题,那就是上网者是一个悠闲的上网者,而不是一个愚蠢的上网者,我们的上网者是聪明而悠闲,他悠闲,漫无目的,总是随机的选择网页,他聪明,在走到一个终结网页或者一个陷阱网页(比如两个示例中的C),不会傻傻的干着急,他会在浏览器的地址随机输入一个地址,当然这个地址可能又是原来的网页,但这里给了他一个逃离的机会,让他离开这万丈深渊。模拟聪明而又悠闲的上网者,对算法进行改进,每一步,上网者可能都不想看当前网页了,不看当前网页也就不会点击上面的连接,而上悄悄地在地址栏输入另外一个地址,而在地址栏输入而跳转到各个网页的概率是1/n。假设上网者每一步查看当前网页的概率为a,那么他从浏览器地址栏跳转的概率为(1-a),于是原来的迭代公式转化为:
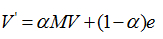
现在我们来计算带陷阱的网页图的概率分布:

重复迭代下去,得到:

可以看到C虽然占了很大一部分pagerank值,但其他网页页获得的一些值,因此C的链接结构,它的权重确实应该会大些。
代码如下:
public class PageRank
{
private static double m[][]={
{ 0 , 0.5 , 0 , 0 },
{0.333333333 , 0 , 0 , 0.5},
{0.333333333 , 0 , 1 , 0.5},
{0.333333333 , 0.5 , 0 , 0 }
};
private static double v[]={0.25,0.25,0.25,0.25};
private static double v1[]={0,0,0,0};
public static void main(String[] argv)
{
for(int iterater=0;iterater<1000;iterater++)
{
for(int i=0;i<4;i++)
{
for(int j=0;j<4;j++)
{
v1[i]+=m[i][j]*v[j];
}
}
for(int k=0;k<4;k++)
{
v[k]=0.8*v1[k]+0.2*0.25;//此处0.2乘的一直都是v[]的初始值
v1[k]=0;
}
}
for(int k=0;k<4;k++)
{
System.out.println(v[k]);
}
}
}
PageRank学习的更多相关文章
- 吴裕雄--天生自然HADOOP学习笔记:hadoop集群实现PageRank算法实验报告
实验课程名称:大数据处理技术 实验项目名称:hadoop集群实现PageRank算法 实验类型:综合性 实验日期:2018年 6 月4日-6月14日 学生姓名 吴裕雄 学号 15210120331 班 ...
- 【Hadoop学习之十一】MapReduce案例分析三-PageRank
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 什么是pagerank?算法原理- ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- 97、PageRank算法学习
最近由于.......你懂得,需要一些搜索方面的知识,于是乎我重新复习了一下上半年读的那本书<数学之美>Dr吴军老师写的. 感觉读完这种书还是写一下比较好,因为将来说不定就会忘记了. 接下 ...
- 【原创】机器学习之PageRank算法应用与C#实现(2)球队排名应用与C#代码
在上一篇文章:机器学习之PageRank算法应用与C#实现(1)算法介绍 中,对PageRank算法的原理和过程进行了详细的介绍,并通过一个很简单的例子对过程进行了讲解.从上一篇文章可以很快的了解Pa ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- Hadoop家族学习路线图--转载
原文地址:http://blog.fens.me/hadoop-family-roadmap/ Sep 6, 2013 Tags: Hadoophadoop familyroadmap Comment ...
- Hadoop应用开发实战(flume应用开发、搜索引擎算法、Pipes、集群、PageRank算法)
Hadoop是2013年最热门的技术之一,通过北风网robby老师<深入浅出Hadoop实战开发>.<Hadoop应用开发实战>两套课程的学习,普通Java开发人员可以在最快的 ...
随机推荐
- 安装 Apache 源代码包
把自己在网易博客的文章迁移过来 cd /lamp/httpd-2.2.9 ./configure --prefix=/usr/local/apache2/ --sysconfdir=/usr/loca ...
- 洛谷P1565牛宫
传送门:题目点这里; 首先理解题目,就是要求给定矩阵中权值和不小于零的最大子矩阵,数据范围200也还不算棘手,暴力n^4的算法也可以水到50分.正解要用到单调栈配合二分和前缀和,复杂度n^3logn, ...
- coreseek mmseg分词配置和创建
1.文件格式为 沃尔沃 1x:1现代 1x:1徐工 1x:1住友 1 ... 3.将生成的符合格式要求的词表粘贴到原词表unigram.txt末尾,保存为unigram_new.txt,并拷贝到mms ...
- luogu P1016 旅行家的预算
题目描述 一个旅行家想驾驶汽车以最少的费用从一个城市到另一个城市(假设出发时油箱是空的).给定两个城市之间的距离D1.汽车油箱的容量C(以升为单位).每升汽油能行驶的距离D2.出发点每升汽油价格P和沿 ...
- [BZOJ5250][九省联考2018]秘密袭击(DP)
5250: [2018多省省队联测]秘密袭击 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 3 Solved: 0[Submit][Status][D ...
- [xsy1232]Magic
题意:一个无向图,每个点有$a_i,b_i$,对任意点$i$你都可以花费$b_i$的费用将$a_i$变为$0$,最后你还要付出$\sum\limits_{i=1}^n\max\limits_{(i,j ...
- Problem C: 零起点学算法82——数组中查找数
#include<stdio.h> int main(void) { ],m; while(scanf("%d",&n)!=EOF) { ;i<n;i++ ...
- centos安装lnmp
安装ssh yum install openssh-server ====================== 查看SSH是否安装. ◆输入命令:rpm -qa | grep ssh 注:若没安装SS ...
- Maven:程序包org.apache.log4j不存在问题处理
<dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> & ...
- XenApp应用虚拟化介绍
https://wenku.baidu.com/view/635223c26137ee06eff91864.html